 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Impact of Knowledge Distillation for Model Interpretability
May 25, 2023
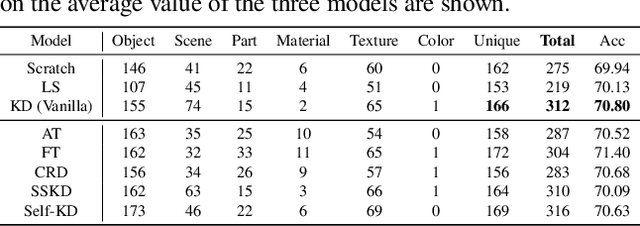

Several recent studies have elucidated why knowledge distillation (KD) improves model performance. However, few have researched the other advantages of KD in addition to its improving model performance. In this study, we have attempted to show that KD enhances the interpretability as well as the accuracy of models. We measured the number of concept detectors identified in network dissection for a quantitative comparison of model interpretability. We attributed the improvement in interpretability to the class-similarity information transferred from the teacher to student models. First, we confirmed the transfer of class-similarity information from the teacher to student model via logit distillation. Then, we analyzed how class-similarity information affects model interpretability in terms of its presence or absence and degree of similarity information. We conducted various quantitative and qualitative experiments and examined the results on different datasets, different KD methods, and according to different measures of interpretability. Our research showed that KD models by large models could be used more reliably in various fields.
Higher-order Neural Additive Models: An Interpretable Machine Learning Model with Feature Interactions
Sep 30, 2022


Black-box models, such as deep neural networks, exhibit superior predictive performances, but understanding their behavior is notoriously difficult. Many explainable artificial intelligence methods have been proposed to reveal the decision-making processes of black box models. However, their applications in high-stakes domains remain limited. Recently proposed neural additive models (NAM) have achieved state-of-the-art interpretable machine learning. NAM can provide straightforward interpretations with slight performance sacrifices compared with multi-layer perceptron. However, NAM can only model 1$^{\text{st}}$-order feature interactions; thus, it cannot capture the co-relationships between input features. To overcome this problem, we propose a novel interpretable machine learning method called higher-order neural additive models (HONAM) and a feature interaction method for high interpretability. HONAM can model arbitrary orders of feature interactions. Therefore, it can provide the high predictive performance and interpretability that high-stakes domains need. In addition, we propose a novel hidden unit to effectively learn sharp-shape functions. We conducted experiments using various real-world datasets to examine the effectiveness of HONAM. Furthermore, we demonstrate that HONAM can achieve fair AI with a slight performance sacrifice. The source code for HONAM is publicly available.
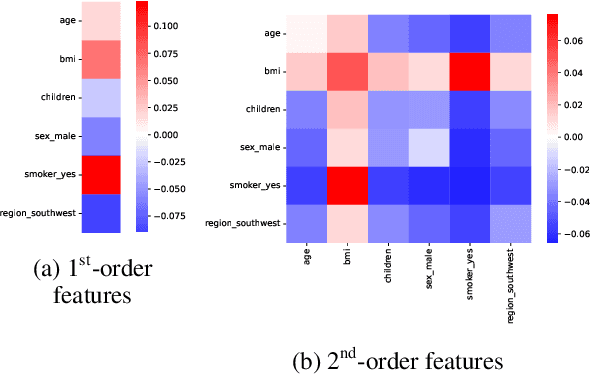
Explicit Feature Interaction-aware Graph Neural Networks
Apr 07, 2022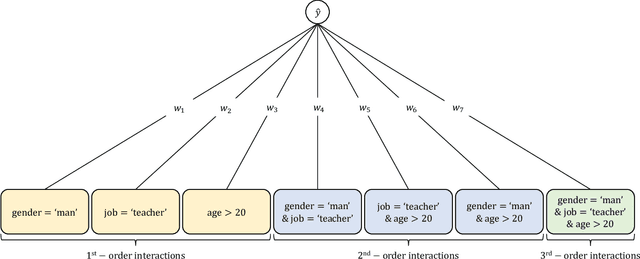


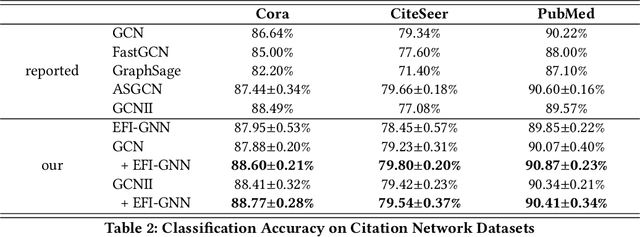
Graph neural networks are powerful methods to handle graph-structured data. However, existing graph neural networks only learn higher-order feature interactions implicitly. Thus, they cannot capture information that occurred in low-order feature interactions. To overcome this problem, we propose Explicit Feature Interaction-aware Graph Neural Network (EFI-GNN), which explicitly learns arbitrary-order feature interactions. EFI-GNN can jointly learn with any other graph neural network. We demonstrate that the joint learning method always enhances performance on the various node classification tasks. Furthermore, since EFI-GNN is inherently a linear model, we can interpret the prediction result of EFI-GNN. With the computation rule, we can obtain an any-order feature's effect on the decision. By that, we visualize the effects of the first-order and second-order features as a form of a heatmap.
