 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenZ-LIO: Generalizable LiDAR-Inertial Odometry Beyond Indoor--Outdoor Boundaries
Mar 17, 2026Light detection and ranging (LiDAR)-inertial odometry (LIO) enables accurate localization and mapping for autonomous navigation in various scenes. However, its performance remains sensitive to variations in spatial scale, which refers to the spatial extent of the scene reflected in the distribution of point ranges in a LiDAR scan. Transitions between confined indoor and expansive outdoor spaces induce substantial variations in point density, which may reduce robustness and computational efficiency. To address this issue, we propose GenZ-LIO, a LIO framework generalizable across both indoor and outdoor environments. GenZ-LIO comprises three key components. First, inspired by the principle of the proportional-integral-derivative (PID) controller, it adaptively regulates the voxel size for downsampling via feedback control, driving the voxelized point count toward a scale-informed setpoint while enabling stable and efficient processing across varying scene scales. Second, we formulate a hybrid-metric state update that jointly leverages point-to-plane and point-to-point residuals to mitigate LiDAR degeneracy arising from directionally insufficient geometric constraints. Third, to alleviate the computational burden introduced by point-to-point matching, we introduce a voxel-pruned correspondence search strategy that discards non-promising voxel candidates and reduces unnecessary computations. Experimental results demonstrate that GenZ-LIO achieves robust odometry estimation and improved computational efficiency across confined indoor, open outdoor, and transitional environments. Our code will be made publicly available upon publication.
Towards Zero-Shot Point Cloud Registration Across Diverse Scales, Scenes, and Sensor Setups
Jan 06, 2026Some deep learning-based point cloud registration methods struggle with zero-shot generalization, often requiring dataset-specific hyperparameter tuning or retraining for new environments. We identify three critical limitations: (a) fixed user-defined parameters (e.g., voxel size, search radius) that fail to generalize across varying scales, (b) learned keypoint detectors exhibit poor cross-domain transferability, and (c) absolute coordinates amplify scale mismatches between datasets. To address these three issues, we present BUFFER-X, a training-free registration framework that achieves zero-shot generalization through: (a) geometric bootstrapping for automatic hyperparameter estimation, (b) distribution-aware farthest point sampling to replace learned detectors, and (c) patch-level coordinate normalization to ensure scale consistency. Our approach employs hierarchical multi-scale matching to extract correspondences across local, middle, and global receptive fields, enabling robust registration in diverse environments. For efficiency-critical applications, we introduce BUFFER-X-Lite, which reduces total computation time by 43% (relative to BUFFER-X) through early exit strategies and fast pose solvers while preserving accuracy. We evaluate on a comprehensive benchmark comprising 12 datasets spanning object-scale, indoor, and outdoor scenes, including cross-sensor registration between heterogeneous LiDAR configurations. Results demonstrate that our approach generalizes effectively without manual tuning or prior knowledge of test domains. Code: https://github.com/MIT-SPARK/BUFFER-X.
VGGT-SLAM: Dense RGB SLAM Optimized on the SL(4) Manifold
May 18, 2025



We present VGGT-SLAM, a dense RGB SLAM system constructed by incrementally and globally aligning submaps created from the feed-forward scene reconstruction approach VGGT using only uncalibrated monocular cameras. While related works align submaps using similarity transforms (i.e., translation, rotation, and scale), we show that such approaches are inadequate in the case of uncalibrated cameras. In particular, we revisit the idea of reconstruction ambiguity, where given a set of uncalibrated cameras with no assumption on the camera motion or scene structure, the scene can only be reconstructed up to a 15-degrees-of-freedom projective transformation of the true geometry. This inspires us to recover a consistent scene reconstruction across submaps by optimizing over the SL(4) manifold, thus estimating 15-degrees-of-freedom homography transforms between sequential submaps while accounting for potential loop closure constraints. As verified by extensive experiments, we demonstrate that VGGT-SLAM achieves improved map quality using long video sequences that are infeasible for VGGT due to its high GPU requirements.
