 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartQAPro: A More Diverse and Challenging Benchmark for Chart Question Answering
Apr 10, 2025Charts are ubiquitous, as people often use them to analyze data, answer questions, and discover critical insights. However, performing complex analytical tasks with charts requires significant perceptual and cognitive effort. Chart Question Answering (CQA) systems automate this process by enabling models to interpret and reason with visual representations of data. However, existing benchmarks like ChartQA lack real-world diversity and have recently shown performance saturation with modern large vision-language models (LVLMs). To address these limitations, we introduce ChartQAPro, a new benchmark that includes 1,341 charts from 157 diverse sources, spanning various chart types, including infographics and dashboards, and featuring 1,948 questions in various types, such as multiple-choice, conversational, hypothetical, and unanswerable questions, to better reflect real-world challenges. Our evaluations with 21 models show a substantial performance drop for LVLMs on ChartQAPro; e.g., Claude Sonnet 3.5 scores 90.5% on ChartQA but only 55.81% on ChartQAPro, underscoring the complexity of chart reasoning. We complement our findings with detailed error analyses and ablation studies, identifying key challenges and opportunities for advancing LVLMs in chart understanding and reasoning. We release ChartQAPro at https://github.com/vis-nlp/ChartQAPro.
Too Big to Fool: Resisting Deception in Language Models
Dec 13, 2024Large language models must balance their weight-encoded knowledge with in-context information from prompts to generate accurate responses. This paper investigates this interplay by analyzing how models of varying capacities within the same family handle intentionally misleading in-context information. Our experiments demonstrate that larger models exhibit higher resilience to deceptive prompts, showcasing an advanced ability to interpret and integrate prompt information with their internal knowledge. Furthermore, we find that larger models outperform smaller ones in following legitimate instructions, indicating that their resilience is not due to disregarding in-context information. We also show that this phenomenon is likely not a result of memorization but stems from the models' ability to better leverage implicit task-relevant information from the prompt alongside their internally stored knowledge.
The BrowserGym Ecosystem for Web Agent Research
Dec 10, 2024



The BrowserGym ecosystem addresses the growing need for efficient evaluation and benchmarking of web agents, particularly those leveraging automation and Large Language Models (LLMs) for web interaction tasks. Many existing benchmarks suffer from fragmentation and inconsistent evaluation methodologies, making it challenging to achieve reliable comparisons and reproducible results. BrowserGym aims to solve this by providing a unified, gym-like environment with well-defined observation and action spaces, facilitating standardized evaluation across diverse benchmarks. Combined with AgentLab, a complementary framework that aids in agent creation, testing, and analysis, BrowserGym offers flexibility for integrating new benchmarks while ensuring consistent evaluation and comprehensive experiment management. This standardized approach seeks to reduce the time and complexity of developing web agents, supporting more reliable comparisons and facilitating in-depth analysis of agent behaviors, and could result in more adaptable, capable agents, ultimately accelerating innovation in LLM-driven automation. As a supporting evidence, we conduct the first large-scale, multi-benchmark web agent experiment and compare the performance of 6 state-of-the-art LLMs across all benchmarks currently available in BrowserGym. Among other findings, our results highlight a large discrepancy between OpenAI and Anthropic's latests models, with Claude-3.5-Sonnet leading the way on almost all benchmarks, except on vision-related tasks where GPT-4o is superior. Despite these advancements, our results emphasize that building robust and efficient web agents remains a significant challenge, due to the inherent complexity of real-world web environments and the limitations of current models.
Combining Domain and Alignment Vectors to Achieve Better Knowledge-Safety Trade-offs in LLMs
Nov 11, 2024



There is a growing interest in training domain-expert LLMs that excel in specific technical fields compared to their general-purpose instruction-tuned counterparts. However, these expert models often experience a loss in their safety abilities in the process, making them capable of generating harmful content. As a solution, we introduce an efficient and effective merging-based alignment method called \textsc{MergeAlign} that interpolates the domain and alignment vectors, creating safer domain-specific models while preserving their utility. We apply \textsc{MergeAlign} on Llama3 variants that are experts in medicine and finance, obtaining substantial alignment improvements with minimal to no degradation on domain-specific benchmarks. We study the impact of model merging through model similarity metrics and contributions of individual models being merged. We hope our findings open new research avenues and inspire more efficient development of safe expert LLMs.
