 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCANDI: Curated Test-Time Adaptation for Multivariate Time-Series Anomaly Detection Under Distribution Shift
Apr 02, 2026Multivariate time-series anomaly detection (MTSAD) aims to identify deviations from normality in multivariate time-series and is critical in real-world applications. However, in real-world deployments, distribution shifts are ubiquitous and cause severe performance degradation in pre-trained anomaly detector. Test-time adaptation (TTA) updates a pre-trained model on-the-fly using only unlabeled test data, making it promising for addressing this challenge. In this study, we propose CANDI (Curated test-time adaptation for multivariate time-series ANomaly detection under DIstribution shift), a novel TTA framework that selectively identifies and adapts to potential false positives while preserving pre-trained knowledge. CANDI introduces a False Positive Mining (FPM) strategy to curate adaptation samples based on anomaly scores and latent similarity, and incorporates a plug-and-play Spatiotemporally-Aware Normality Adaptation (SANA) module for structurally informed model updates. Extensive experiments demonstrate that CANDI significantly improves the performance of MTSAD under distribution shift, improving AUROC up to 14% while using fewer adaptation samples.
Geometric Backstepping Control of Omnidirectional Tiltrotors Incorporating Servo-Rotor Dynamics for Robustness against Sudden Disturbances
Oct 02, 2025This work presents a geometric backstepping controller for a variable-tilt omnidirectional multirotor that explicitly accounts for both servo and rotor dynamics. Considering actuator dynamics is essential for more effective and reliable operation, particularly during aggressive flight maneuvers or recovery from sudden disturbances. While prior studies have investigated actuator-aware control for conventional and fixed-tilt multirotors, these approaches rely on linear relationships between actuator input and wrench, which cannot capture the nonlinearities induced by variable tilt angles. In this work, we exploit the cascade structure between the rigid-body dynamics of the multirotor and its nonlinear actuator dynamics to design the proposed backstepping controller and establish exponential stability of the overall system. Furthermore, we reveal parametric uncertainty in the actuator model through experiments, and we demonstrate that the proposed controller remains robust against such uncertainty. The controller was compared against a baseline that does not account for actuator dynamics across three experimental scenarios: fast translational tracking, rapid rotational tracking, and recovery from sudden disturbance. The proposed method consistently achieved better tracking performance, and notably, while the baseline diverged and crashed during the fastest translational trajectory tracking and the recovery experiment, the proposed controller maintained stability and successfully completed the tasks, thereby demonstrating its effectiveness.
DAFA: Distance-Aware Fair Adversarial Training
Jan 23, 2024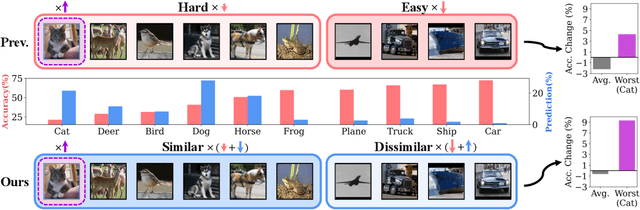
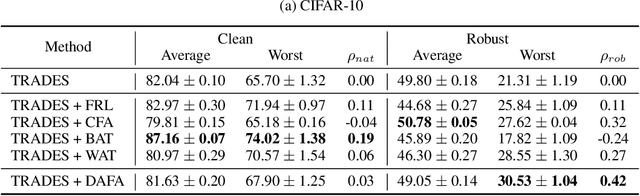
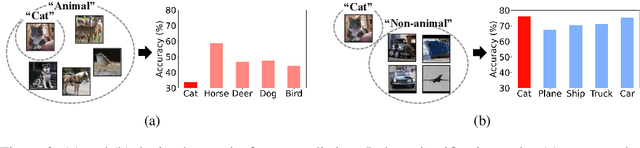
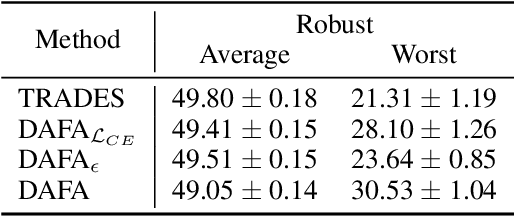
The disparity in accuracy between classes in standard training is amplified during adversarial training, a phenomenon termed the robust fairness problem. Existing methodologies aimed to enhance robust fairness by sacrificing the model's performance on easier classes in order to improve its performance on harder ones. However, we observe that under adversarial attacks, the majority of the model's predictions for samples from the worst class are biased towards classes similar to the worst class, rather than towards the easy classes. Through theoretical and empirical analysis, we demonstrate that robust fairness deteriorates as the distance between classes decreases. Motivated by these insights, we introduce the Distance-Aware Fair Adversarial training (DAFA) methodology, which addresses robust fairness by taking into account the similarities between classes. Specifically, our method assigns distinct loss weights and adversarial margins to each class and adjusts them to encourage a trade-off in robustness among similar classes. Experimental results across various datasets demonstrate that our method not only maintains average robust accuracy but also significantly improves the worst robust accuracy, indicating a marked improvement in robust fairness compared to existing methods.
