 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCANDI: Curated Test-Time Adaptation for Multivariate Time-Series Anomaly Detection Under Distribution Shift
Apr 02, 2026Multivariate time-series anomaly detection (MTSAD) aims to identify deviations from normality in multivariate time-series and is critical in real-world applications. However, in real-world deployments, distribution shifts are ubiquitous and cause severe performance degradation in pre-trained anomaly detector. Test-time adaptation (TTA) updates a pre-trained model on-the-fly using only unlabeled test data, making it promising for addressing this challenge. In this study, we propose CANDI (Curated test-time adaptation for multivariate time-series ANomaly detection under DIstribution shift), a novel TTA framework that selectively identifies and adapts to potential false positives while preserving pre-trained knowledge. CANDI introduces a False Positive Mining (FPM) strategy to curate adaptation samples based on anomaly scores and latent similarity, and incorporates a plug-and-play Spatiotemporally-Aware Normality Adaptation (SANA) module for structurally informed model updates. Extensive experiments demonstrate that CANDI significantly improves the performance of MTSAD under distribution shift, improving AUROC up to 14% while using fewer adaptation samples.
Contextualized Visual Personalization in Vision-Language Models
Feb 03, 2026Despite recent progress in vision-language models (VLMs), existing approaches often fail to generate personalized responses based on the user's specific experiences, as they lack the ability to associate visual inputs with a user's accumulated visual-textual context. We newly formalize this challenge as contextualized visual personalization, which requires the visual recognition and textual retrieval of personalized visual experiences by VLMs when interpreting new images. To address this issue, we propose CoViP, a unified framework that treats personalized image captioning as a core task for contextualized visual personalization and improves this capability through reinforcement-learning-based post-training and caption-augmented generation. We further introduce diagnostic evaluations that explicitly rule out textual shortcut solutions and verify whether VLMs truly leverage visual context. Extensive experiments demonstrate that existing open-source and proprietary VLMs exhibit substantial limitations, while CoViP not only improves personalized image captioning but also yields holistic gains across downstream personalization tasks. These results highlight CoViP as a crucial stage for enabling robust and generalizable contextualized visual personalization.
SAVE: Sparse Autoencoder-Driven Visual Information Enhancement for Mitigating Object Hallucination
Dec 11, 2025Although Multimodal Large Language Models (MLLMs) have advanced substantially, they remain vulnerable to object hallucination caused by language priors and visual information loss. To address this, we propose SAVE (Sparse Autoencoder-Driven Visual Information Enhancement), a framework that mitigates hallucination by steering the model along Sparse Autoencoder (SAE) latent features. A binary object-presence question-answering probe identifies the SAE features most indicative of the model's visual information processing, referred to as visual understanding features. Steering the model along these identified features reinforces grounded visual understanding and effectively reduces hallucination. With its simple design, SAVE outperforms state-of-the-art training-free methods on standard benchmarks, achieving a 10\%p improvement in CHAIR\_S and consistent gains on POPE and MMHal-Bench. Extensive evaluations across multiple models and layers confirm the robustness and generalizability of our approach. Further analysis reveals that steering along visual understanding features suppresses the generation of uncertain object tokens and increases attention to image tokens, mitigating hallucination. Code is released at https://github.com/wiarae/SAVE.
Causality-Aware Contrastive Learning for Robust Multivariate Time-Series Anomaly Detection
Jun 04, 2025Utilizing the complex inter-variable causal relationships within multivariate time-series provides a promising avenue toward more robust and reliable multivariate time-series anomaly detection (MTSAD) but remains an underexplored area of research. This paper proposes Causality-Aware contrastive learning for RObust multivariate Time-Series (CAROTS), a novel MTSAD pipeline that incorporates the notion of causality into contrastive learning. CAROTS employs two data augmentors to obtain causality-preserving and -disturbing samples that serve as a wide range of normal variations and synthetic anomalies, respectively. With causality-preserving and -disturbing samples as positives and negatives, CAROTS performs contrastive learning to train an encoder whose latent space separates normal and abnormal samples based on causality. Moreover, CAROTS introduces a similarity-filtered one-class contrastive loss that encourages the contrastive learning process to gradually incorporate more semantically diverse samples with common causal relationships. Extensive experiments on five real-world and two synthetic datasets validate that the integration of causal relationships endows CAROTS with improved MTSAD capabilities. The code is available at https://github.com/kimanki/CAROTS.