SKiD-SLAM: Robust, Lightweight, and Distributed Multi-Robot LiDAR SLAM in Resource-Constrained Field Environments
May 13, 2025Distributed LiDAR SLAM is crucial for achieving efficient robot autonomy and improving the scalability of mapping. However, two issues need to be considered when applying it in field environments: one is resource limitation, and the other is inter/intra-robot association. The resource limitation issue arises when the data size exceeds the processing capacity of the network or memory, especially when utilizing communication systems or onboard computers in the field. The inter/intra-robot association issue occurs due to the narrow convergence region of ICP under large viewpoint differences, triggering many false positive loops and ultimately resulting in an inconsistent global map for multi-robot systems. To tackle these problems, we propose a distributed LiDAR SLAM framework designed for versatile field applications, called SKiD-SLAM. Extending our previous work that solely focused on lightweight place recognition and fast and robust global registration, we present a multi-robot mapping framework that focuses on robust and lightweight inter-robot loop closure in distributed LiDAR SLAM. Through various environmental experiments, we demonstrate that our method is more robust and lightweight compared to other state-of-the-art distributed SLAM approaches, overcoming resource limitation and inter/intra-robot association issues. Also, we validated the field applicability of our approach through mapping experiments in real-world planetary emulation terrain and cave environments, which are in-house datasets. Our code will be available at https://sparolab.github.io/research/skid_slam/.
BUFFER-X: Towards Zero-Shot Point Cloud Registration in Diverse Scenes
Mar 11, 2025Recent advances in deep learning-based point cloud registration have improved generalization, yet most methods still require retraining or manual parameter tuning for each new environment. In this paper, we identify three key factors limiting generalization: (a) reliance on environment-specific voxel size and search radius, (b) poor out-of-domain robustness of learning-based keypoint detectors, and (c) raw coordinate usage, which exacerbates scale discrepancies. To address these issues, we present a zero-shot registration pipeline called BUFFER-X by (a) adaptively determining voxel size/search radii, (b) using farthest point sampling to bypass learned detectors, and (c) leveraging patch-wise scale normalization for consistent coordinate bounds. In particular, we present a multi-scale patch-based descriptor generation and a hierarchical inlier search across scales to improve robustness in diverse scenes. We also propose a novel generalizability benchmark using 11 datasets that cover various indoor/outdoor scenarios and sensor modalities, demonstrating that BUFFER-X achieves substantial generalization without prior information or manual parameter tuning for the test datasets. Our code is available at https://github.com/MIT-SPARK/BUFFER-X.
TRIP: Terrain Traversability Mapping With Risk-Aware Prediction for Enhanced Online Quadrupedal Robot Navigation
Nov 26, 2024



Accurate traversability estimation using an online dense terrain map is crucial for safe navigation in challenging environments like construction and disaster areas. However, traversability estimation for legged robots on rough terrains faces substantial challenges owing to limited terrain information caused by restricted field-of-view, and data occlusion and sparsity. To robustly map traversable regions, we introduce terrain traversability mapping with risk-aware prediction (TRIP). TRIP reconstructs the terrain maps while predicting multi-modal traversability risks, enhancing online autonomous navigation with the following contributions. Firstly, estimating steppability in a spherical projection space allows for addressing data sparsity while accomodating scalable terrain properties. Moreover, the proposed traversability-aware Bayesian generalized kernel (T-BGK)-based inference method enhances terrain completion accuracy and efficiency. Lastly, leveraging the steppability-based Mahalanobis distance contributes to robustness against outliers and dynamic elements, ultimately yielding a static terrain traversability map. As verified in both public and our in-house datasets, our TRIP shows significant performance increases in terms of terrain reconstruction and navigation map. A demo video that demonstrates its feasibility as an integral component within an onboard online autonomous navigation system for quadruped robots is available at https://youtu.be/d7HlqAP4l0c.
