 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForestSplats: Deformable transient field for Gaussian Splatting in the Wild
Mar 08, 2025Recently, 3D Gaussian Splatting (3D-GS) has emerged, showing real-time rendering speeds and high-quality results in static scenes. Although 3D-GS shows effectiveness in static scenes, their performance significantly degrades in real-world environments due to transient objects, lighting variations, and diverse levels of occlusion. To tackle this, existing methods estimate occluders or transient elements by leveraging pre-trained models or integrating additional transient field pipelines. However, these methods still suffer from two defects: 1) Using semantic features from the Vision Foundation model (VFM) causes additional computational costs. 2) The transient field requires significant memory to handle transient elements with per-view Gaussians and struggles to define clear boundaries for occluders, solely relying on photometric errors. To address these problems, we propose ForestSplats, a novel approach that leverages the deformable transient field and a superpixel-aware mask to efficiently represent transient elements in the 2D scene across unconstrained image collections and effectively decompose static scenes from transient distractors without VFM. We designed the transient field to be deformable, capturing per-view transient elements. Furthermore, we introduce a superpixel-aware mask that clearly defines the boundaries of occluders by considering photometric errors and superpixels. Additionally, we propose uncertainty-aware densification to avoid generating Gaussians within the boundaries of occluders during densification. Through extensive experiments across several benchmark datasets, we demonstrate that ForestSplats outperforms existing methods without VFM and shows significant memory efficiency in representing transient elements.
Battling the Non-stationarity in Time Series Forecasting via Test-time Adaptation
Jan 09, 2025



Deep Neural Networks have spearheaded remarkable advancements in time series forecasting (TSF), one of the major tasks in time series modeling. Nonetheless, the non-stationarity of time series undermines the reliability of pre-trained source time series forecasters in mission-critical deployment settings. In this study, we introduce a pioneering test-time adaptation framework tailored for TSF (TSF-TTA). TAFAS, the proposed approach to TSF-TTA, flexibly adapts source forecasters to continuously shifting test distributions while preserving the core semantic information learned during pre-training. The novel utilization of partially-observed ground truth and gated calibration module enables proactive, robust, and model-agnostic adaptation of source forecasters. Experiments on diverse benchmark datasets and cutting-edge architectures demonstrate the efficacy and generality of TAFAS, especially in long-term forecasting scenarios that suffer from significant distribution shifts. The code is available at https://github.com/kimanki/TAFAS.
Superpixel Tokenization for Vision Transformers: Preserving Semantic Integrity in Visual Tokens
Dec 06, 2024



Transformers, a groundbreaking architecture proposed for Natural Language Processing (NLP), have also achieved remarkable success in Computer Vision. A cornerstone of their success lies in the attention mechanism, which models relationships among tokens. While the tokenization process in NLP inherently ensures that a single token does not contain multiple semantics, the tokenization of Vision Transformer (ViT) utilizes tokens from uniformly partitioned square image patches, which may result in an arbitrary mixing of visual concepts in a token. In this work, we propose to substitute the grid-based tokenization in ViT with superpixel tokenization, which employs superpixels to generate a token that encapsulates a sole visual concept. Unfortunately, the diverse shapes, sizes, and locations of superpixels make integrating superpixels into ViT tokenization rather challenging. Our tokenization pipeline, comprised of pre-aggregate extraction and superpixel-aware aggregation, overcomes the challenges that arise in superpixel tokenization. Extensive experiments demonstrate that our approach, which exhibits strong compatibility with existing frameworks, enhances the accuracy and robustness of ViT on various downstream tasks.
Unlocking Intrinsic Fairness in Stable Diffusion
Aug 22, 2024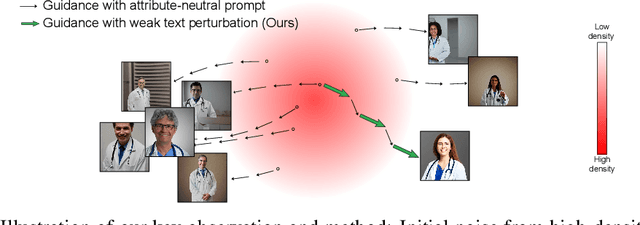



Recent text-to-image models like Stable Diffusion produce photo-realistic images but often show demographic biases. Previous debiasing methods focused on training-based approaches, failing to explore the root causes of bias and overlooking Stable Diffusion's potential for unbiased image generation. In this paper, we demonstrate that Stable Diffusion inherently possesses fairness, which can be unlocked to achieve debiased outputs. Through carefully designed experiments, we identify the excessive bonding between text prompts and the diffusion process as a key source of bias. To address this, we propose a novel approach that perturbs text conditions to unleash Stable Diffusion's intrinsic fairness. Our method effectively mitigates bias without additional tuning, while preserving image-text alignment and image quality.