Battling the Non-stationarity in Time Series Forecasting via Test-time Adaptation
Jan 09, 2025



Deep Neural Networks have spearheaded remarkable advancements in time series forecasting (TSF), one of the major tasks in time series modeling. Nonetheless, the non-stationarity of time series undermines the reliability of pre-trained source time series forecasters in mission-critical deployment settings. In this study, we introduce a pioneering test-time adaptation framework tailored for TSF (TSF-TTA). TAFAS, the proposed approach to TSF-TTA, flexibly adapts source forecasters to continuously shifting test distributions while preserving the core semantic information learned during pre-training. The novel utilization of partially-observed ground truth and gated calibration module enables proactive, robust, and model-agnostic adaptation of source forecasters. Experiments on diverse benchmark datasets and cutting-edge architectures demonstrate the efficacy and generality of TAFAS, especially in long-term forecasting scenarios that suffer from significant distribution shifts. The code is available at https://github.com/kimanki/TAFAS.
Superpixel Tokenization for Vision Transformers: Preserving Semantic Integrity in Visual Tokens
Dec 06, 2024



Transformers, a groundbreaking architecture proposed for Natural Language Processing (NLP), have also achieved remarkable success in Computer Vision. A cornerstone of their success lies in the attention mechanism, which models relationships among tokens. While the tokenization process in NLP inherently ensures that a single token does not contain multiple semantics, the tokenization of Vision Transformer (ViT) utilizes tokens from uniformly partitioned square image patches, which may result in an arbitrary mixing of visual concepts in a token. In this work, we propose to substitute the grid-based tokenization in ViT with superpixel tokenization, which employs superpixels to generate a token that encapsulates a sole visual concept. Unfortunately, the diverse shapes, sizes, and locations of superpixels make integrating superpixels into ViT tokenization rather challenging. Our tokenization pipeline, comprised of pre-aggregate extraction and superpixel-aware aggregation, overcomes the challenges that arise in superpixel tokenization. Extensive experiments demonstrate that our approach, which exhibits strong compatibility with existing frameworks, enhances the accuracy and robustness of ViT on various downstream tasks.
Textual Training for the Hassle-Free Removal of Unwanted Visual Data
Sep 30, 2024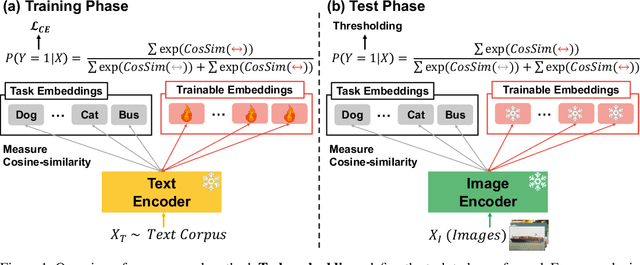
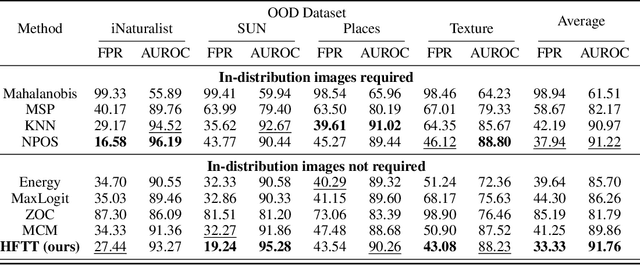
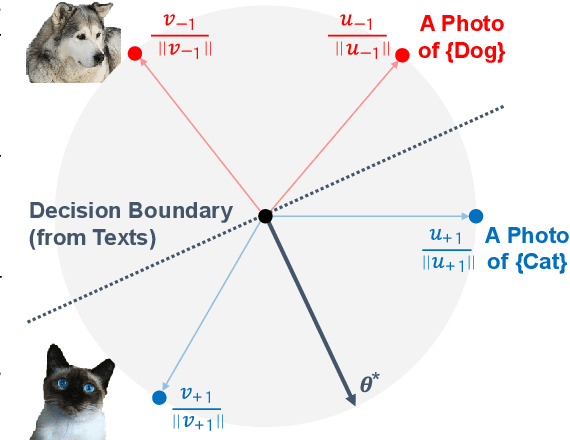
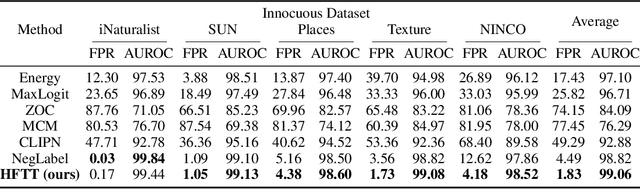
In our study, we explore methods for detecting unwanted content lurking in visual datasets. We provide a theoretical analysis demonstrating that a model capable of successfully partitioning visual data can be obtained using only textual data. Based on the analysis, we propose Hassle-Free Textual Training (HFTT), a streamlined method capable of acquiring detectors for unwanted visual content, using only synthetic textual data in conjunction with pre-trained vision-language models. HFTT features an innovative objective function that significantly reduces the