 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Deep Reinforcement Learning: An Overview
Paper and Code
Nov 22, 2020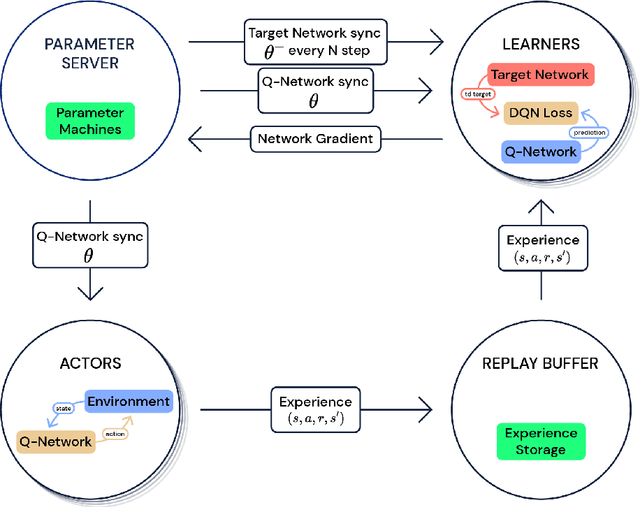
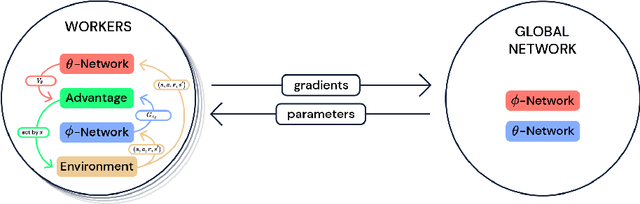
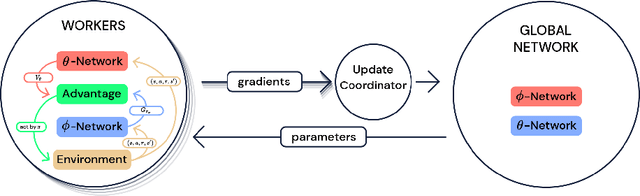
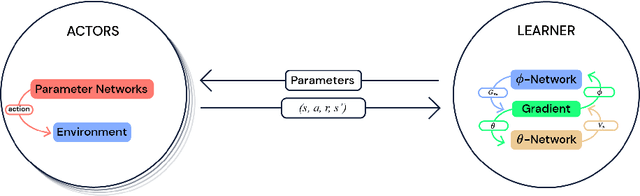
Deep reinforcement learning (DRL) is a very active research area. However, several technical and scientific issues require to be addressed, amongst which we can mention data inefficiency, exploration-exploitation trade-off, and multi-task learning. Therefore, distributed modifications of DRL were introduced; agents that could be run on many machines simultaneously. In this article, we provide a survey of the role of the distributed approaches in DRL. We overview the state of the field, by studying the key research works that have a significant impact on how we can use distributed methods in DRL. We choose to overview these papers, from the perspective of distributed learning, and not the aspect of innovations in reinforcement learning algorithms. Also, we evaluate these methods on different tasks and compare their performance with each other and with single actor and learner agents.