 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRendering-Aware Reinforcement Learning for Vector Graphics Generation
May 27, 2025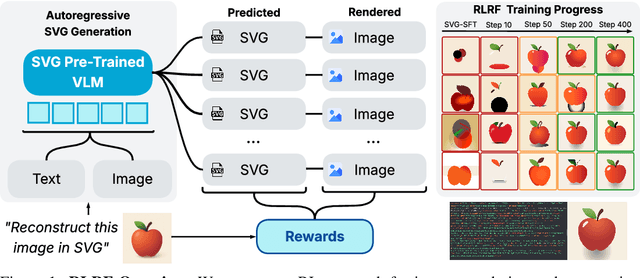
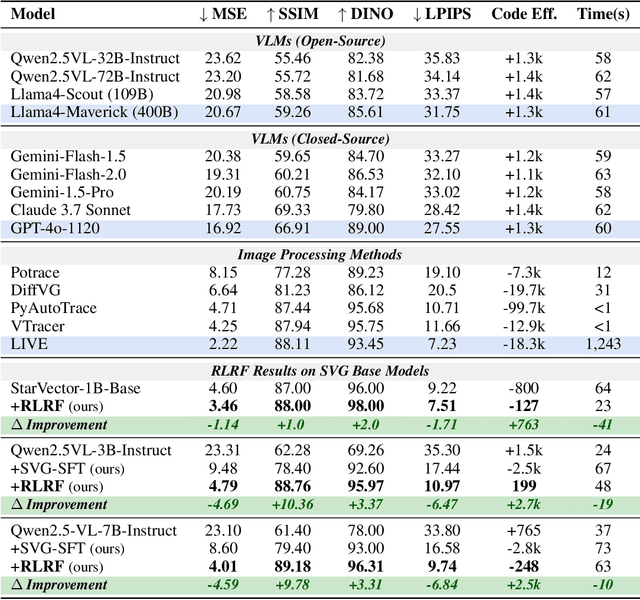
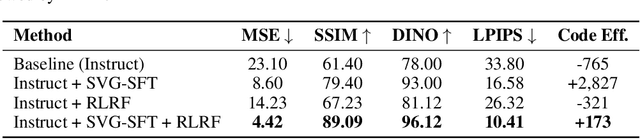
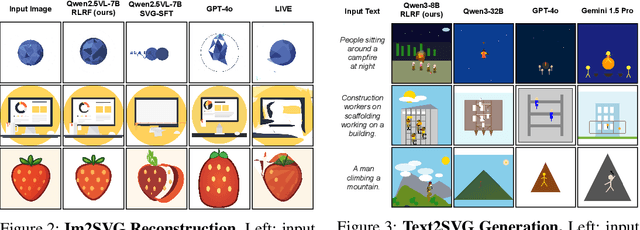
Scalable Vector Graphics (SVG) offer a powerful format for representing visual designs as interpretable code. Recent advances in vision-language models (VLMs) have enabled high-quality SVG generation by framing the problem as a code generation task and leveraging large-scale pretraining. VLMs are particularly suitable for this task as they capture both global semantics and fine-grained visual patterns, while transferring knowledge across vision, natural language, and code domains. However, existing VLM approaches often struggle to produce faithful and efficient SVGs because they never observe the rendered images during training. Although differentiable rendering for autoregressive SVG code generation remains unavailable, rendered outputs can still be compared to original inputs, enabling evaluative feedback suitable for reinforcement learning (RL). We introduce RLRF(Reinforcement Learning from Rendering Feedback), an RL method that enhances SVG generation in autoregressive VLMs by leveraging feedback from rendered SVG outputs. Given an input image, the model generates SVG roll-outs that are rendered and compared to the original image to compute a reward. This visual fidelity feedback guides the model toward producing more accurate, efficient, and semantically coherent SVGs. RLRF significantly outperforms supervised fine-tuning, addressing common failure modes and enabling precise, high-quality SVG generation with strong structural understanding and generalization.
Too Big to Fool: Resisting Deception in Language Models
Dec 13, 2024



Large language models must balance their weight-encoded knowledge with in-context information from prompts to generate accurate responses. This paper investigates this interplay by analyzing how models of varying capacities within the same family handle intentionally misleading in-context information. Our experiments demonstrate that larger models exhibit higher resilience to deceptive prompts, showcasing an advanced ability to interpret and integrate prompt information with their internal knowledge. Furthermore, we find that larger models outperform smaller ones in following legitimate instructions, indicating that their resilience is not due to disregarding in-context information. We also show that this phenomenon is likely not a result of memorization but stems from the models' ability to better leverage implicit task-relevant information from the prompt alongside their internally stored knowledge.
