 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaVINS++: Robust Visual-Inertial State Estimator in Dynamic Environments by Adaptive Truncated Least Squares and Stable State Recovery
Oct 20, 2024Despite extensive research in robust visual-inertial navigation systems~(VINS) in dynamic environments, many approaches remain vulnerable to objects that suddenly start moving, which are referred to as \textit{abruptly dynamic objects}. In addition, most approaches have considered the effect of dynamic objects only at the feature association level. In this study, we observed that the state estimation diverges when errors from false correspondences owing to moving objects incorrectly propagate into the IMU bias terms. To overcome these problems, we propose a robust VINS framework called \mbox{\textit{DynaVINS++}}, which employs a) adaptive truncated least square method that adaptively adjusts the truncation range using both feature association and IMU preintegration to effectively minimize the effect of the dynamic objects while reducing the computational cost, and b)~stable state recovery with bias consistency check to correct misestimated IMU bias and to prevent the divergence caused by abruptly dynamic objects. As verified in both public and real-world datasets, our approach shows promising performance in dynamic environments, including scenes with abruptly dynamic objects.
* 8 pages, 7 figures. S. Song, H. Lim, A. J. Lee and H. Myung, "DynaVINS++: Robust Visual-Inertial State Estimator in Dynamic Environments by Adaptive Truncated Least Squares and Stable State Recovery," in IEEE Robotics and Automation Letters, vol. 9, no. 10, pp. 9127-9134, Oct. 2024
$^2$: LiDAR-Camera Loop Constraints For Cross-Modal Place Recognition
Apr 17, 2023Localization has been a challenging task for autonomous navigation. A loop detection algorithm must overcome environmental changes for the place recognition and re-localization of robots. Therefore, deep learning has been extensively studied for the consistent transformation of measurements into localization descriptors. Street view images are easily accessible; however, images are vulnerable to appearance changes. LiDAR can robustly provide precise structural information. However, constructing a point cloud database is expensive, and point clouds exist only in limited places. Different from previous works that train networks to produce shared embedding directly between the 2D image and 3D point cloud, we transform both data into 2.5D depth images for matching. In this work, we propose a novel cross-matching method, called (LC)$^2$, for achieving LiDAR localization without a prior point cloud map. To this end, LiDAR measurements are expressed in the form of range images before matching them to reduce the modality discrepancy. Subsequently, the network is trained to extract localization descriptors from disparity and range images. Next, the best matches are employed as a loop factor in a pose graph. Using public datasets that include multiple sessions in significantly different lighting conditions, we demonstrated that LiDAR-based navigation systems could be optimized from image databases and vice versa.
DynaVINS: A Visual-Inertial SLAM for Dynamic Environments
Aug 24, 2022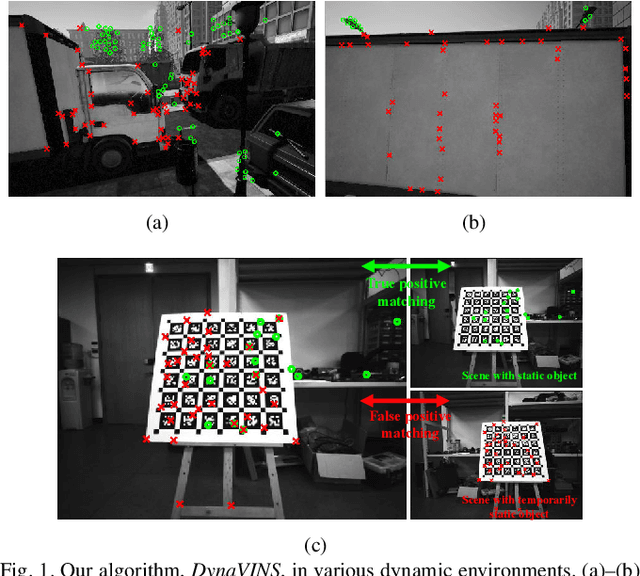
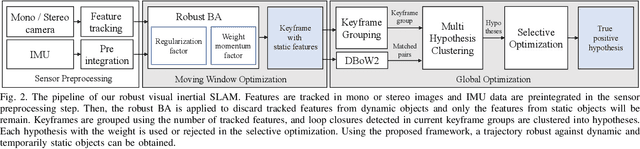
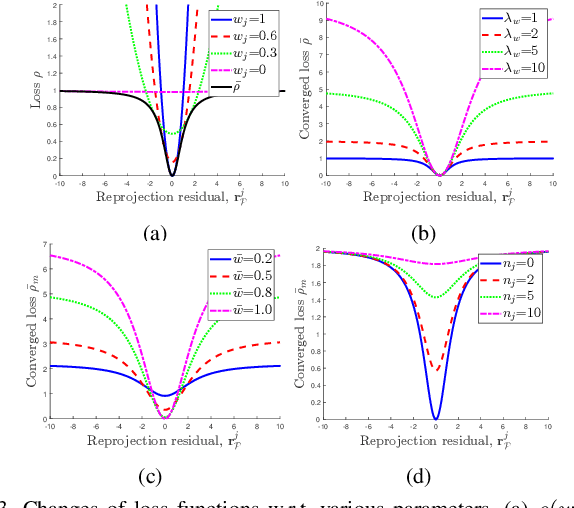
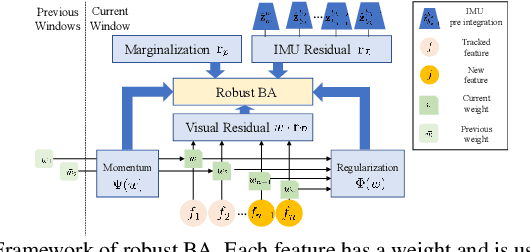
Visual inertial odometry and SLAM algorithms are widely used in various fields, such as service robots, drones, and autonomous vehicles. Most of the SLAM algorithms are based on assumption that landmarks are static. However, in the real-world, various dynamic objects exist, and they degrade the pose estimation accuracy. In addition, temporarily static objects, which are static during observation but move when they are out of sight, trigger false positive loop closings. To overcome these problems, we propose a novel visual-inertial SLAM framework, called DynaVINS, which is robust against both dynamic objects and temporarily static objects. In our framework, we first present a robust bundle adjustment that could reject the features from dynamic objects by leveraging pose priors estimated by the IMU preintegration. Then, a keyframe grouping and a multi-hypothesis-based constraints grouping methods are proposed to reduce the effect of temporarily static objects in the loop closing. Subsequently, we evaluated our method in a public dataset that contains numerous dynamic objects. Finally, the experimental results corroborate that our DynaVINS has promising performance compared with other state-of-the-art methods by successfully rejecting the effect of dynamic and temporarily static objects. Our code is available at https://github.com/url-kaist/dynaVINS.