necessity for human involvement in data annotation. Furthermore, HFTT employs a clever textual data synthesis method, effectively emulating the integration of unknown visual data distribution into the training process at no extra cost. The unique characteristics of HFTT extend its utility beyond traditional out-of-distribution detection, making it applicable to tasks that address more abstract concepts. We complement our analyses with experiments in out-of-distribution detection and hateful image detection. Our codes are available at https://github.com/Saehyung-Lee/HFTT
Self-Supervised Time-Series Anomaly Detection Using Learnable Data Augmentation
Jun 18, 2024Continuous efforts are being made to advance anomaly detection in various manufacturing processes to increase the productivity and safety of industrial sites. Deep learning replaced rule-based methods and recently emerged as a promising method for anomaly detection in diverse industries. However, in the real world, the scarcity of abnormal data and difficulties in obtaining labeled data create limitations in the training of detection models. In this study, we addressed these shortcomings by proposing a learnable data augmentation-based time-series anomaly detection (LATAD) technique that is trained in a self-supervised manner. LATAD extracts discriminative features from time-series data through contrastive learning. At the same time, learnable data augmentation produces challenging negative samples to enhance learning efficiency. We measured anomaly scores of the proposed technique based on latent feature similarities. As per the results, LATAD exhibited comparable or improved performance to the state-of-the-art anomaly detection assessments on several benchmark datasets and provided a gradient-based diagnosis technique to help identify root causes.
On the Powerfulness of Textual Outlier Exposure for Visual OoD Detection
Oct 25, 2023Successful detection of Out-of-Distribution (OoD) data is becoming increasingly important to ensure safe deployment of neural networks. One of the main challenges in OoD detection is that neural networks output overconfident predictions on OoD data, make it difficult to determine OoD-ness of data solely based on their predictions. Outlier exposure addresses this issue by introducing an additional loss that encourages low-confidence predictions on OoD data during training. While outlier exposure has shown promising potential in improving OoD detection performance, all previous studies on outlier exposure have been limited to utilizing visual outliers. Drawing inspiration from the recent advancements in vision-language pre-training, this paper venture out to the uncharted territory of textual outlier exposure. First, we uncover the benefits of using textual outliers by replacing real or virtual outliers in the image-domain with textual equivalents. Then, we propose various ways of generating preferable textual outliers. Our extensive experiments demonstrate that generated textual outliers achieve competitive performance on large-scale OoD and hard OoD benchmarks. Furthermore, we conduct empirical analyses of textual outliers to provide primary criteria for designing advantageous textual outliers: near-distribution, descriptiveness, and inclusion of visual semantics.