GrounDial: Human-norm Grounded Safe Dialog Response Generation
Feb 14, 2024



Current conversational AI systems based on large language models (LLMs) are known to generate unsafe responses, agreeing to offensive user input or including toxic content. Previous research aimed to alleviate the toxicity, by fine-tuning LLM with manually annotated safe dialogue histories. However, the dependency on additional tuning requires substantial costs. To remove the dependency, we propose GrounDial, where response safety is achieved by grounding responses to commonsense social rules without requiring fine-tuning. A hybrid approach of in-context learning and human-norm-guided decoding of GrounDial enables the response to be quantitatively and qualitatively safer even without additional data or tuning.
ProPILE: Probing Privacy Leakage in Large Language Models
Jul 04, 2023



The rapid advancement and widespread use of large language models (LLMs) have raised significant concerns regarding the potential leakage of personally identifiable information (PII). These models are often trained on vast quantities of web-collected data, which may inadvertently include sensitive personal data. This paper presents ProPILE, a novel probing tool designed to empower data subjects, or the owners of the PII, with awareness of potential PII leakage in LLM-based services. ProPILE lets data subjects formulate prompts based on their own PII to evaluate the level of privacy intrusion in LLMs. We demonstrate its application on the OPT-1.3B model trained on the publicly available Pile dataset. We show how hypothetical data subjects may assess the likelihood of their PII being included in the Pile dataset being revealed. ProPILE can also be leveraged by LLM service providers to effectively evaluate their own levels of PII leakage with more powerful prompts specifically tuned for their in-house models. This tool represents a pioneering step towards empowering the data subjects for their awareness and control over their own data on the web.
Probabilistic Concept Bottleneck Models
Jun 02, 2023Interpretable models are designed to make decisions in a human-interpretable manner. Representatively, Concept Bottleneck Models (CBM) follow a two-step process of concept prediction and class prediction based on the predicted concepts. CBM provides explanations with high-level concepts derived from concept predictions; thus, reliable concept predictions are important for trustworthiness. In this study, we address the ambiguity issue that can harm reliability. While the existence of a concept can often be ambiguous in the data, CBM predicts concepts deterministically without considering this ambiguity. To provide a reliable interpretation against this ambiguity, we propose Probabilistic Concept Bottleneck Models (ProbCBM). By leveraging probabilistic concept embeddings, ProbCBM models uncertainty in concept prediction and provides explanations based on the concept and its corresponding uncertainty. This uncertainty enhances the reliability of the explanations. Furthermore, as class uncertainty is derived from concept uncertainty in ProbCBM, we can explain class uncertainty by means of concept uncertainty. Code is publicly available at https://github.com/ejkim47/prob-cbm.
On the Impact of Knowledge Distillation for Model Interpretability
May 25, 2023
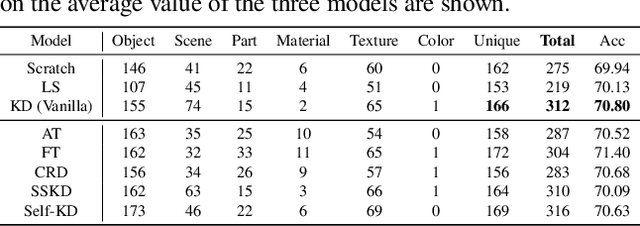

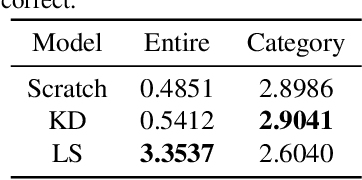
Several recent studies have elucidated why knowledge distillation (KD) improves model performance. However, few have researched the other advantages of KD in addition to its improving model performance. In this study, we have attempted to show that KD enhances the interpretability as well as the accuracy of models. We measured the number of concept detectors identified in network dissection for a quantitative comparison of model interpretability. We attributed the improvement in interpretability to the class-similarity information transferred from the teacher to student models. First, we confirmed the transfer of class-similarity information from the teacher to student model via logit distillation. Then, we analyzed how class-similarity information affects model interpretability in terms of its presence or absence and degree of similarity information. We conducted various quantitative and qualitative experiments and examined the results on different datasets, different KD methods, and according to different measures of interpretability. Our research showed that KD models by large models could be used more reliably in various fields.
