 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Frame Representation Alignment for Fine-Tuning Video Diffusion Models
Jun 10, 2025Fine-tuning Video Diffusion Models (VDMs) at the user level to generate videos that reflect specific attributes of training data presents notable challenges, yet remains underexplored despite its practical importance. Meanwhile, recent work such as Representation Alignment (REPA) has shown promise in improving the convergence and quality of DiT-based image diffusion models by aligning, or assimilating, its internal hidden states with external pretrained visual features, suggesting its potential for VDM fine-tuning. In this work, we first propose a straightforward adaptation of REPA for VDMs and empirically show that, while effective for convergence, it is suboptimal in preserving semantic consistency across frames. To address this limitation, we introduce Cross-frame Representation Alignment (CREPA), a novel regularization technique that aligns hidden states of a frame with external features from neighboring frames. Empirical evaluations on large-scale VDMs, including CogVideoX-5B and Hunyuan Video, demonstrate that CREPA improves both visual fidelity and cross-frame semantic coherence when fine-tuned with parameter-efficient methods such as LoRA. We further validate CREPA across diverse datasets with varying attributes, confirming its broad applicability. Project page: https://crepavideo.github.io
SphereDiff: Tuning-free Omnidirectional Panoramic Image and Video Generation via Spherical Latent Representation
Apr 19, 2025The increasing demand for AR/VR applications has highlighted the need for high-quality 360-degree panoramic content. However, generating high-quality 360-degree panoramic images and videos remains a challenging task due to the severe distortions introduced by equirectangular projection (ERP). Existing approaches either fine-tune pretrained diffusion models on limited ERP datasets or attempt tuning-free methods that still rely on ERP latent representations, leading to discontinuities near the poles. In this paper, we introduce SphereDiff, a novel approach for seamless 360-degree panoramic image and video generation using state-of-the-art diffusion models without additional tuning. We define a spherical latent representation that ensures uniform distribution across all perspectives, mitigating the distortions inherent in ERP. We extend MultiDiffusion to spherical latent space and propose a spherical latent sampling method to enable direct use of pretrained diffusion models. Moreover, we introduce distortion-aware weighted averaging to further improve the generation quality in the projection process. Our method outperforms existing approaches in generating 360-degree panoramic content while maintaining high fidelity, making it a robust solution for immersive AR/VR applications. The code is available here. https://github.com/pmh9960/SphereDiff
SurFhead: Affine Rig Blending for Geometrically Accurate 2D Gaussian Surfel Head Avatars
Oct 15, 2024Recent advancements in head avatar rendering using Gaussian primitives have achieved significantly high-fidelity results. Although precise head geometry is crucial for applications like mesh reconstruction and relighting, current methods struggle to capture intricate geometric details and render unseen poses due to their reliance on similarity transformations, which cannot handle stretch and shear transforms essential for detailed deformations of geometry. To address this, we propose SurFhead, a novel method that reconstructs riggable head geometry from RGB videos using 2D Gaussian surfels, which offer well-defined geometric properties, such as precise depth from fixed ray intersections and normals derived from their surface orientation, making them advantageous over 3D counterparts. SurFhead ensures high-fidelity rendering of both normals and images, even in extreme poses, by leveraging classical mesh-based deformation transfer and affine transformation interpolation. SurFhead introduces precise geometric deformation and blends surfels through polar decomposition of transformations, including those affecting normals. Our key contribution lies in bridging classical graphics techniques, such as mesh-based deformation, with modern Gaussian primitives, achieving state-of-the-art geometry reconstruction and rendering quality. Unlike previous avatar rendering approaches, SurFhead enables efficient reconstruction driven by Gaussian primitives while preserving high-fidelity geometry.
VEGS: View Extrapolation of Urban Scenes in 3D Gaussian Splatting using Learned Priors
Jul 03, 2024



Neural rendering-based urban scene reconstruction methods commonly rely on images collected from driving vehicles with cameras facing and moving forward. Although these methods can successfully synthesize from views similar to training camera trajectory, directing the novel view outside the training camera distribution does not guarantee on-par performance. In this paper, we tackle the Extrapolated View Synthesis (EVS) problem by evaluating the reconstructions on views such as looking left, right or downwards with respect to training camera distributions. To improve rendering quality for EVS, we initialize our model by constructing dense LiDAR map, and propose to leverage prior scene knowledge such as surface normal estimator and large-scale diffusion model. Qualitative and quantitative comparisons demonstrate the effectiveness of our methods on EVS. To the best of our knowledge, we are the first to address the EVS problem in urban scene reconstruction. Link to our project page: https://vegs3d.github.io/.