Towards a Rigorous Evaluation of Time-series Anomaly Detection
Sep 11, 2021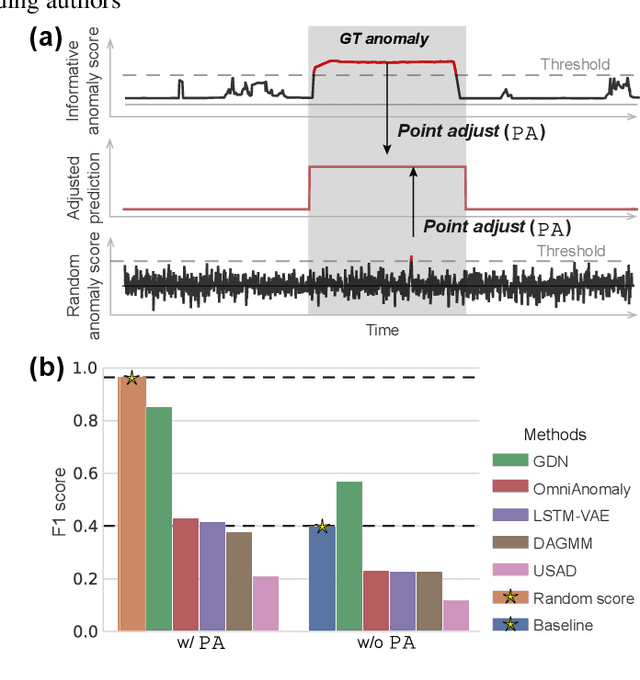
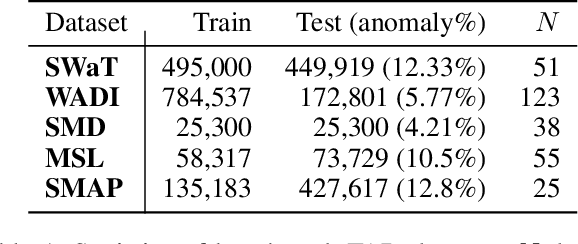
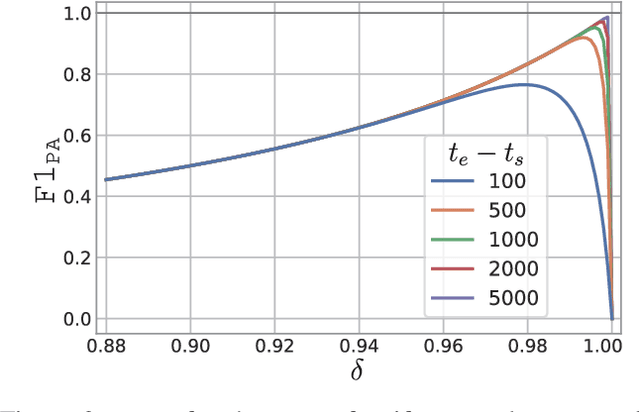
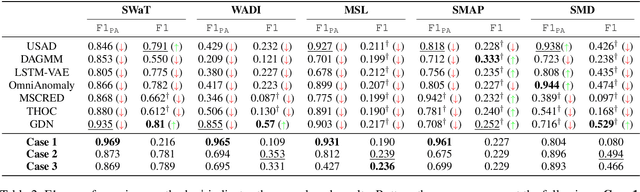
In recent years, proposed studies on time-series anomaly detection (TAD) report high F1 scores on benchmark TAD datasets, giving the impression of clear improvements. However, most studies apply a peculiar evaluation protocol called point adjustment (PA) before scoring. In this paper, we theoretically and experimentally reveal that the PA protocol has a great possibility of overestimating the detection performance; that is, even a random anomaly score can easily turn into a state-of-the-art TAD method. Therefore, the comparison of TAD methods with F1 scores after the PA protocol can lead to misguided rankings. Furthermore, we question the potential of existing TAD methods by showing that an untrained model obtains comparable detection performance to the existing methods even without PA. Based on our findings, we propose a new baseline and an evaluation protocol. We expect that our study will help a rigorous evaluation of TAD and lead to further improvement in future researches.