GenZ-ICP: Generalizable and Degeneracy-Robust LiDAR Odometry Using an Adaptive Weighting
Nov 11, 2024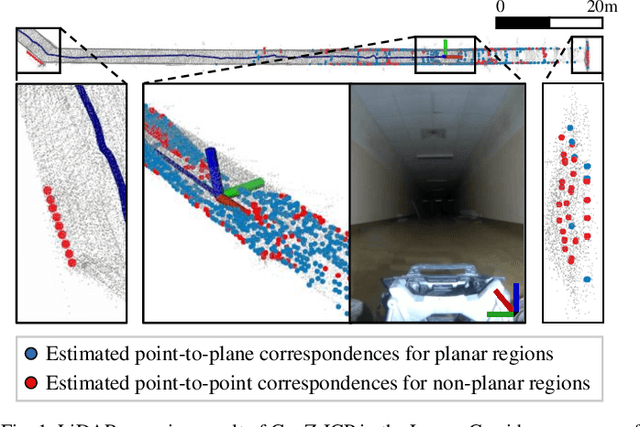
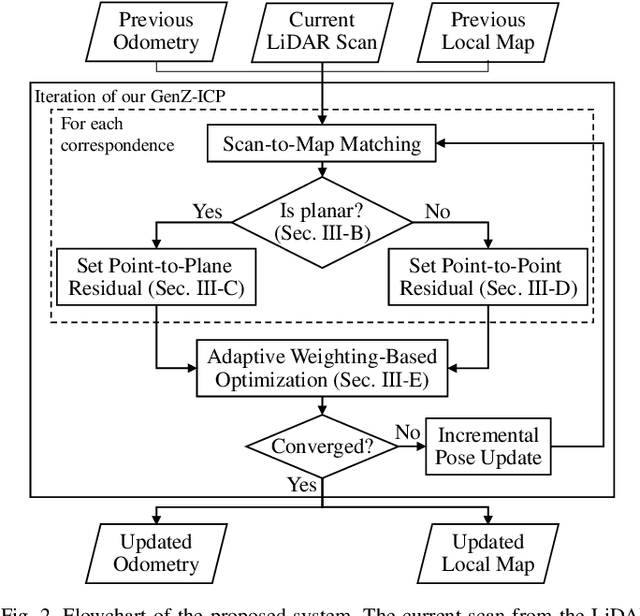
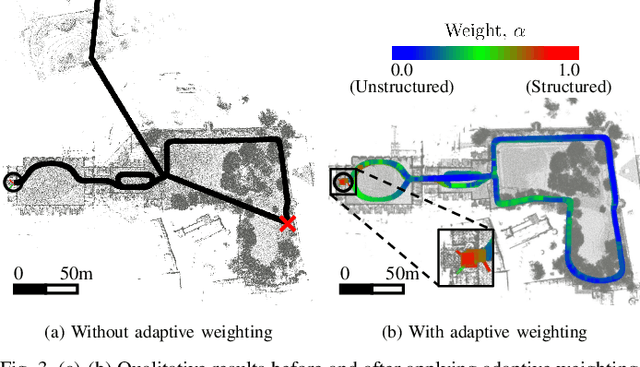
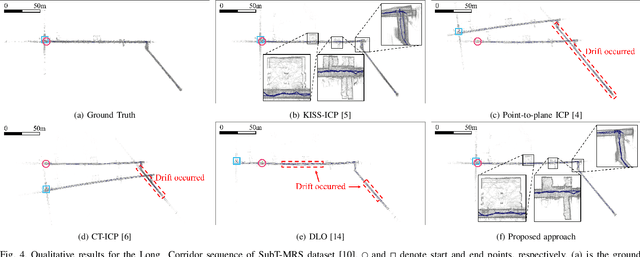
Light detection and ranging (LiDAR)-based odometry has been widely utilized for pose estimation due to its use of high-accuracy range measurements and immunity to ambient light conditions. However, the performance of LiDAR odometry varies depending on the environment and deteriorates in degenerative environments such as long corridors. This issue stems from the dependence on a single error metric, which has different strengths and weaknesses depending on the geometrical characteristics of the surroundings. To address these problems, this study proposes a novel iterative closest point (ICP) method called GenZ-ICP. We revisited both point-to-plane and point-to-point error metrics and propose a method that leverages their strengths in a complementary manner. Moreover, adaptability to diverse environments was enhanced by utilizing an adaptive weight that is adjusted based on the geometrical characteristics of the surroundings. As demonstrated in our experimental evaluation, the proposed GenZ-ICP exhibits high adaptability to various environments and resilience to optimization degradation in corridor-like degenerative scenarios by preventing ill-posed problems during the optimization process.