Sample-efficient Adversarial Imitation Learning
Mar 14, 2023Imitation learning, in which learning is performed by demonstration, has been studied and advanced for sequential decision-making tasks in which a reward function is not predefined. However, imitation learning methods still require numerous expert demonstration samples to successfully imitate an expert's behavior. To improve sample efficiency, we utilize self-supervised representation learning, which can generate vast training signals from the given data. In this study, we propose a self-supervised representation-based adversarial imitation learning method to learn state and action representations that are robust to diverse distortions and temporally predictive, on non-image control tasks. In particular, in comparison with existing self-supervised learning methods for tabular data, we propose a different corruption method for state and action representations that is robust to diverse distortions. We theoretically and empirically observe that making an informative feature manifold with less sample complexity significantly improves the performance of imitation learning. The proposed method shows a 39% relative improvement over existing adversarial imitation learning methods on MuJoCo in a setting limited to 100 expert state-action pairs. Moreover, we conduct comprehensive ablations and additional experiments using demonstrations with varying optimality to provide insights into a range of factors.
Inducing Data Amplification Using Auxiliary Datasets in Adversarial Training
Sep 27, 2022
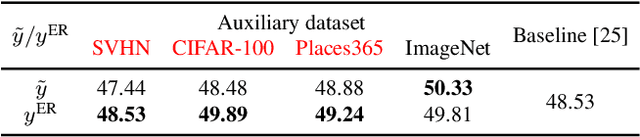
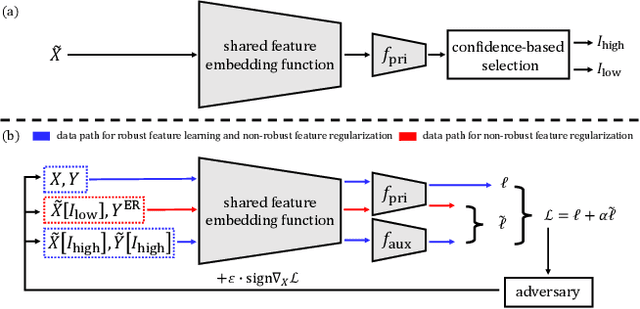

Several recent studies have shown that the use of extra in-distribution data can lead to a high level of adversarial robustness. However, there is no guarantee that it will always be possible to obtain sufficient extra data for a selected dataset. In this paper, we propose a biased multi-domain adversarial training (BiaMAT) method that induces training data amplification on a primary dataset using publicly available auxiliary datasets, without requiring the class distribution match between the primary and auxiliary datasets. The proposed method can achieve increased adversarial robustness on a primary dataset by leveraging auxiliary datasets via multi-domain learning. Specifically, data amplification on both robust and non-robust features can be accomplished through the application of BiaMAT as demonstrated through a theoretical and empirical analysis. Moreover, we demonstrate that while existing methods are vulnerable to negative transfer due to the distributional discrepancy between auxiliary and primary data, the proposed method enables neural networks to flexibly leverage diverse image datasets for adversarial training by successfully handling the domain discrepancy through the application of a confidence-based selection strategy. The pre-trained models and code are available at: \url{https://github.com/Saehyung-Lee/BiaMAT}.