Pre-Training of Deep Bidirectional Protein Sequence Representations with Structural Information
Nov 25, 2019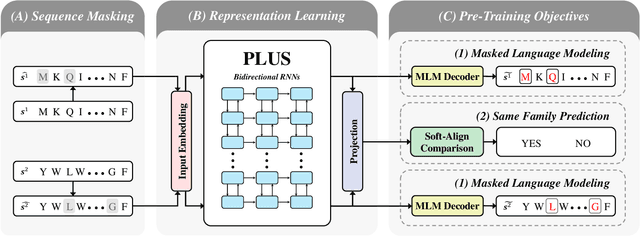
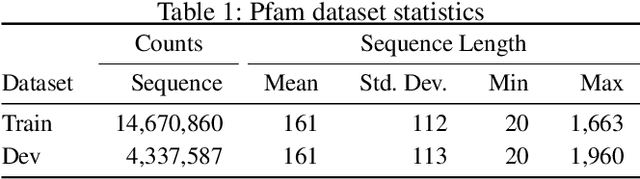
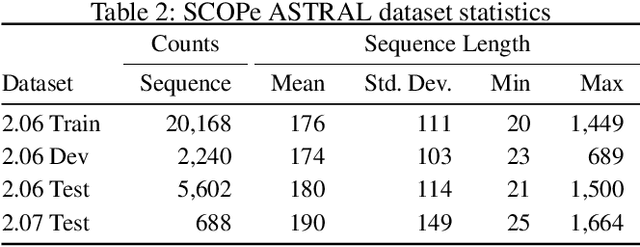
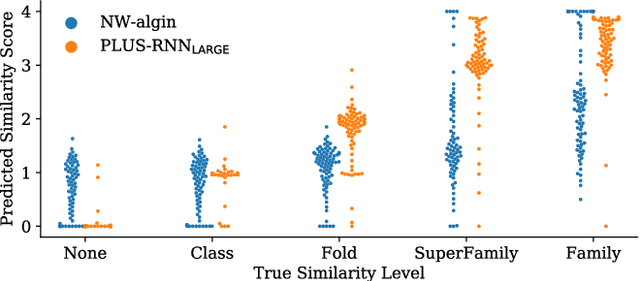
A structure of a protein has a direct impact on its properties and functions. However, identification of structural similarity directly from amino acid sequences remains as a challenging problem in computational biology. In this paper, we introduce a novel BERT-wise pre-training scheme for a protein sequence representation model called PLUS, which stands for Protein sequence representations Learned Using Structural information. As natural language representation models capture syntactic and semantic information of words from a large unlabeled text corpus, PLUS captures structural information of amino acids from a large weakly labeled protein database. Since the Transformer encoder, BERT's original model architecture, has a severe computational requirement to handle long sequences, we first propose to combine a bidirectional recurrent neural network with the BERT-wise pre-training scheme. PLUS is designed to learn protein representations with two pre-training objectives, i.e., masked language modeling and same family prediction. Then, the pre-trained model can be fine-tuned for a wide range of tasks without training randomly initialized task-specific models from scratch. It obtains new state-of-the-art results on both (1) protein-level and (2) amino-acid-level tasks, outperforming many task-specific algorithms.
PixelSteganalysis: Destroying Hidden Information with a Low Degree of Visual Degradation
Mar 02, 2019Steganography is the science of unnoticeably concealing a secret message within a certain image, called a cover image. The cover image with the secret message is called a stego image. Steganography is commonly used for illegal purposes such as terrorist activities and pornography. To thwart covert communications and transactions, attacking algorithms against steganography, called steganalysis, exist. Currently, there are many studies implementing deep learning to the steganography algorithm. However, conventional steganalysis is no longer effective for deep learning based steganography algorithms. Our framework is the first one to disturb covert communications and transactions via the recent deep learning-based steganography algorithms. We first extract a sophisticated pixel distribution of the potential stego image from the auto-regressive model induced by deep learning. Using the extracted pixel distributions, we detect whether an image is the stego or not at the pixel level. Each pixel value is adjusted as required and the adjustment induces an effective removal of the secret image. Because the decoding method of deep learning-based steganography algorithms is approximate (lossy), which is different from the conventional steganography, we propose a new quantitative metric that is more suitable for measuring the accurate effect. We evaluate our method using three public benchmarks in comparison with a conventional steganalysis method and show up to a 20% improvement in terms of decoding rate.