* 8 pages, 5 figures, Accepted to IEEE Robotics and Automation Letters (RA-L)
DynaVINS++: Robust Visual-Inertial State Estimator in Dynamic Environments by Adaptive Truncated Least Squares and Stable State Recovery
Oct 20, 2024Despite extensive research in robust visual-inertial navigation systems~(VINS) in dynamic environments, many approaches remain vulnerable to objects that suddenly start moving, which are referred to as \textit{abruptly dynamic objects}. In addition, most approaches have considered the effect of dynamic objects only at the feature association level. In this study, we observed that the state estimation diverges when errors from false correspondences owing to moving objects incorrectly propagate into the IMU bias terms. To overcome these problems, we propose a robust VINS framework called \mbox{\textit{DynaVINS++}}, which employs a) adaptive truncated least square method that adaptively adjusts the truncation range using both feature association and IMU preintegration to effectively minimize the effect of the dynamic objects while reducing the computational cost, and b)~stable state recovery with bias consistency check to correct misestimated IMU bias and to prevent the divergence caused by abruptly dynamic objects. As verified in both public and real-world datasets, our approach shows promising performance in dynamic environments, including scenes with abruptly dynamic objects.
* 8 pages, 7 figures. S. Song, H. Lim, A. J. Lee and H. Myung, "DynaVINS++: Robust Visual-Inertial State Estimator in Dynamic Environments by Adaptive Truncated Least Squares and Stable State Recovery," in IEEE Robotics and Automation Letters, vol. 9, no. 10, pp. 9127-9134, Oct. 2024
Obstacle-Aware Quadrupedal Locomotion With Resilient Multi-Modal Reinforcement Learning
Sep 29, 2024
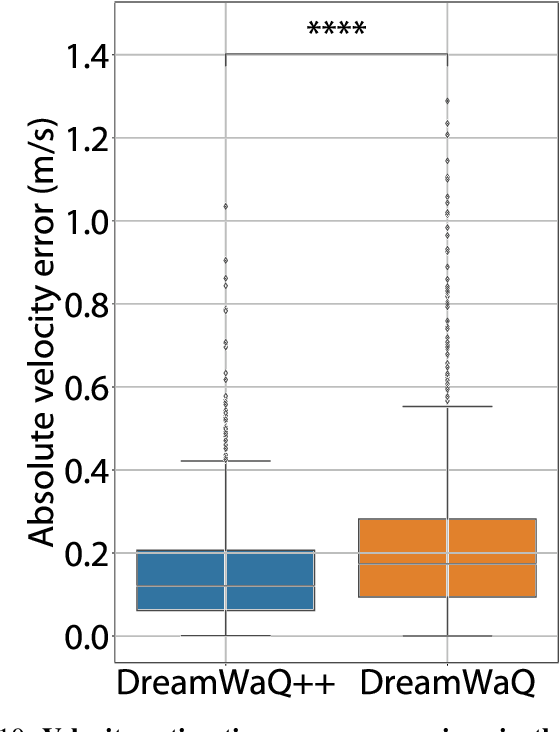


Quadrupedal robots hold promising potential for applications in navigating cluttered environments with resilience akin to their animal counterparts. However, their floating base configuration makes them vulnerable to real-world uncertainties, yielding substantial challenges in their locomotion control. Deep reinforcement learning has become one of the plausible alternatives for realizing a robust locomotion controller. However, the approaches that rely solely on proprioception sacrifice collision-free locomotion because they require front-feet contact to detect the presence of stairs to adapt the locomotion gait. Meanwhile, incorporating exteroception necessitates a precisely modeled map observed by exteroceptive sensors over a period of time. Therefore, this work proposes a novel method to fuse proprioception and exteroception featuring a resilient multi-modal reinforcement learning. The proposed method yields a controller that showcases agile locomotion performance on a quadrupedal robot over a myriad of real-world courses, including rough terrains, steep slopes, and high-rise stairs, while retaining its robustness against out-of-distribution situations.
