 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Visual Personalization in Vision-Language Models
Feb 03, 2026Despite recent progress in vision-language models (VLMs), existing approaches often fail to generate personalized responses based on the user's specific experiences, as they lack the ability to associate visual inputs with a user's accumulated visual-textual context. We newly formalize this challenge as contextualized visual personalization, which requires the visual recognition and textual retrieval of personalized visual experiences by VLMs when interpreting new images. To address this issue, we propose CoViP, a unified framework that treats personalized image captioning as a core task for contextualized visual personalization and improves this capability through reinforcement-learning-based post-training and caption-augmented generation. We further introduce diagnostic evaluations that explicitly rule out textual shortcut solutions and verify whether VLMs truly leverage visual context. Extensive experiments demonstrate that existing open-source and proprietary VLMs exhibit substantial limitations, while CoViP not only improves personalized image captioning but also yields holistic gains across downstream personalization tasks. These results highlight CoViP as a crucial stage for enabling robust and generalizable contextualized visual personalization.
Randomized Smoothing with Masked Inference for Adversarially Robust Text Classifications
May 11, 2023



Large-scale pre-trained language models have shown outstanding performance in a variety of NLP tasks. However, they are also known to be significantly brittle against specifically crafted adversarial examples, leading to increasing interest in probing the adversarial robustness of NLP systems. We introduce RSMI, a novel two-stage framework that combines randomized smoothing (RS) with masked inference (MI) to improve the adversarial robustness of NLP systems. RS transforms a classifier into a smoothed classifier to obtain robust representations, whereas MI forces a model to exploit the surrounding context of a masked token in an input sequence. RSMI improves adversarial robustness by 2 to 3 times over existing state-of-the-art methods on benchmark datasets. We also perform in-depth qualitative analysis to validate the effectiveness of the different stages of RSMI and probe the impact of its components through extensive ablations. By empirically proving the stability of RSMI, we put it forward as a practical method to robustly train large-scale NLP models. Our code and datasets are available at https://github.com/Han8931/rsmi_nlp
A Unified Neural Coherence Model
Sep 01, 2019
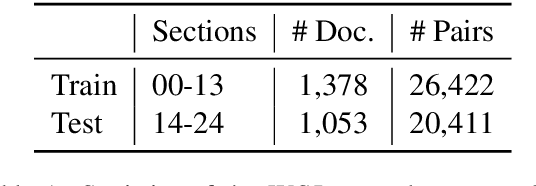
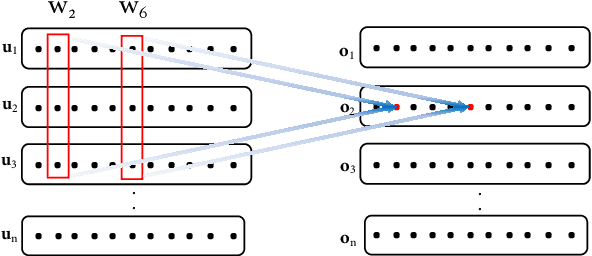
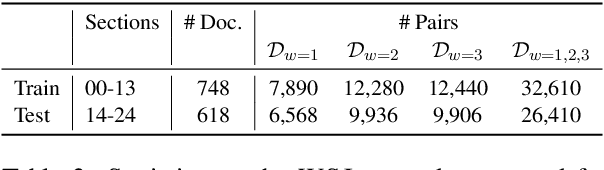
Recently, neural approaches to coherence modeling have achieved state-of-the-art results in several evaluation tasks. However, we show that most of these models often fail on harder tasks with more realistic application scenarios. In particular, the existing models underperform on tasks that require the model to be sensitive to local contexts such as candidate ranking in conversational dialogue and in machine translation. In this paper, we propose a unified coherence model that incorporates sentence grammar, inter-sentence coherence relations, and global coherence patterns into a common neural framework. With extensive experiments on local and global discrimination tasks, we demonstrate that our proposed model outperforms existing models by a good margin, and establish a new state-of-the-art.