Geometric Tracking Control of Omnidirectional Multirotors in the Presence of Rotor Dynamics
Sep 20, 2022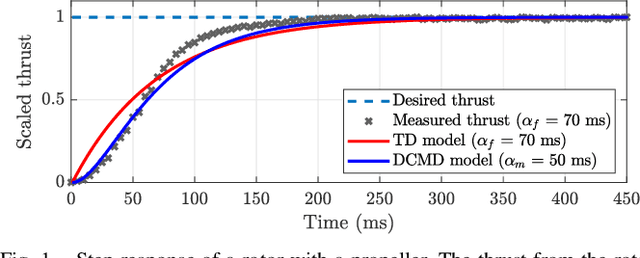
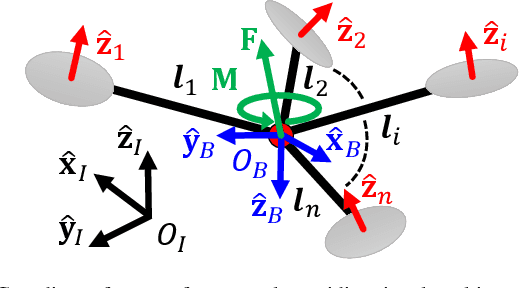
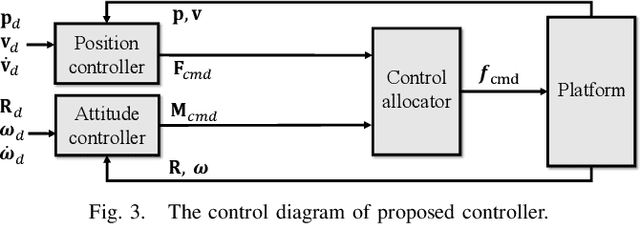
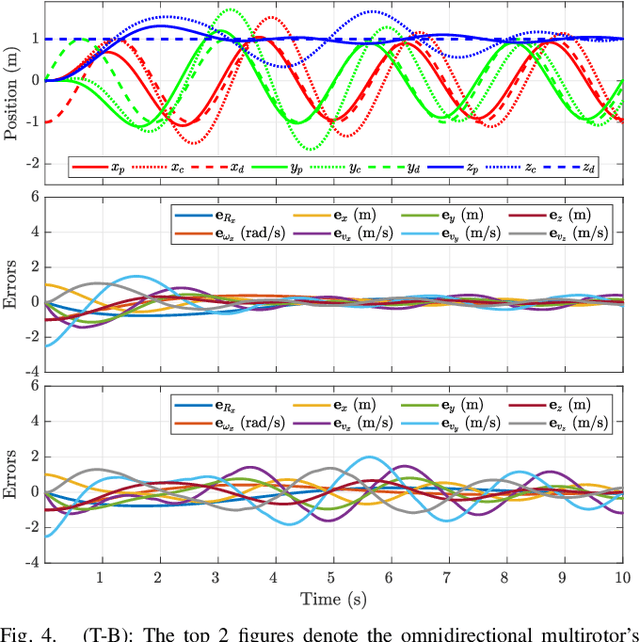
An omnidirectional multirotor has the advantageous maneuverability of decoupled translational and rotational motions, drastically superseding the traditional multirotors' motion capability. Such maneuverability requires an omnidirectional multirotor to frequently alter the thrust amplitude and even direction, which is prone to the rotors' settling time induced from the rotors' own dynamics. Furthermore, the omnidirectional multirotor's stability for tracking control in the presence of rotor dynamics has not yet been addressed. To resolve this issue, we propose a geometric tracking controller that takes the rotor dynamics into account. We show that the proposed controller yields the zero equilibrium of the error dynamics almost globally exponentially stable. The controller's tracking performance and stability are verified in simulations. Furthermore, the single-axis force experiment with the omnidirectional multirotor has been performed to confirm the proposed controller's performance in mitigating the rotors' settling time in the real world.