Interpretability in Action: Exploratory Analysis of VPT, a Minecraft Agent
Jul 16, 2024



Understanding the mechanisms behind decisions taken by large foundation models in sequential decision making tasks is critical to ensuring that such systems operate transparently and safely. In this work, we perform exploratory analysis on the Video PreTraining (VPT) Minecraft playing agent, one of the largest open-source vision-based agents. We aim to illuminate its reasoning mechanisms by applying various interpretability techniques. First, we analyze the attention mechanism while the agent solves its training task - crafting a diamond pickaxe. The agent pays attention to the last four frames and several key-frames further back in its six-second memory. This is a possible mechanism for maintaining coherence in a task that takes 3-10 minutes, despite the short memory span. Secondly, we perform various interventions, which help us uncover a worrying case of goal misgeneralization: VPT mistakenly identifies a villager wearing brown clothes as a tree trunk when the villager is positioned stationary under green tree leaves, and punches it to death.
Mastering Memory Tasks with World Models
Mar 07, 2024Current model-based reinforcement learning (MBRL) agents struggle with long-term dependencies. This limits their ability to effectively solve tasks involving extended time gaps between actions and outcomes, or tasks demanding the recalling of distant observations to inform current actions. To improve temporal coherence, we integrate a new family of state space models (SSMs) in world models of MBRL agents to present a new method, Recall to Imagine (R2I). This integration aims to enhance both long-term memory and long-horizon credit assignment. Through a diverse set of illustrative tasks, we systematically demonstrate that R2I not only establishes a new state-of-the-art for challenging memory and credit assignment RL tasks, such as BSuite and POPGym, but also showcases superhuman performance in the complex memory domain of Memory Maze. At the same time, it upholds comparable performance in classic RL tasks, such as Atari and DMC, suggesting the generality of our method. We also show that R2I is faster than the state-of-the-art MBRL method, DreamerV3, resulting in faster wall-time convergence.
Causal Imitative Model for Autonomous Driving
Dec 07, 2021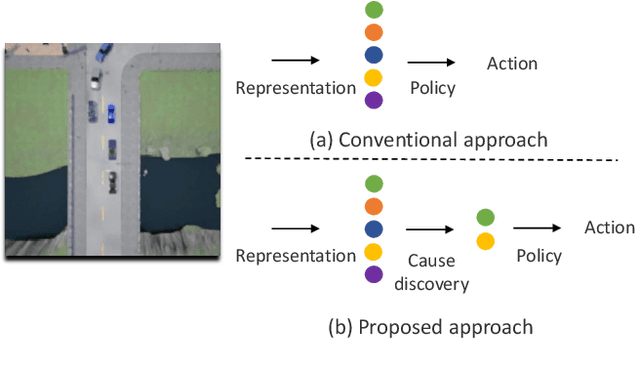
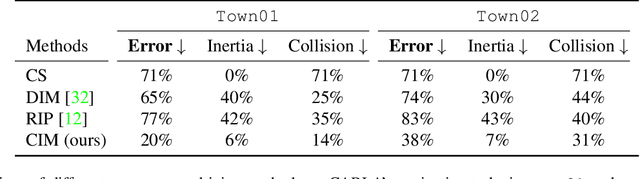
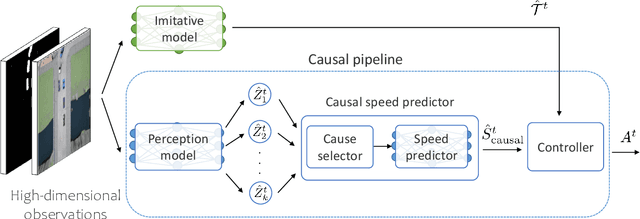

Imitation learning is a powerful approach for learning autonomous driving policy by leveraging data from expert driver demonstrations. However, driving policies trained via imitation learning that neglect the causal structure of expert demonstrations yield two undesirable behaviors: inertia and collision. In this paper, we propose Causal Imitative Model (CIM) to address inertia and collision problems. CIM explicitly discovers the causal model and utilizes it to train the policy. Specifically, CIM disentangles the input to a set of latent variables, selects the causal variables, and determines the next position by leveraging the selected variables. Our experiments show that our method outperforms previous work in terms of inertia and collision rates. Moreover, thanks to exploiting the causal structure, CIM shrinks the input dimension to only two, hence, can adapt to new environments in a few-shot setting. Code is available at https://github.com/vita-epfl/CIM.
