 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality-Aware Contrastive Learning for Robust Multivariate Time-Series Anomaly Detection
Jun 04, 2025Utilizing the complex inter-variable causal relationships within multivariate time-series provides a promising avenue toward more robust and reliable multivariate time-series anomaly detection (MTSAD) but remains an underexplored area of research. This paper proposes Causality-Aware contrastive learning for RObust multivariate Time-Series (CAROTS), a novel MTSAD pipeline that incorporates the notion of causality into contrastive learning. CAROTS employs two data augmentors to obtain causality-preserving and -disturbing samples that serve as a wide range of normal variations and synthetic anomalies, respectively. With causality-preserving and -disturbing samples as positives and negatives, CAROTS performs contrastive learning to train an encoder whose latent space separates normal and abnormal samples based on causality. Moreover, CAROTS introduces a similarity-filtered one-class contrastive loss that encourages the contrastive learning process to gradually incorporate more semantically diverse samples with common causal relationships. Extensive experiments on five real-world and two synthetic datasets validate that the integration of causal relationships endows CAROTS with improved MTSAD capabilities. The code is available at https://github.com/kimanki/CAROTS.
Superpixel Tokenization for Vision Transformers: Preserving Semantic Integrity in Visual Tokens
Dec 06, 2024



Transformers, a groundbreaking architecture proposed for Natural Language Processing (NLP), have also achieved remarkable success in Computer Vision. A cornerstone of their success lies in the attention mechanism, which models relationships among tokens. While the tokenization process in NLP inherently ensures that a single token does not contain multiple semantics, the tokenization of Vision Transformer (ViT) utilizes tokens from uniformly partitioned square image patches, which may result in an arbitrary mixing of visual concepts in a token. In this work, we propose to substitute the grid-based tokenization in ViT with superpixel tokenization, which employs superpixels to generate a token that encapsulates a sole visual concept. Unfortunately, the diverse shapes, sizes, and locations of superpixels make integrating superpixels into ViT tokenization rather challenging. Our tokenization pipeline, comprised of pre-aggregate extraction and superpixel-aware aggregation, overcomes the challenges that arise in superpixel tokenization. Extensive experiments demonstrate that our approach, which exhibits strong compatibility with existing frameworks, enhances the accuracy and robustness of ViT on various downstream tasks.
Unsupervised Homography Estimation on Multimodal Image Pair via Alternating Optimization
Nov 20, 2024


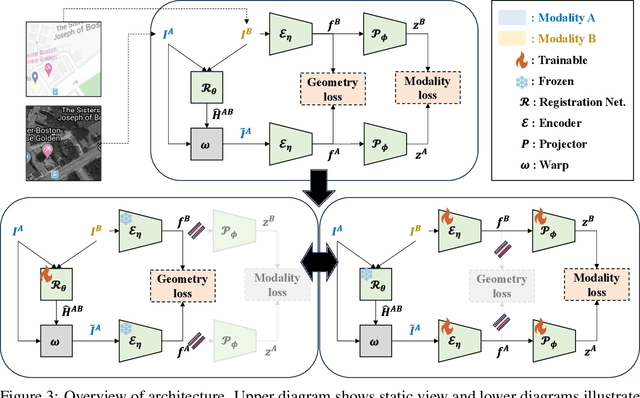
Estimating the homography between two images is crucial for mid- or high-level vision tasks, such as image stitching and fusion. However, using supervised learning methods is often challenging or costly due to the difficulty of collecting ground-truth data. In response, unsupervised learning approaches have emerged. Most early methods, though, assume that the given image pairs are from the same camera or have minor lighting differences. Consequently, while these methods perform effectively under such conditions, they generally fail when input image pairs come from different domains, referred to as multimodal image pairs. To address these limitations, we propose AltO, an unsupervised learning framework for estimating homography in multimodal image pairs. Our method employs a two-phase alternating optimization framework, similar to Expectation-Maximization (EM), where one phase reduces the geometry gap and the other addresses the modality gap. To handle these gaps, we use Barlow Twins loss for the modality gap and propose an extended version, Geometry Barlow Twins, for the geometry gap. As a result, we demonstrate that our method, AltO, can be trained on multimodal datasets without any ground-truth data. It not only outperforms other unsupervised methods but is also compatible with various architectures of homography estimators. The source code can be found at:~\url{https://github.com/songsang7/AltO}
Disentangled Motion Modeling for Video Frame Interpolation
Jun 25, 2024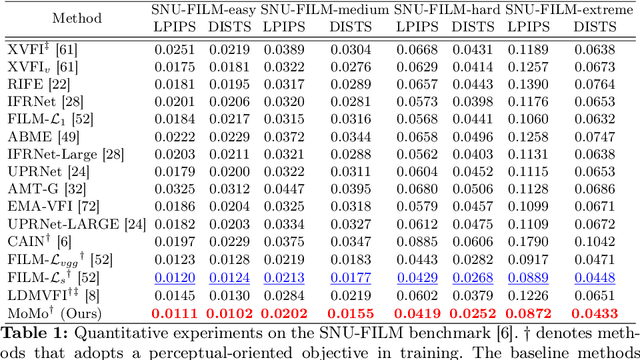
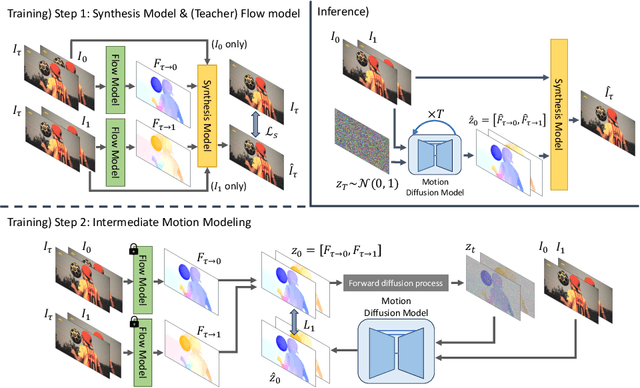

