 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVFLIP: A Backdoor Defense for Vertical Federated Learning via Identification and Purification
Aug 29, 2024Vertical Federated Learning (VFL) focuses on handling vertically partitioned data over FL participants. Recent studies have discovered a significant vulnerability in VFL to backdoor attacks which specifically target the distinct characteristics of VFL. Therefore, these attacks may neutralize existing defense mechanisms designed primarily for Horizontal Federated Learning (HFL) and deep neural networks. In this paper, we present the first backdoor defense, called VFLIP, specialized for VFL. VFLIP employs the identification and purification techniques that operate at the inference stage, consequently improving the robustness against backdoor attacks to a great extent. VFLIP first identifies backdoor-triggered embeddings by adopting a participant-wise anomaly detection approach. Subsequently, VFLIP conducts purification which removes the embeddings identified as malicious and reconstructs all the embeddings based on the remaining embeddings. We conduct extensive experiments on CIFAR10, CINIC10, Imagenette, NUS-WIDE, and BankMarketing to demonstrate that VFLIP can effectively mitigate backdoor attacks in VFL. https://github.com/blingcho/VFLIP-esorics24
FLGuard: Byzantine-Robust Federated Learning via Ensemble of Contrastive Models
Mar 05, 2024Federated Learning (FL) thrives in training a global model with numerous clients by only sharing the parameters of their local models trained with their private training datasets. Therefore, without revealing the private dataset, the clients can obtain a deep learning (DL) model with high performance. However, recent research proposed poisoning attacks that cause a catastrophic loss in the accuracy of the global model when adversaries, posed as benign clients, are present in a group of clients. Therefore, recent studies suggested byzantine-robust FL methods that allow the server to train an accurate global model even with the adversaries present in the system. However, many existing methods require the knowledge of the number of malicious clients or the auxiliary (clean) dataset or the effectiveness reportedly decreased hugely when the private dataset was non-independently and identically distributed (non-IID). In this work, we propose FLGuard, a novel byzantine-robust FL method that detects malicious clients and discards malicious local updates by utilizing the contrastive learning technique, which showed a tremendous improvement as a self-supervised learning method. With contrastive models, we design FLGuard as an ensemble scheme to maximize the defensive capability. We evaluate FLGuard extensively under various poisoning attacks and compare the accuracy of the global model with existing byzantine-robust FL methods. FLGuard outperforms the state-of-the-art defense methods in most cases and shows drastic improvement, especially in non-IID settings. https://github.com/201younghanlee/FLGuard
DAFA: Distance-Aware Fair Adversarial Training
Jan 23, 2024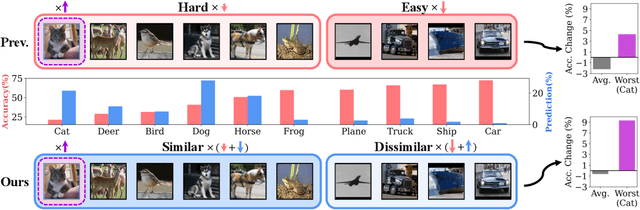
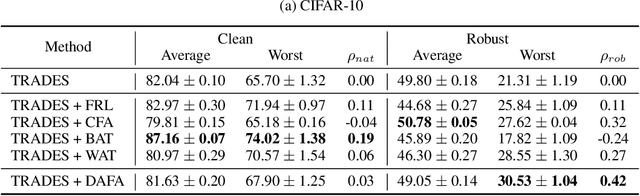
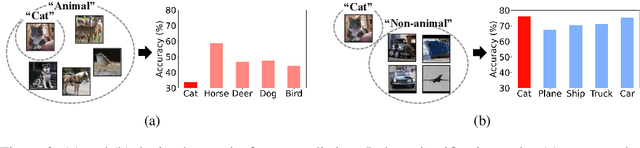
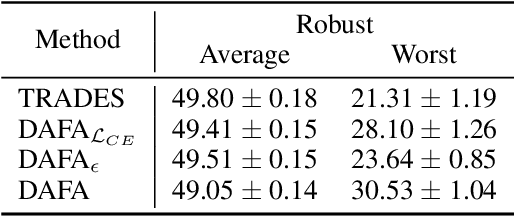
The disparity in accuracy between classes in standard training is amplified during adversarial training, a phenomenon termed the robust fairness problem. Existing methodologies aimed to enhance robust fairness by sacrificing the model's performance on easier classes in order to improve its performance on harder ones. However, we observe that under adversarial attacks, the majority of the model's predictions for samples from the worst class are biased towards classes similar to the worst class, rather than towards the easy classes. Through theoretical and empirical analysis, we demonstrate that robust fairness deteriorates as the distance between classes decreases. Motivated by these insights, we introduce the Distance-Aware Fair Adversarial training (DAFA) methodology, which addresses robust fairness by taking into account the similarities between classes. Specifically, our method assigns distinct loss weights and adversarial margins to each class and adjusts them to encourage a trade-off in robustness among similar classes. Experimental results across various datasets demonstrate that our method not only maintains average robust accuracy but also significantly improves the worst robust accuracy, indicating a marked improvement in robust fairness compared to existing methods.