Distributed Deep Reinforcement Learning: An Overview
Nov 22, 2020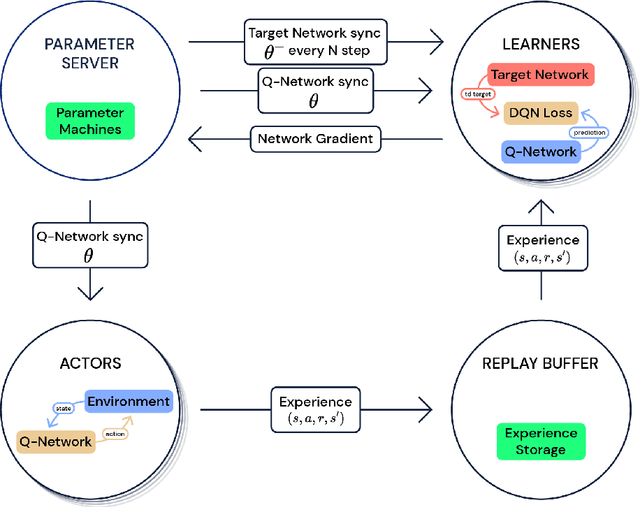
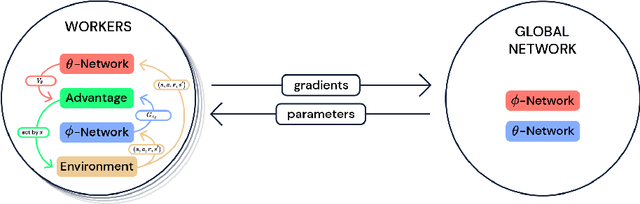
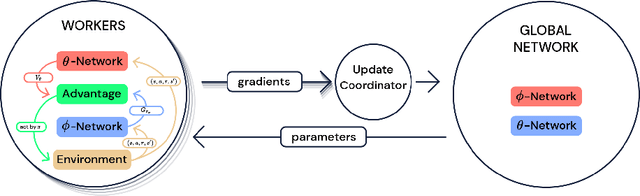
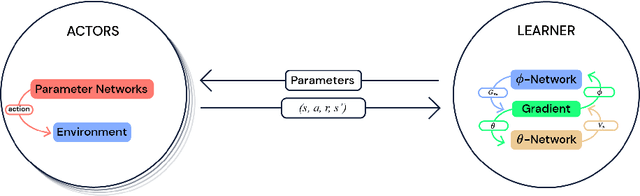
Deep reinforcement learning (DRL) is a very active research area. However, several technical and scientific issues require to be addressed, amongst which we can mention data inefficiency, exploration-exploitation trade-off, and multi-task learning. Therefore, distributed modifications of DRL were introduced; agents that could be run on many machines simultaneously. In this article, we provide a survey of the role of the distributed approaches in DRL. We overview the state of the field, by studying the key research works that have a significant impact on how we can use distributed methods in DRL. We choose to overview these papers, from the perspective of distributed learning, and not the aspect of innovations in reinforcement learning algorithms. Also, we evaluate these methods on different tasks and compare their performance with each other and with single actor and learner agents.
Recognizing Arrow Of Time In The Short Stories
Mar 25, 2019
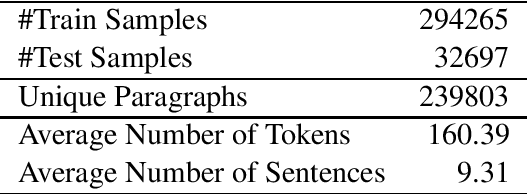

Recognizing arrow of time in short stories is a challenging task. i.e., given only two paragraphs, determining which comes first and which comes next is a difficult task even for humans. In this paper, we have collected and curated a novel dataset for tackling this challenging task. We have shown that a pre-trained BERT architecture achieves reasonable accuracy on the task, and outperforms RNN-based architectures.