A Morphing Quadrotor that Can Optimize Morphology for Transportation
Aug 15, 2021
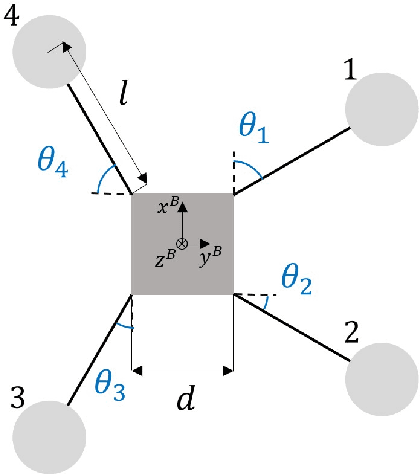
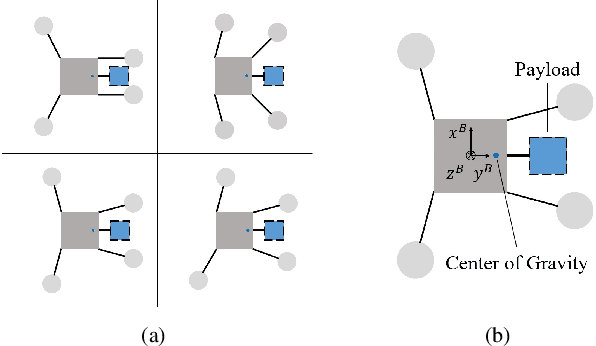
Multirotors can be effectively applied to various tasks, such as transportation, investigation, exploration, and lifesaving, depending on the type of payload. However, due to the nature of multirotors, the payload loaded on the multirotor is limited in its position and weight, which presents a major disadvantage when the multirotor is used in various fields. In this paper, we propose a novel method that greatly improves the restrictions on payload position and weight using a morphing quadrotor system. Our method can estimate the drone's weight, center of gravity position, and inertia tensor in real-time, which change depending on payload, and determine the optimal morphology for efficient and stable flight. An adaptive control method that can reflect the change in flight dynamics by payload and morphing is also presented. Experiments were conducted to confirm that the proposed morphing quadrotor improves the stability and efficiency in various situations of transporting payloads compared with the conventional quadrotor systems.
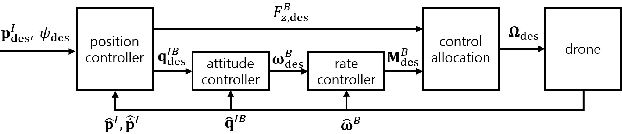
Low-level Pose Control of Tilting Multirotor for Wall Perching Tasks Using Reinforcement Learning
Aug 11, 2021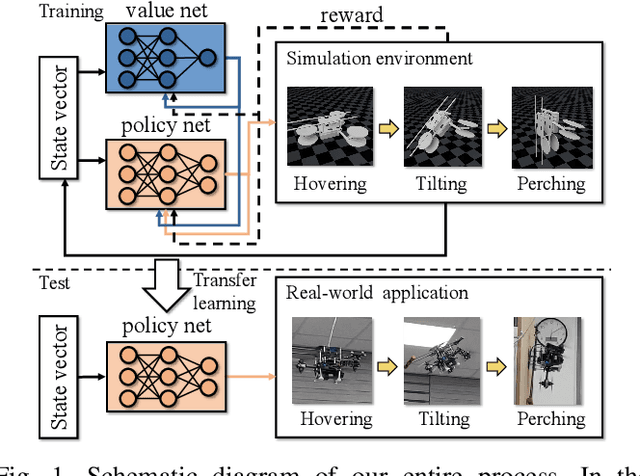
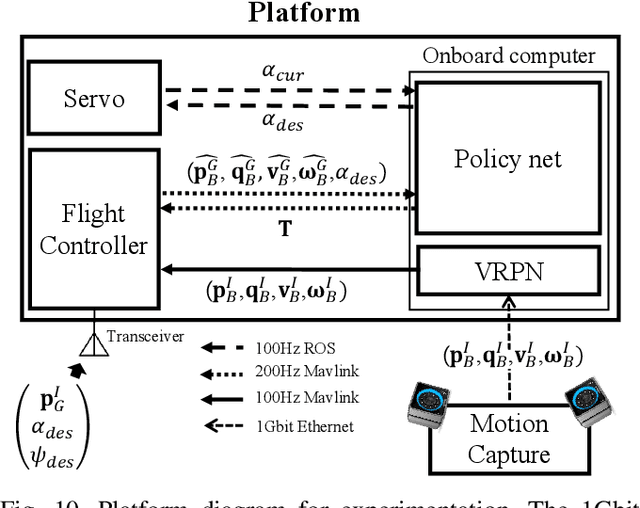