PUCA: Patch-Unshuffle and Channel Attention for Enhanced Self-Supervised Image Denoising
Oct 16, 2023


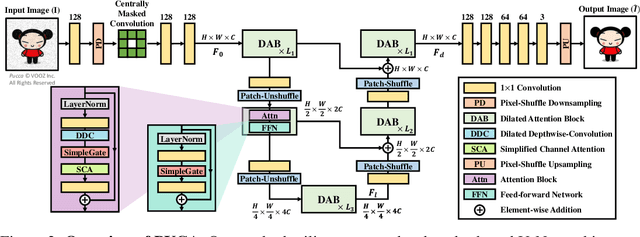
Although supervised image denoising networks have shown remarkable performance on synthesized noisy images, they often fail in practice due to the difference between real and synthesized noise. Since clean-noisy image pairs from the real world are extremely costly to gather, self-supervised learning, which utilizes noisy input itself as a target, has been studied. To prevent a self-supervised denoising model from learning identical mapping, each output pixel should not be influenced by its corresponding input pixel; This requirement is known as J-invariance. Blind-spot networks (BSNs) have been a prevalent choice to ensure J-invariance in self-supervised image denoising. However, constructing variations of BSNs by injecting additional operations such as downsampling can expose blinded information, thereby violating J-invariance. Consequently, convolutions designed specifically for BSNs have been allowed only, limiting architectural flexibility. To overcome this limitation, we propose PUCA, a novel J-invariant U-Net architecture, for self-supervised denoising. PUCA leverages patch-unshuffle/shuffle to dramatically expand receptive fields while maintaining J-invariance and dilated attention blocks (DABs) for global context incorporation. Experimental results demonstrate that PUCA achieves state-of-the-art performance, outperforming existing methods in self-supervised image denoising.
New Insights for the Stability-Plasticity Dilemma in Online Continual Learning
Feb 17, 2023The aim of continual learning is to learn new tasks continuously (i.e., plasticity) without forgetting previously learned knowledge from old tasks (i.e., stability). In the scenario of online continual learning, wherein data comes strictly in a streaming manner, the plasticity of online continual learning is more vulnerable than offline continual learning because the training signal that can be obtained from a single data point is limited. To overcome the stability-plasticity dilemma in online continual learning, we propose an online continual learning framework named multi-scale feature adaptation network (MuFAN) that utilizes a richer context encoding extracted from different levels of a pre-trained network. Additionally, we introduce a novel structure-wise distillation loss and replace the commonly used batch normalization layer with a newly proposed stability-plasticity normalization module to train MuFAN that simultaneously maintains high plasticity and stability. MuFAN outperforms other state-of-the-art continual learning methods on the SVHN, CIFAR100, miniImageNet, and CORe50 datasets. Extensive experiments and ablation studies validate the significance and scalability of each proposed component: 1) multi-scale feature maps from a pre-trained encoder, 2) the structure-wise distillation loss, and 3) the stability-plasticity normalization module in MuFAN. Code is publicly available at https://github.com/whitesnowdrop/MuFAN.