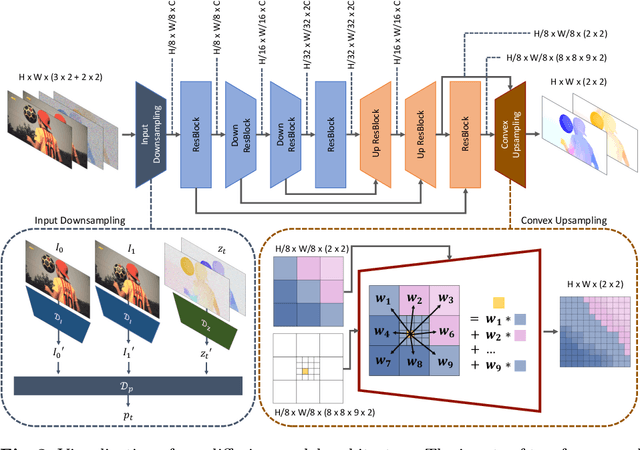
Video frame interpolation (VFI) aims to synthesize intermediate frames in between existing frames to enhance visual smoothness and quality. Beyond the conventional methods based on the reconstruction loss, recent works employ the high quality generative models for perceptual quality. However, they require complex training and large computational cost for modeling on the pixel space. In this paper, we introduce disentangled Motion Modeling (MoMo), a diffusion-based approach for VFI that enhances visual quality by focusing on intermediate motion modeling. We propose disentangled two-stage training process, initially training a frame synthesis model to generate frames from input pairs and their optical flows. Subsequently, we propose a motion diffusion model, equipped with our novel diffusion U-Net architecture designed for optical flow, to produce bi-directional flows between frames. This method, by leveraging the simpler low-frequency representation of motions, achieves superior perceptual quality with reduced computational demands compared to generative modeling methods on the pixel space. Our method surpasses state-of-the-art methods in perceptual metrics across various benchmarks, demonstrating its efficacy and efficiency in VFI. Our code is available at: https://github.com/JHLew/MoMo
PUCA: Patch-Unshuffle and Channel Attention for Enhanced Self-Supervised Image Denoising
Oct 16, 2023Although supervised image denoising networks have shown remarkable performance on synthesized noisy images, they often fail in practice due to the difference between real and synthesized noise. Since clean-noisy image pairs from the real world are extremely costly to gather, self-supervised learning, which utilizes noisy input itself as a target, has been studied. To prevent a self-supervised denoising model from learning identical mapping, each output pixel should not be influenced by its corresponding input pixel; This requirement is known as J-invariance. Blind-spot networks (BSNs) have been a prevalent choice to ensure J-invariance in self-supervised image denoising. However, constructing variations of BSNs by injecting additional operations such as downsampling can expose blinded information, thereby violating J-invariance. Consequently, convolutions designed specifically for BSNs have been allowed only, limiting architectural flexibility. To overcome this limitation, we propose PUCA, a novel J-invariant U-Net architecture, for self-supervised denoising. PUCA leverages patch-unshuffle/shuffle to dramatically expand receptive fields while maintaining J-invariance and dilated attention blocks (DABs) for global context incorporation. Experimental results demonstrate that PUCA achieves state-of-the-art performance, outperforming existing methods in self-supervised image denoising.