Anti-Adversarially Manipulated Attributions for Weakly Supervised Semantic Segmentation and Object Localization
Apr 11, 2022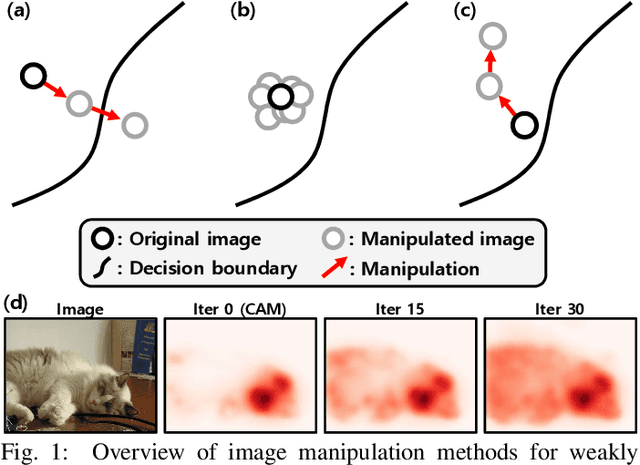
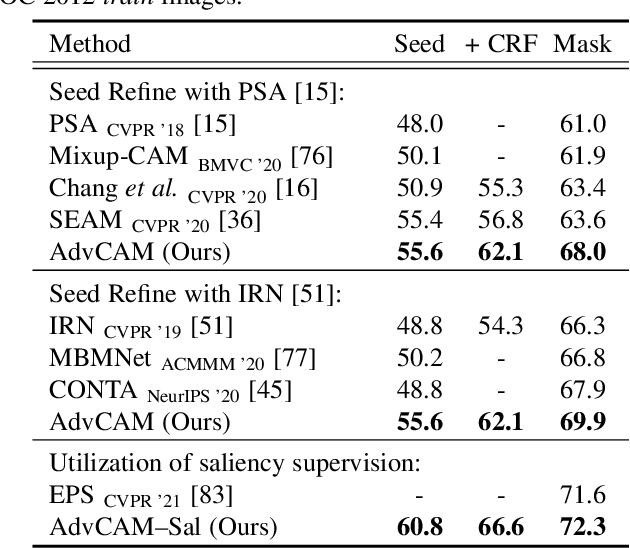
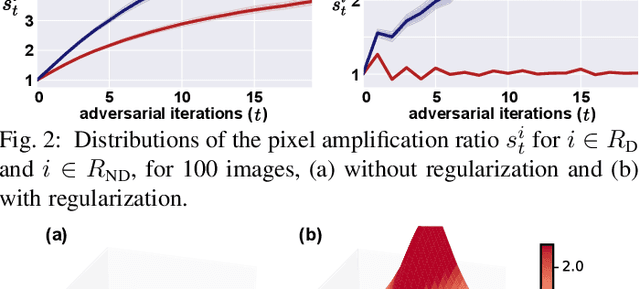

Obtaining accurate pixel-level localization from class labels is a crucial process in weakly supervised semantic segmentation and object localization. Attribution maps from a trained classifier are widely used to provide pixel-level localization, but their focus tends to be restricted to a small discriminative region of the target object. An AdvCAM is an attribution map of an image that is manipulated to increase the classification score produced by a classifier before the final softmax or sigmoid layer. This manipulation is realized in an anti-adversarial manner, so that the original image is perturbed along pixel gradients in directions opposite to those used in an adversarial attack. This process enhances non-discriminative yet class-relevant features, which make an insufficient contribution to previous attribution maps, so that the resulting AdvCAM identifies more regions of the target object. In addition, we introduce a new regularization procedure that inhibits the incorrect attribution of regions unrelated to the target object and the excessive concentration of attributions on a small region of the target object. Our method achieves a new state-of-the-art performance in weakly and semi-supervised semantic segmentation, on both the PASCAL VOC 2012 and MS COCO 2014 datasets. In weakly supervised object localization, it achieves a new state-of-the-art performance on the CUB-200-2011 and ImageNet-1K datasets.