Effective Rank Analysis and Regularization for Enhanced 3D Gaussian Splatting
Jun 18, 2024



3D reconstruction from multi-view images is one of the fundamental challenges in computer vision and graphics. Recently, 3D Gaussian Splatting (3DGS) has emerged as a promising technique capable of real-time rendering with high-quality 3D reconstruction. This method utilizes 3D Gaussian representation and tile-based splatting techniques, bypassing the expensive neural field querying. Despite its potential, 3DGS encounters challenges, including needle-like artifacts, suboptimal geometries, and inaccurate normals, due to the Gaussians converging into anisotropic Gaussians with one dominant variance. We propose using effective rank analysis to examine the shape statistics of 3D Gaussian primitives, and identify the Gaussians indeed converge into needle-like shapes with the effective rank 1. To address this, we introduce effective rank as a regularization, which constrains the structure of the Gaussians. Our new regularization method enhances normal and geometry reconstruction while reducing needle-like artifacts. The approach can be integrated as an add-on module to other 3DGS variants, improving their quality without compromising visual fidelity.
Text2Control3D: Controllable 3D Avatar Generation in Neural Radiance Fields using Geometry-Guided Text-to-Image Diffusion Model
Sep 07, 2023Recent advances in diffusion models such as ControlNet have enabled geometrically controllable, high-fidelity text-to-image generation. However, none of them addresses the question of adding such controllability to text-to-3D generation. In response, we propose Text2Control3D, a controllable text-to-3D avatar generation method whose facial expression is controllable given a monocular video casually captured with hand-held camera. Our main strategy is to construct the 3D avatar in Neural Radiance Fields (NeRF) optimized with a set of controlled viewpoint-aware images that we generate from ControlNet, whose condition input is the depth map extracted from the input video. When generating the viewpoint-aware images, we utilize cross-reference attention to inject well-controlled, referential facial expression and appearance via cross attention. We also conduct low-pass filtering of Gaussian latent of the diffusion model in order to ameliorate the viewpoint-agnostic texture problem we observed from our empirical analysis, where the viewpoint-aware images contain identical textures on identical pixel positions that are incomprehensible in 3D. Finally, to train NeRF with the images that are viewpoint-aware yet are not strictly consistent in geometry, our approach considers per-image geometric variation as a view of deformation from a shared 3D canonical space. Consequently, we construct the 3D avatar in a canonical space of deformable NeRF by learning a set of per-image deformation via deformation field table. We demonstrate the empirical results and discuss the effectiveness of our method.
FaceCLIPNeRF: Text-driven 3D Face Manipulation using Deformable Neural Radiance Fields
Aug 07, 2023



As recent advances in Neural Radiance Fields (NeRF) have enabled high-fidelity 3D face reconstruction and novel view synthesis, its manipulation also became an essential task in 3D vision. However, existing manipulation methods require extensive human labor, such as a user-provided semantic mask and manual attribute search unsuitable for non-expert users. Instead, our approach is designed to require a single text to manipulate a face reconstructed with NeRF. To do so, we first train a scene manipulator, a latent code-conditional deformable NeRF, over a dynamic scene to control a face deformation using the latent code. However, representing a scene deformation with a single latent code is unfavorable for compositing local deformations observed in different instances. As so, our proposed Position-conditional Anchor Compositor (PAC) learns to represent a manipulated scene with spatially varying latent codes. Their renderings with the scene manipulator are then optimized to yield high cosine similarity to a target text in CLIP embedding space for text-driven manipulation. To the best of our knowledge, our approach is the first to address the text-driven manipulation of a face reconstructed with NeRF. Extensive results, comparisons, and ablation studies demonstrate the effectiveness of our approach.
Local 3D Editing via 3D Distillation of CLIP Knowledge
Jun 21, 2023



3D content manipulation is an important computer vision task with many real-world applications (e.g., product design, cartoon generation, and 3D Avatar editing). Recently proposed 3D GANs can generate diverse photorealistic 3D-aware contents using Neural Radiance fields (NeRF). However, manipulation of NeRF still remains a challenging problem since the visual quality tends to degrade after manipulation and suboptimal control handles such as 2D semantic maps are used for manipulations. While text-guided manipulations have shown potential in 3D editing, such approaches often lack locality. To overcome these problems, we propose Local Editing NeRF (LENeRF), which only requires text inputs for fine-grained and localized manipulation. Specifically, we present three add-on modules of LENeRF, the Latent Residual Mapper, the Attention Field Network, and the Deformation Network, which are jointly used for local manipulations of 3D features by estimating a 3D attention field. The 3D attention field is learned in an unsupervised way, by distilling the zero-shot mask generation capability of CLIP to the 3D space with multi-view guidance. We conduct diverse experiments and thorough evaluations both quantitatively and qualitatively.