PixelSteganalysis: Destroying Hidden Information with a Low Degree of Visual Degradation
Mar 02, 2019Steganography is the science of unnoticeably concealing a secret message within a certain image, called a cover image. The cover image with the secret message is called a stego image. Steganography is commonly used for illegal purposes such as terrorist activities and pornography. To thwart covert communications and transactions, attacking algorithms against steganography, called steganalysis, exist. Currently, there are many studies implementing deep learning to the steganography algorithm. However, conventional steganalysis is no longer effective for deep learning based steganography algorithms. Our framework is the first one to disturb covert communications and transactions via the recent deep learning-based steganography algorithms. We first extract a sophisticated pixel distribution of the potential stego image from the auto-regressive model induced by deep learning. Using the extracted pixel distributions, we detect whether an image is the stego or not at the pixel level. Each pixel value is adjusted as required and the adjustment induces an effective removal of the secret image. Because the decoding method of deep learning-based steganography algorithms is approximate (lossy), which is different from the conventional steganography, we propose a new quantitative metric that is more suitable for measuring the accurate effect. We evaluate our method using three public benchmarks in comparison with a conventional steganalysis method and show up to a 20% improvement in terms of decoding rate.
PixelSteganalysis: Pixel-wise Hidden Information Removal with Low Visual Degradation
Feb 28, 2019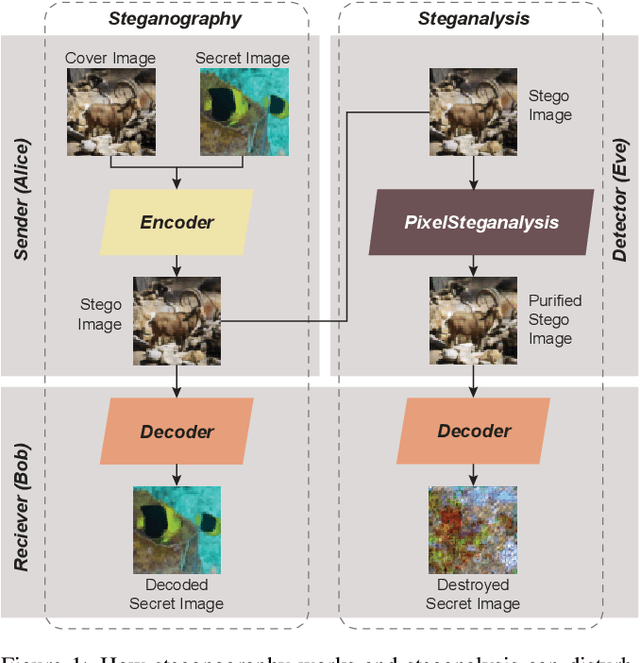
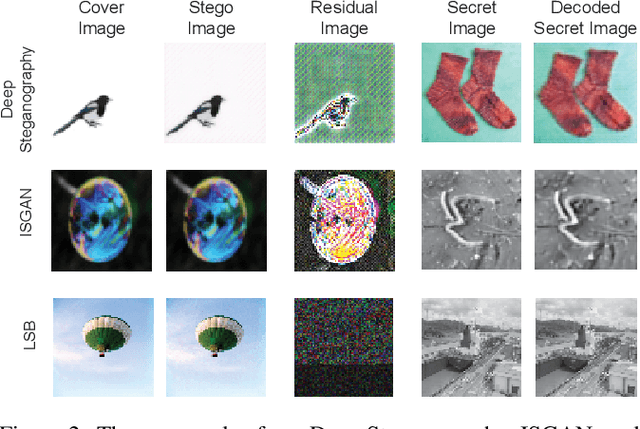
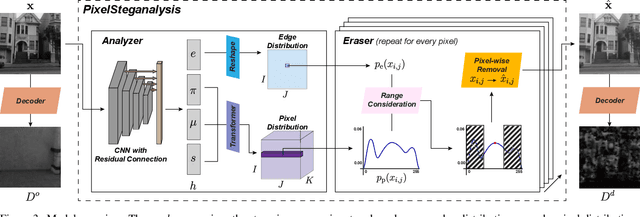
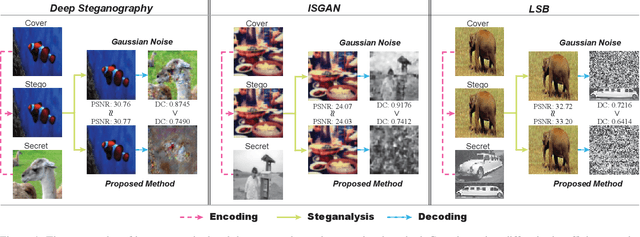
It is difficult to detect and remove secret images that are hidden in natural images using deep-learning algorithms. Our technique is the first work to effectively disable covert communications and transactions that use deep-learning steganography. We address the problem by exploiting sophisticated pixel distributions and edge areas of images using a deep neural network. Based on the given information, we adaptively remove secret information at the pixel level. We also introduce a new quantitative metric called destruction rate since the decoding method of deep-learning steganography is approximate (lossy), which is different from conventional steganography. We evaluate our technique using three public benchmarks in comparison with conventional steganalysis methods and show that the decoding rate improves by 10 ~ 20%.