Grounding Visual Representations with Texts for Domain Generalization
Jul 21, 2022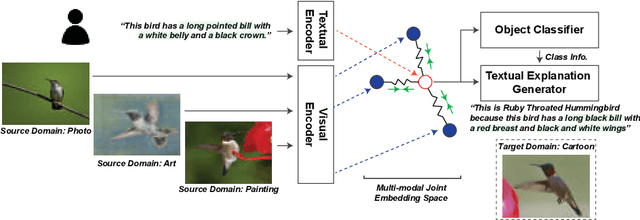
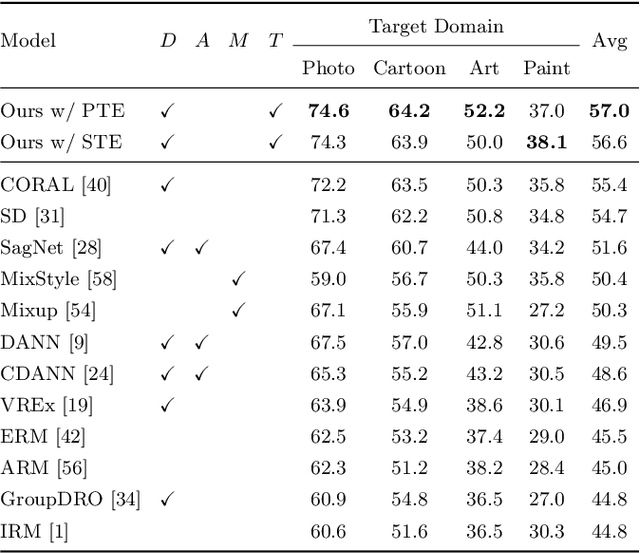
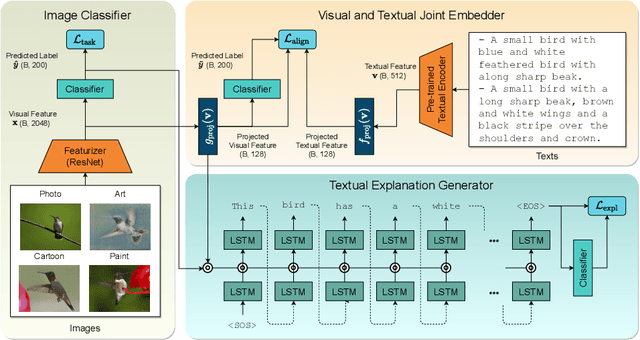
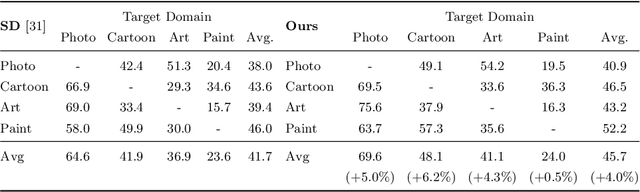
Reducing the representational discrepancy between source and target domains is a key component to maximize the model generalization. In this work, we advocate for leveraging natural language supervision for the domain generalization task. We introduce two modules to ground visual representations with texts containing typical reasoning of humans: (1) Visual and Textual Joint Embedder and (2) Textual Explanation Generator. The former learns the image-text joint embedding space where we can ground high-level class-discriminative information into the model. The latter leverages an explainable model and generates explanations justifying the rationale behind its decision. To the best of our knowledge, this is the first work to leverage the vision-and-language cross-modality approach for the domain generalization task. Our experiments with a newly created CUB-DG benchmark dataset demonstrate that cross-modality supervision can be successfully used to ground domain-invariant visual representations and improve the model generalization. Furthermore, in the large-scale DomainBed benchmark, our proposed method achieves state-of-the-art results and ranks 1st in average performance for five multi-domain datasets. The dataset and codes are available at https://github.com/mswzeus/GVRT.