* conference: CVPR 2023
Low-level Pose Control of Tilting Multirotor for Wall Perching Tasks Using Reinforcement Learning
Aug 11, 2021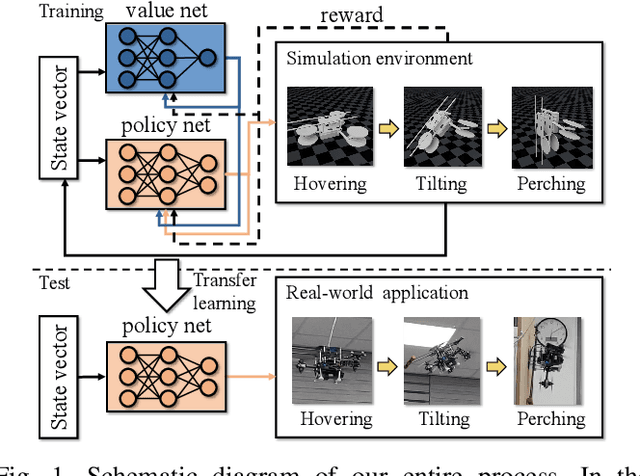
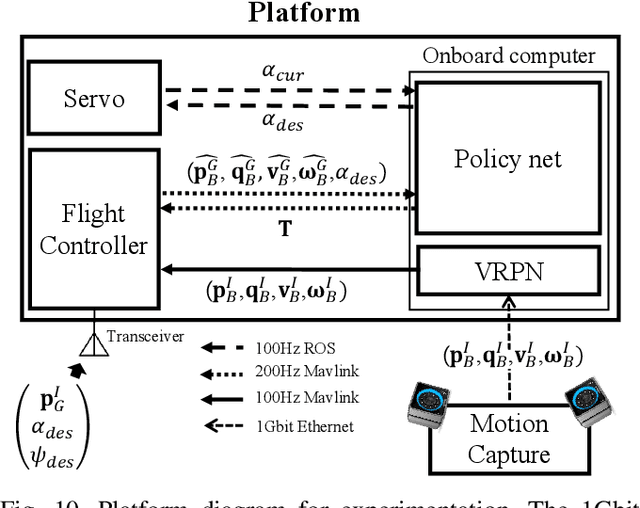
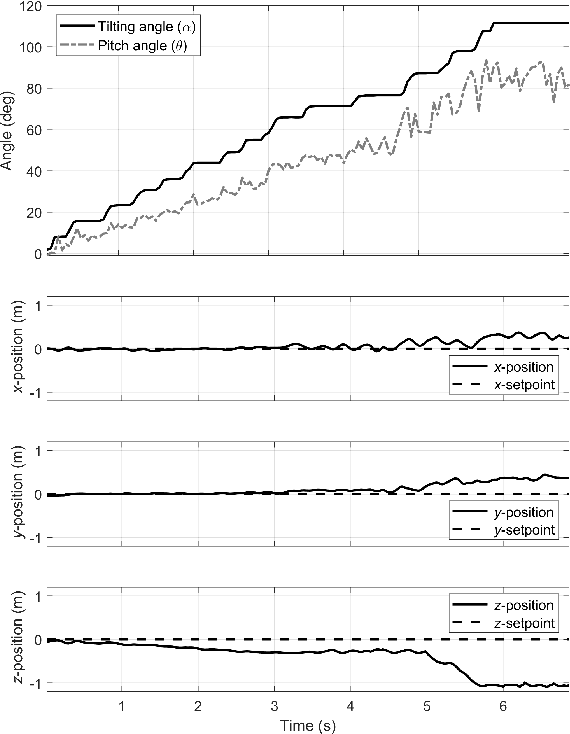
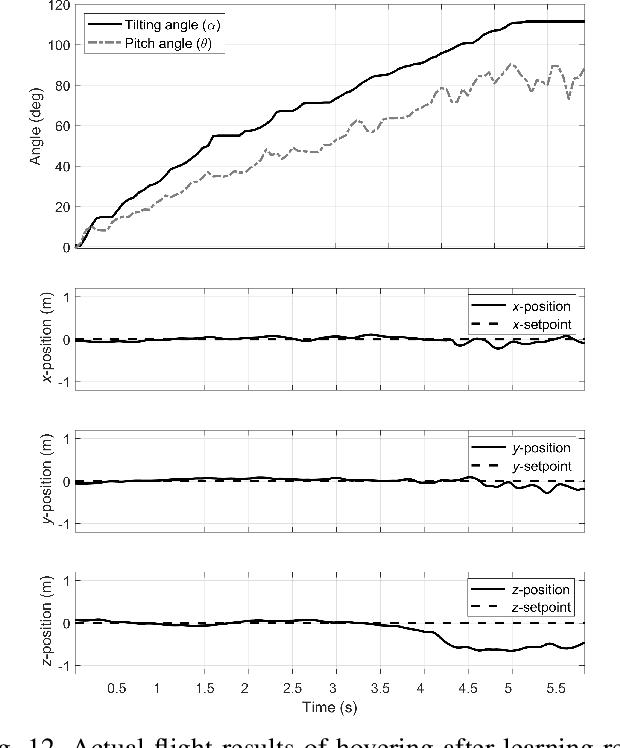
Recently, needs for unmanned aerial vehicles (UAVs) that are attachable to the wall have been highlighted. As one of the ways to address the need, researches on various tilting multirotors that can increase maneuverability has been employed. Unfortunately, existing studies on the tilting multirotors require considerable amounts of prior information on the complex dynamic model. Meanwhile, reinforcement learning on quadrotors has been studied to mitigate this issue. Yet, these are only been applied to standard quadrotors, whose systems are less complex than those of tilting multirotors. In this paper, a novel reinforcement learning-based method is proposed to control a tilting multirotor on real-world applications, which is the first attempt to apply reinforcement learning to a tilting multirotor. To do so, we propose a novel reward function for a neural network model that takes power efficiency into account. The model is initially trained over a simulated environment and then fine-tuned using real-world data in order to overcome the sim-to-real gap issue. Furthermore, a novel, efficient state representation with respect to the goal frame that helps the network learn optimal policy better is proposed. As verified on real-world experiments, our proposed method shows robust controllability by overcoming the complex dynamics of tilting multirotors.