AnomiGAN: Generative adversarial networks for anonymizing private medical data
Jan 31, 2019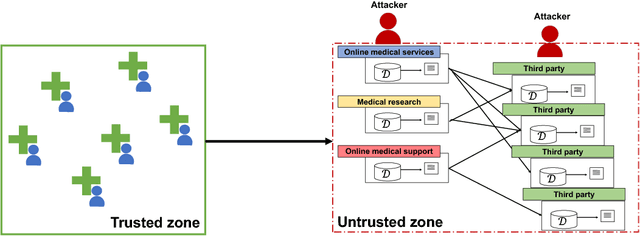
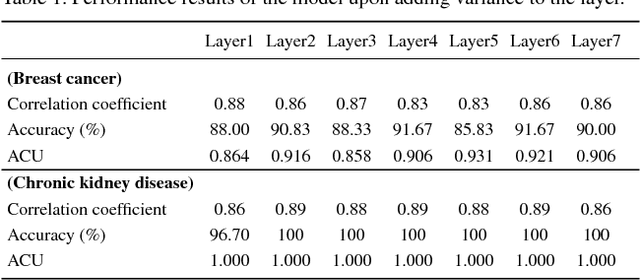
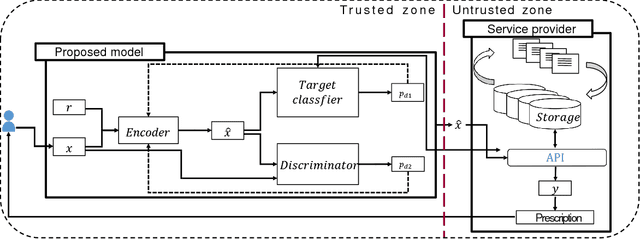

Typical personal medical data contains sensitive information about individuals. Storing or sharing the personal medical data is thus often risky. For example, a short DNA sequence can provide information that can not only identify an individual, but also his or her relatives. Nonetheless, most countries and researchers agree on the necessity of collecting personal medical data. This stems from the fact that medical data, including genomic data, are an indispensable resource for further research and development regarding disease prevention and treatment. To prevent personal medical data from being misused, techniques to reliably preserve sensitive information should be developed for real world application. In this paper, we propose a framework called anonymized generative adversarial networks (AnomiGAN), to improve the maintenance of privacy of personal medical data, while also maintaining high prediction performance. We compared our method to state-of-the-art techniques and observed that our method preserves the same level of privacy as differential privacy (DP), but had better prediction results. We also observed that there is a trade-off between privacy and performance results depending on the degree of preservation of the original data. Here, we provide a mathematical overview of our proposed model and demonstrate its validation using UCI machine learning repository datasets in order to highlight its utility in practice. Experimentally, our approach delivers a better performance compared to that of the DP approach.
DNA Steganalysis Using Deep Recurrent Neural Networks
Oct 05, 2018

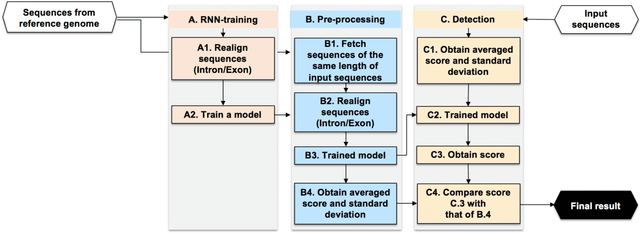
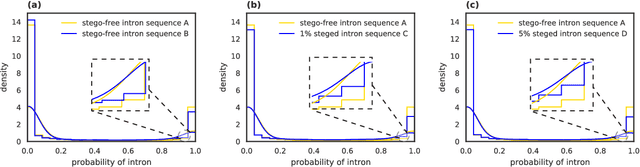
Recent advances in next-generation sequencing technologies have facilitated the use of deoxyribonucleic acid (DNA) as a novel covert channels in steganography. There are various methods that exist in other domains to detect hidden messages in conventional covert channels. However, they have not been applied to DNA steganography. The current most common detection approaches, namely frequency analysis-based methods, often overlook important signals when directly applied to DNA steganography because those methods depend on the distribution of the number of sequence characters. To address this limitation, we propose a general sequence learning-based DNA steganalysis framework. The proposed approach learns the intrinsic distribution of coding and non-coding sequences and detects hidden messages by exploiting distribution variations after hiding these messages. Using deep recurrent neural networks (RNNs), our framework identifies the distribution variations by using the classification score to predict whether a sequence is to be a coding or non-coding sequence. We compare our proposed method to various existing methods and biological sequence analysis methods implemented on top of our framework. According to our experimental results, our approach delivers a robust detection performance compared to other tools.