WorkArena++: Towards Compositional Planning and Reasoning-based Common Knowledge Work Tasks
Jul 07, 2024



The ability of large language models (LLMs) to mimic human-like intelligence has led to a surge in LLM-based autonomous agents. Though recent LLMs seem capable of planning and reasoning given user instructions, their effectiveness in applying these capabilities for autonomous task solving remains underexplored. This is especially true in enterprise settings, where automated agents hold the promise of a high impact. To fill this gap, we propose WorkArena++, a novel benchmark consisting of 682 tasks corresponding to realistic workflows routinely performed by knowledge workers. WorkArena++ is designed to evaluate the planning, problem-solving, logical/arithmetic reasoning, retrieval, and contextual understanding abilities of web agents. Our empirical studies across state-of-the-art LLMs and vision-language models (VLMs), as well as human workers, reveal several challenges for such models to serve as useful assistants in the workplace. In addition to the benchmark, we provide a mechanism to effortlessly generate thousands of ground-truth observation/action traces, which can be used for fine-tuning existing models. Overall, we expect this work to serve as a useful resource to help the community progress toward capable autonomous agents. The benchmark can be found at https://github.com/ServiceNow/WorkArena/tree/workarena-plus-plus.
ChartGemma: Visual Instruction-tuning for Chart Reasoning in the Wild
Jul 04, 2024



Given the ubiquity of charts as a data analysis, visualization, and decision-making tool across industries and sciences, there has been a growing interest in developing pre-trained foundation models as well as general purpose instruction-tuned models for chart understanding and reasoning. However, existing methods suffer crucial drawbacks across two critical axes affecting the performance of chart representation models: they are trained on data generated from underlying data tables of the charts, ignoring the visual trends and patterns in chart images, and use weakly aligned vision-language backbone models for domain-specific training, limiting their generalizability when encountering charts in the wild. We address these important drawbacks and introduce ChartGemma, a novel chart understanding and reasoning model developed over PaliGemma. Rather than relying on underlying data tables, ChartGemma is trained on instruction-tuning data generated directly from chart images, thus capturing both high-level trends and low-level visual information from a diverse set of charts. Our simple approach achieves state-of-the-art results across $5$ benchmarks spanning chart summarization, question answering, and fact-checking, and our elaborate qualitative studies on real-world charts show that ChartGemma generates more realistic and factually correct summaries compared to its contemporaries. We release the code, model checkpoints, dataset, and demos at https://github.com/vis-nlp/ChartGemma.