Equivariance-bridged SO(2)-Invariant Representation Learning using Graph Convolutional Network
Jun 18, 2021
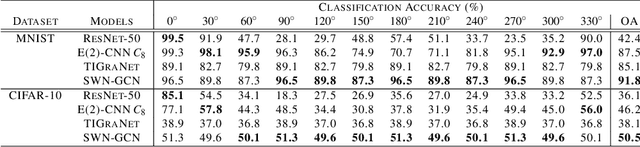
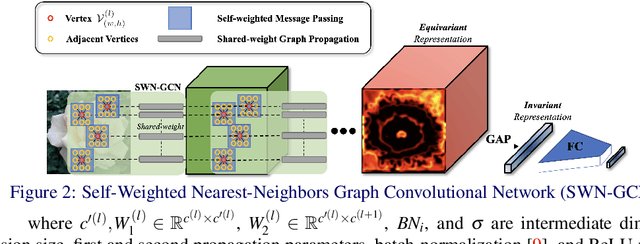

Training a Convolutional Neural Network (CNN) to be robust against rotation has mostly been done with data augmentation. In this paper, another progressive vision of research direction is highlighted to encourage less dependence on data augmentation by achieving structural rotational invariance of a network. The deep equivariance-bridged SO(2) invariant network is proposed to echo such vision. First, Self-Weighted Nearest Neighbors Graph Convolutional Network (SWN-GCN) is proposed to implement Graph Convolutional Network (GCN) on the graph representation of an image to acquire rotationally equivariant representation, as GCN is more suitable for constructing deeper network than spectral graph convolution-based approaches. Then, invariant representation is eventually obtained with Global Average Pooling (GAP), a permutation-invariant operation suitable for aggregating high-dimensional representations, over the equivariant set of vertices retrieved from SWN-GCN. Our method achieves the state-of-the-art image classification performance on rotated MNIST and CIFAR-10 images, where the models are trained with a non-augmented dataset only. Quantitative validations over invariance of the representations also demonstrate strong invariance of deep representations of SWN-GCN over rotations.