Security and Privacy Issues in Deep Learning
Jul 31, 2018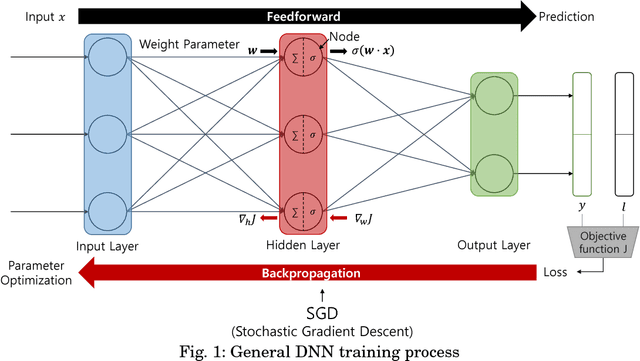
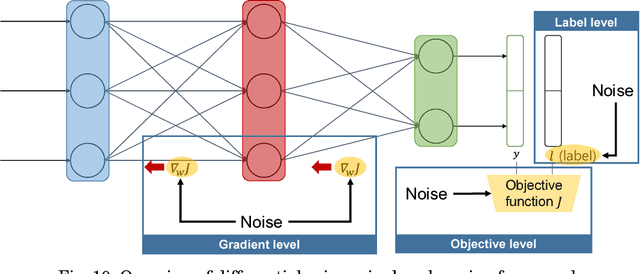
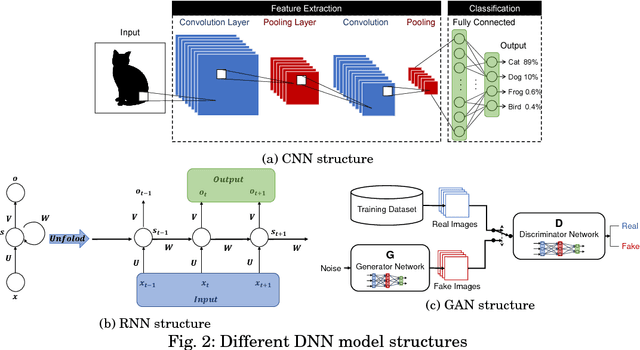
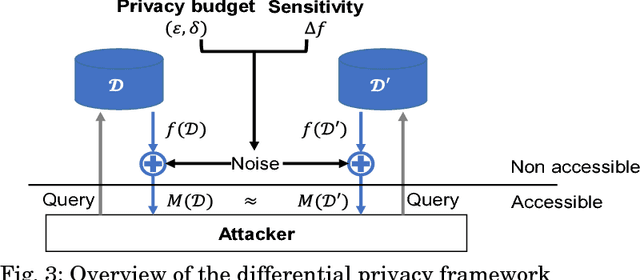
With the development of machine learning, expectations for artificial intelligence (AI) technology are increasing day by day. In particular, deep learning has shown enriched performance results in a variety of fields. There are many applications that are closely related to our daily life, such as making significant decisions in application area based on predictions or classifications, in which a deep learning (DL) model could be relevant. Hence, if a DL model causes mispredictions or misclassifications due to malicious external influences, it can cause very large difficulties in real life. Moreover, training deep learning models involves relying on an enormous amount of data and the training data often includes sensitive information. Therefore, deep learning models should not expose the privacy of such data. In this paper, we reviewed the threats and developed defense methods on the security of the models and the data privacy under the notion of SPAI: Secure and Private AI. We also discuss current challenges and open issues.