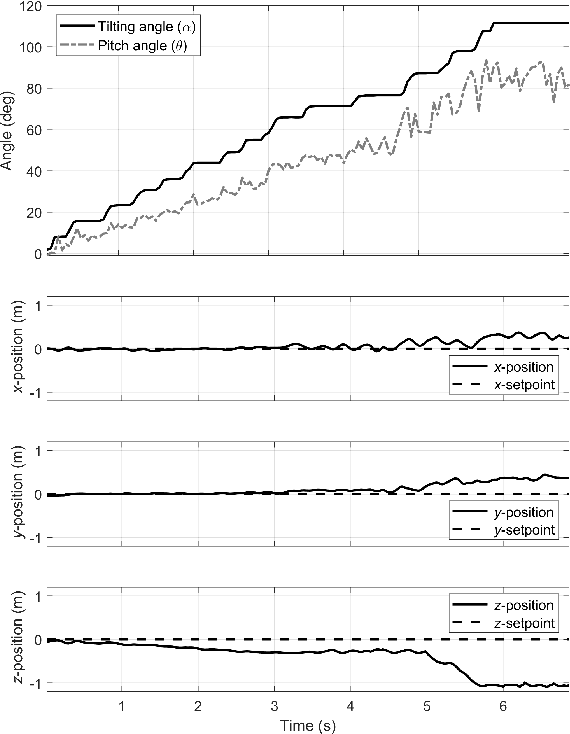
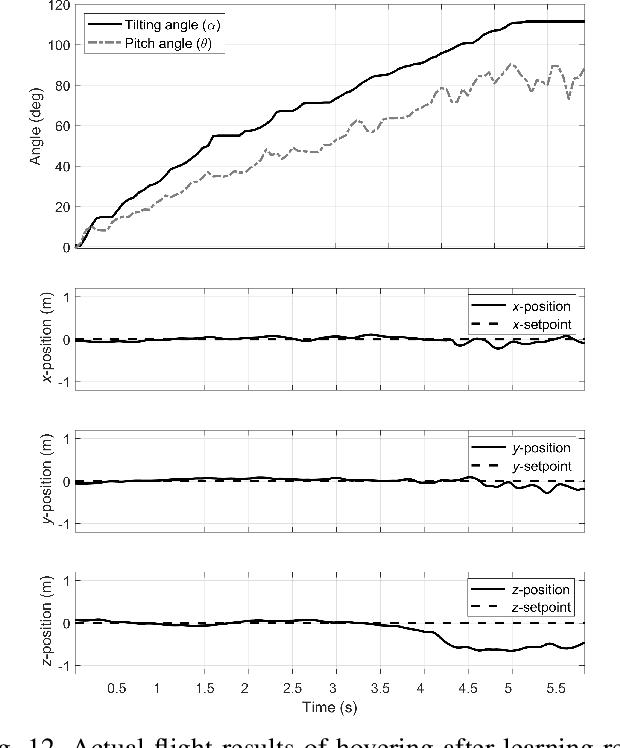
Recently, needs for unmanned aerial vehicles (UAVs) that are attachable to the wall have been highlighted. As one of the ways to address the need, researches on various tilting multirotors that can increase maneuverability has been employed. Unfortunately, existing studies on the tilting multirotors require considerable amounts of prior information on the complex dynamic model. Meanwhile, reinforcement learning on quadrotors has been studied to mitigate this issue. Yet, these are only been applied to standard quadrotors, whose systems are less complex than those of tilting multirotors. In this paper, a novel reinforcement learning-based method is proposed to control a tilting multirotor on real-world applications, which is the first attempt to apply reinforcement learning to a tilting multirotor. To do so, we propose a novel reward function for a neural network model that takes power efficiency into account. The model is initially trained over a simulated environment and then fine-tuned using real-world data in order to overcome the sim-to-real gap issue. Furthermore, a novel, efficient state representation with respect to the goal frame that helps the network learn optimal policy better is proposed. As verified on real-world experiments, our proposed method shows robust controllability by overcoming the complex dynamics of tilting multirotors.