HeLiMOS: A Dataset for Moving Object Segmentation in 3D Point Clouds From Heterogeneous LiDAR Sensors
Aug 12, 2024
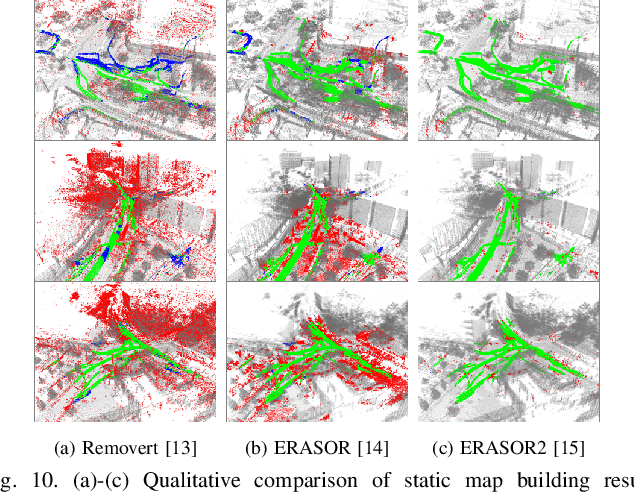
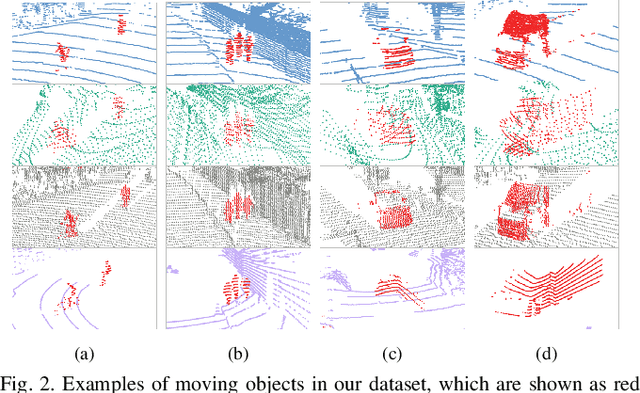

Moving object segmentation (MOS) using a 3D light detection and ranging (LiDAR) sensor is crucial for scene understanding and identification of moving objects. Despite the availability of various types of 3D LiDAR sensors in the market, MOS research still predominantly focuses on 3D point clouds from mechanically spinning omnidirectional LiDAR sensors. Thus, we are, for example, lacking a dataset with MOS labels for point clouds from solid-state LiDAR sensors which have irregular scanning patterns. In this paper, we present a labeled dataset, called \textit{HeLiMOS}, that enables to test MOS approaches on four heterogeneous LiDAR sensors, including two solid-state LiDAR sensors. Furthermore, we introduce a novel automatic labeling method to substantially reduce the labeling effort required from human annotators. To this end, our framework exploits an instance-aware static map building approach and tracking-based false label filtering. Finally, we provide experimental results regarding the performance of commonly used state-of-the-art MOS approaches on HeLiMOS that suggest a new direction for a sensor-agnostic MOS, which generally works regardless of the type of LiDAR sensors used to capture 3D point clouds. Our dataset is available at https://sites.google.com/view/helimos.