A Deep Dive into the Trade-Offs of Parameter-Efficient Preference Alignment Techniques
Jun 07, 2024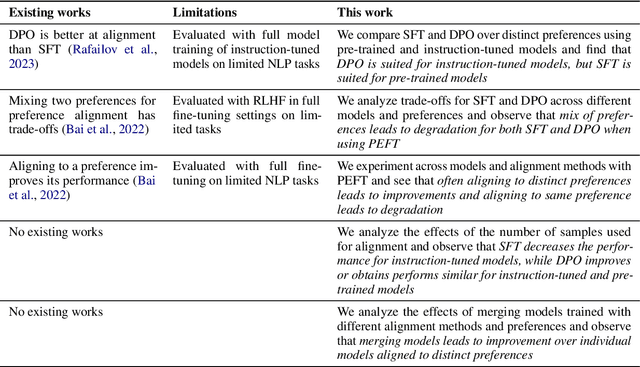
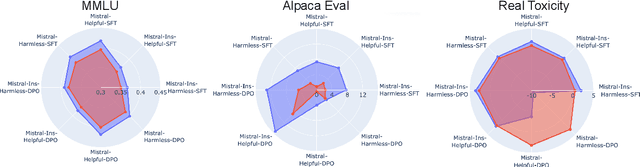
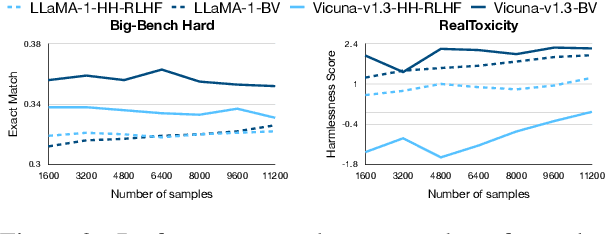
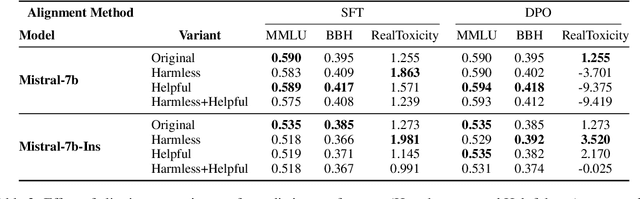
Large language models are first pre-trained on trillions of tokens and then instruction-tuned or aligned to specific preferences. While pre-training remains out of reach for most researchers due to the compute required, fine-tuning has become affordable thanks to parameter-efficient methods such as LoRA and QLoRA. Alignment is known to be sensitive to the many factors involved, including the quantity and quality of data, the alignment method, and the adapter rank. However, there has not yet been an extensive study of their effect on downstream performance. To address this gap, we conduct an in-depth investigation of the impact of popular choices for three crucial axes: (i) the alignment dataset (HH-RLHF and BeaverTails), (ii) the alignment technique (SFT and DPO), and (iii) the model (LLaMA-1, Vicuna-v1.3, Mistral-7b, and Mistral-7b-Instruct). Our extensive setup spanning over 300 experiments reveals consistent trends and unexpected findings. We observe how more informative data helps with preference alignment, cases where supervised fine-tuning outperforms preference optimization, and how aligning to a distinct preference boosts performance on downstream tasks. Through our in-depth analyses, we put forward key guidelines to help researchers perform more effective parameter-efficient LLM alignment.
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Mar 12, 2024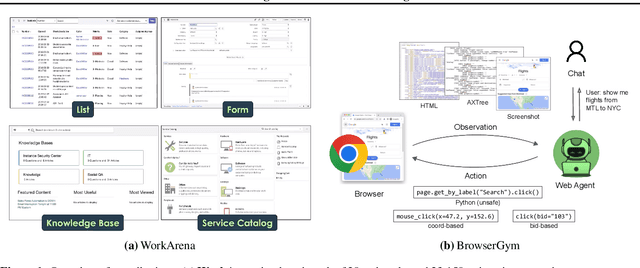
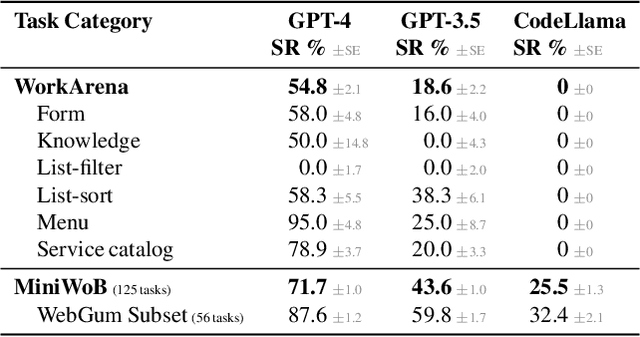

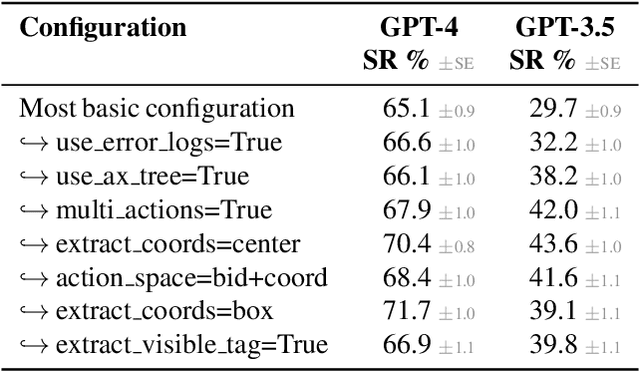
We study the use of large language model-based agents for interacting with software via web browsers. Unlike prior work, we focus on measuring the agents' ability to perform tasks that span the typical daily work of knowledge workers utilizing enterprise software systems. To this end, we propose WorkArena, a remote-hosted benchmark of 29 tasks based on the widely-used ServiceNow platform. We also introduce BrowserGym, an environment for the design and evaluation of such agents, offering a rich set of actions as well as multimodal observations. Our empirical evaluation reveals that while current agents show promise on WorkArena, there remains a considerable gap towards achieving full task automation. Notably, our analysis uncovers a significant performance disparity between open and closed-source LLMs, highlighting a critical area for future exploration and development in the field.