Bridging the Gap between Classification and Localization for Weakly Supervised Object Localization
Apr 01, 2022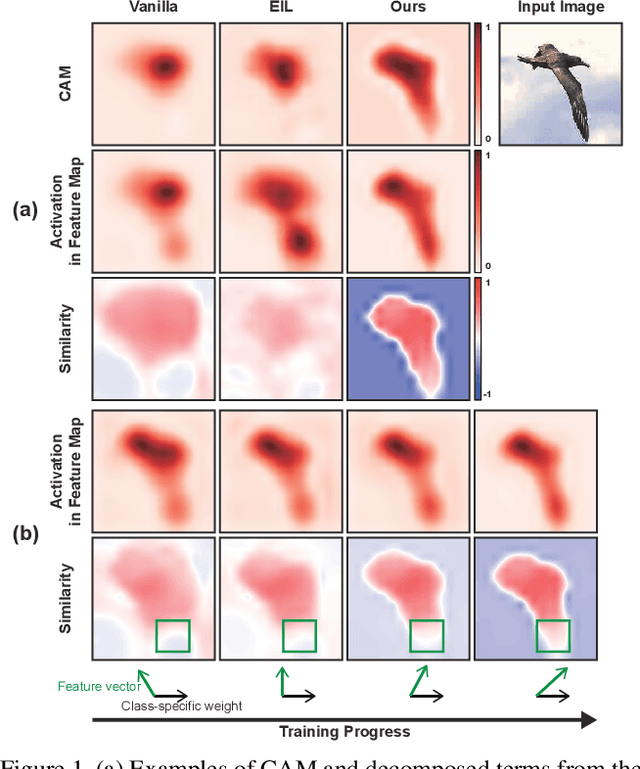
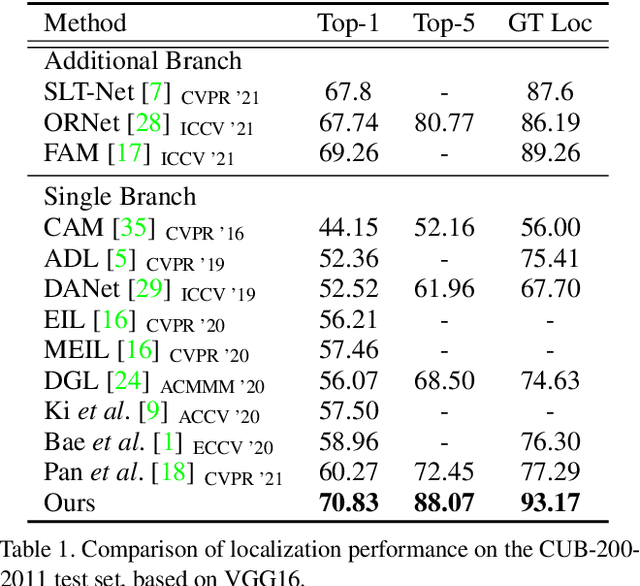
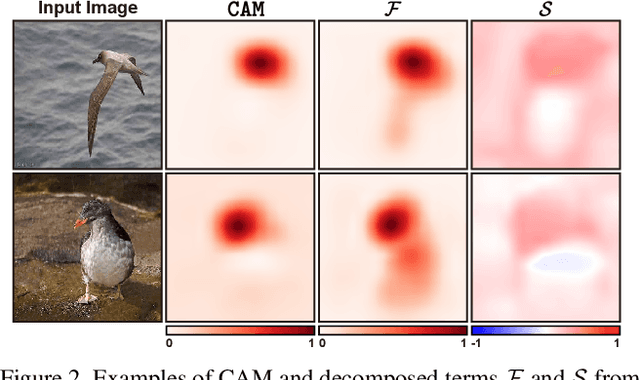
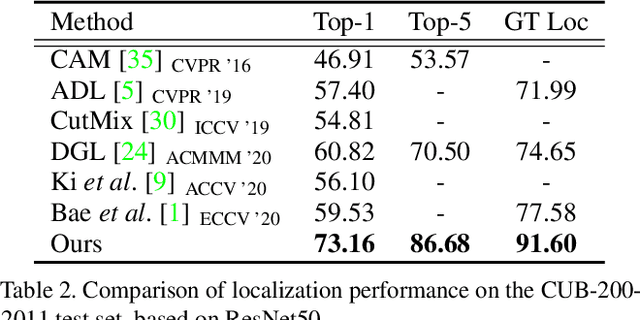
Weakly supervised object localization aims to find a target object region in a given image with only weak supervision, such as image-level labels. Most existing methods use a class activation map (CAM) to generate a localization map; however, a CAM identifies only the most discriminative parts of a target object rather than the entire object region. In this work, we find the gap between classification and localization in terms of the misalignment of the directions between an input feature and a class-specific weight. We demonstrate that the misalignment suppresses the activation of CAM in areas that are less discriminative but belong to the target object. To bridge the gap, we propose a method to align feature directions with a class-specific weight. The proposed method achieves a state-of-the-art localization performance on the CUB-200-2011 and ImageNet-1K benchmarks.