Stein Latent Optimization for GANs
Jun 09, 2021
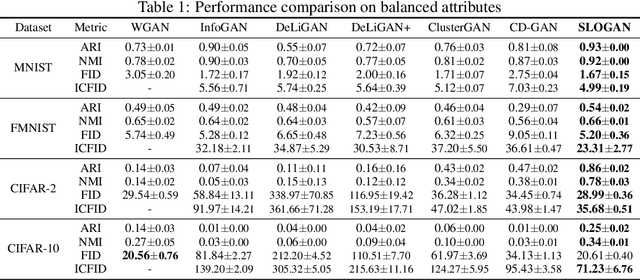
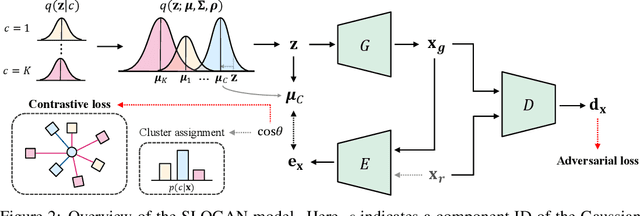
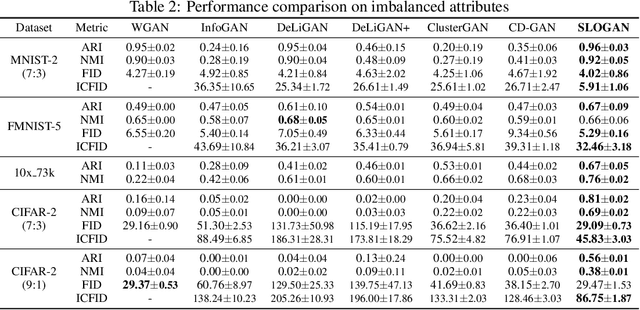
Generative adversarial networks (GANs) with clustered latent spaces can perform conditional generation in a completely unsupervised manner. However, the salient attributes of unlabeled data in the real-world are mostly imbalanced. Existing unsupervised conditional GANs cannot properly cluster the attributes in their latent spaces because they assume uniform distributions of the attributes. To address this problem, we theoretically derive Stein latent optimization that provides reparameterizable gradient estimations of the latent distribution parameters assuming a Gaussian mixture prior in a continuous latent space. Structurally, we introduce an encoder network and a novel contrastive loss to help generated data from a single mixture component to represent a single attribute. We confirm that the proposed method, named Stein Latent Optimization for GANs (SLOGAN), successfully learns the balanced or imbalanced attributes and performs unsupervised tasks such as unsupervised conditional generation, unconditional generation, and cluster assignment even in the absence of information of the attributes (e.g. the imbalance ratio). Moreover, we demonstrate that the attributes to be learned can be manipulated using a small amount of probe data.
Removing Undesirable Feature Contributions Using Out-of-Distribution Data
Jan 17, 2021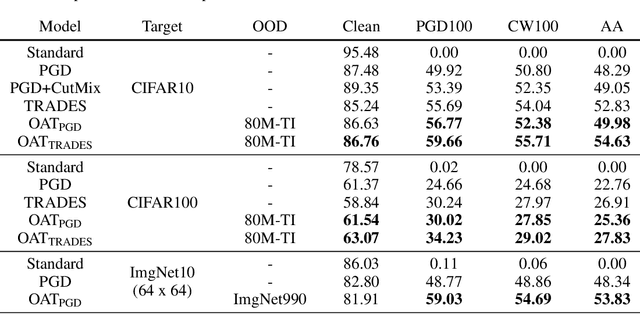
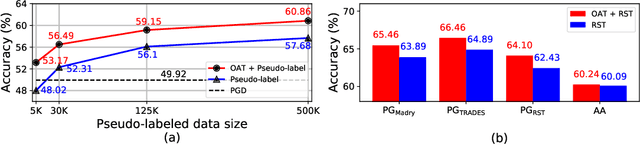

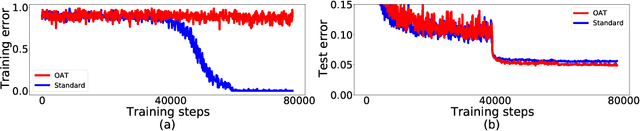
Several data augmentation methods deploy unlabeled-in-distribution (UID) data to bridge the gap between the training and inference of neural networks. However, these methods have clear limitations in terms of availability of UID data and dependence of algorithms on pseudo-labels. Herein, we propose a data augmentation method to improve generalization in both adversarial and standard learning by using out-of-distribution (OOD) data that are devoid of the abovementioned issues. We show how to improve generalization theoretically using OOD data in each learning scenario and complement our theoretical analysis with experiments on CIFAR-10, CIFAR-100, and a subset of ImageNet. The results indicate that undesirable features are shared even among image data that seem to have little correlation from a human point of view. We also present the advantages of the proposed method through comparison with other data augmentation methods, which can be used in the absence of UID data. Furthermore, we demonstrate that the proposed method can further improve the existing state-of-the-art adversarial training.