PixelSteganalysis: Pixel-wise Hidden Information Removal with Low Visual Degradation
Feb 28, 2019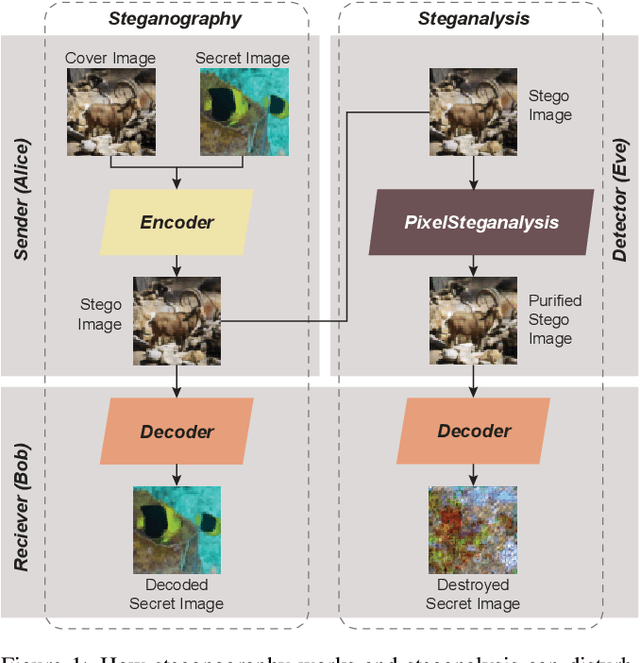
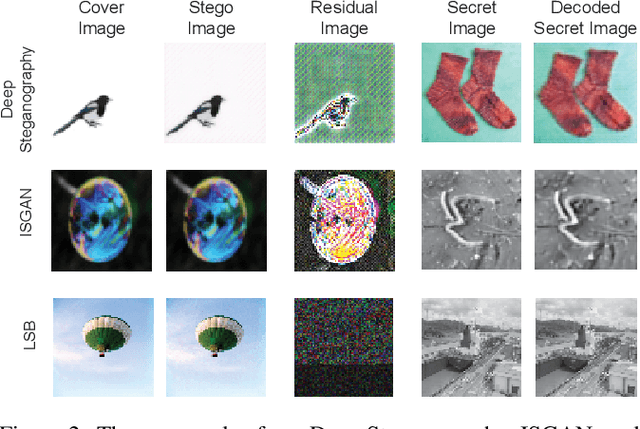
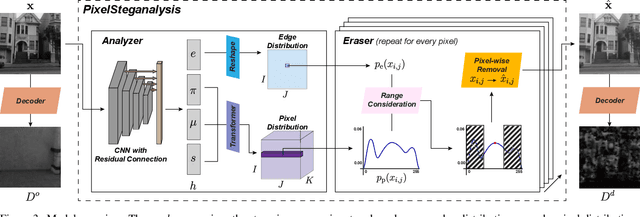
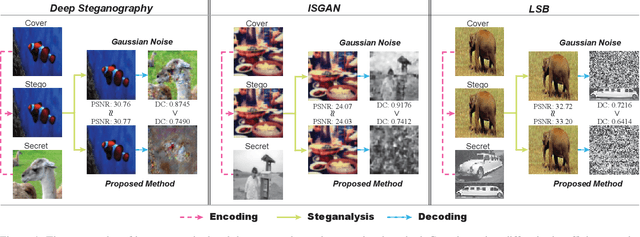
It is difficult to detect and remove secret images that are hidden in natural images using deep-learning algorithms. Our technique is the first work to effectively disable covert communications and transactions that use deep-learning steganography. We address the problem by exploiting sophisticated pixel distributions and edge areas of images using a deep neural network. Based on the given information, we adaptively remove secret information at the pixel level. We also introduce a new quantitative metric called destruction rate since the decoding method of deep-learning steganography is approximate (lossy), which is different from conventional steganography. We evaluate our technique using three public benchmarks in comparison with conventional steganalysis methods and show that the decoding rate improves by 10 ~ 20%.