Self-Influence Guided Data Reweighting for Language Model Pre-training
Nov 02, 2023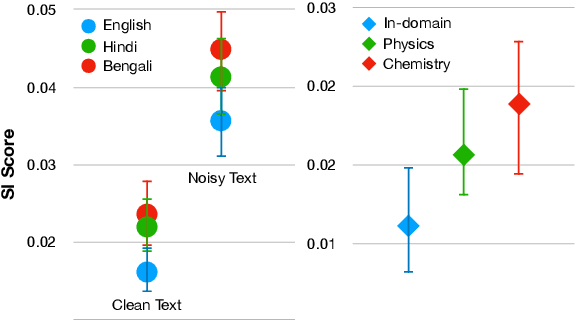
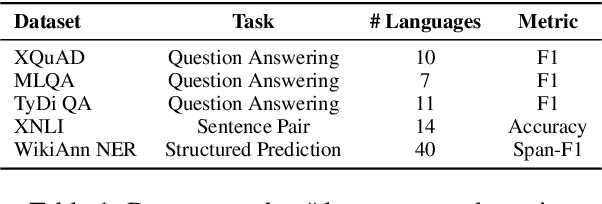
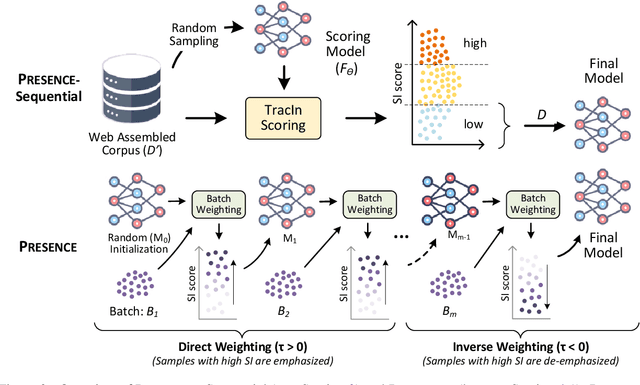
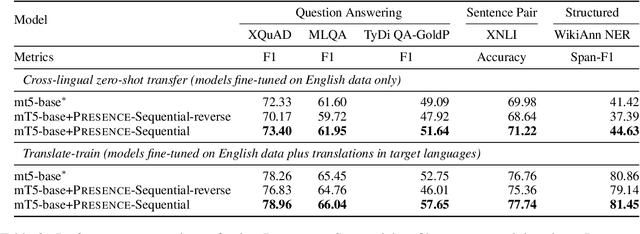
Language Models (LMs) pre-trained with self-supervision on large text corpora have become the default starting point for developing models for various NLP tasks. Once the pre-training corpus has been assembled, all data samples in the corpus are treated with equal importance during LM pre-training. However, due to varying levels of relevance and quality of data, equal importance to all the data samples may not be the optimal choice. While data reweighting has been explored in the context of task-specific supervised learning and LM fine-tuning, model-driven reweighting for pre-training data has not been explored. We fill this important gap and propose PRESENCE, a method for jointly reweighting samples by leveraging self-influence (SI) scores as an indicator of sample importance and pre-training. PRESENCE promotes novelty and stability for model pre-training. Through extensive analysis spanning multiple model sizes, datasets, and tasks, we present PRESENCE as an important first step in the research direction of sample reweighting for pre-training language models.
Randomized Smoothing with Masked Inference for Adversarially Robust Text Classifications
May 11, 2023



Large-scale pre-trained language models have shown outstanding performance in a variety of NLP tasks. However, they are also known to be significantly brittle against specifically crafted adversarial examples, leading to increasing interest in probing the adversarial robustness of NLP systems. We introduce RSMI, a novel two-stage framework that combines randomized smoothing (RS) with masked inference (MI) to improve the adversarial robustness of NLP systems. RS transforms a classifier into a smoothed classifier to obtain robust representations, whereas MI forces a model to exploit the surrounding context of a masked token in an input sequence. RSMI improves adversarial robustness by 2 to 3 times over existing state-of-the-art methods on benchmark datasets. We also perform in-depth qualitative analysis to validate the effectiveness of the different stages of RSMI and probe the impact of its components through extensive ablations. By empirically proving the stability of RSMI, we put it forward as a practical method to robustly train large-scale NLP models. Our code and datasets are available at https://github.com/Han8931/rsmi_nlp