 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChamelion: Reliable Change Detection for Long-Term LiDAR Mapping in Transient Environments
Feb 09, 2026Online change detection is crucial for mobile robots to efficiently navigate through dynamic environments. Detecting changes in transient settings, such as active construction sites or frequently reconfigured indoor spaces, is particularly challenging due to frequent occlusions and spatiotemporal variations. Existing approaches often struggle to detect changes and fail to update the map across different observations. To address these limitations, we propose a dual-head network designed for online change detection and long-term map maintenance. A key difficulty in this task is the collection and alignment of real-world data, as manually registering structural differences over time is both labor-intensive and often impractical. To overcome this, we develop a data augmentation strategy that synthesizes structural changes by importing elements from different scenes, enabling effective model training without the need for extensive ground-truth annotations. Experiments conducted at real-world construction sites and in indoor office environments demonstrate that our approach generalizes well across diverse scenarios, achieving efficient and accurate map updates.\resubmit{Our source code and additional material are available at: https://chamelion-pages.github.io/.
DynaVINS++: Robust Visual-Inertial State Estimator in Dynamic Environments by Adaptive Truncated Least Squares and Stable State Recovery
Oct 20, 2024Despite extensive research in robust visual-inertial navigation systems~(VINS) in dynamic environments, many approaches remain vulnerable to objects that suddenly start moving, which are referred to as \textit{abruptly dynamic objects}. In addition, most approaches have considered the effect of dynamic objects only at the feature association level. In this study, we observed that the state estimation diverges when errors from false correspondences owing to moving objects incorrectly propagate into the IMU bias terms. To overcome these problems, we propose a robust VINS framework called \mbox{\textit{DynaVINS++}}, which employs a) adaptive truncated least square method that adaptively adjusts the truncation range using both feature association and IMU preintegration to effectively minimize the effect of the dynamic objects while reducing the computational cost, and b)~stable state recovery with bias consistency check to correct misestimated IMU bias and to prevent the divergence caused by abruptly dynamic objects. As verified in both public and real-world datasets, our approach shows promising performance in dynamic environments, including scenes with abruptly dynamic objects.
* 8 pages, 7 figures. S. Song, H. Lim, A. J. Lee and H. Myung, "DynaVINS++: Robust Visual-Inertial State Estimator in Dynamic Environments by Adaptive Truncated Least Squares and Stable State Recovery," in IEEE Robotics and Automation Letters, vol. 9, no. 10, pp. 9127-9134, Oct. 2024
$^2$: LiDAR-Camera Loop Constraints For Cross-Modal Place Recognition
Apr 17, 2023Localization has been a challenging task for autonomous navigation. A loop detection algorithm must overcome environmental changes for the place recognition and re-localization of robots. Therefore, deep learning has been extensively studied for the consistent transformation of measurements into localization descriptors. Street view images are easily accessible; however, images are vulnerable to appearance changes. LiDAR can robustly provide precise structural information. However, constructing a point cloud database is expensive, and point clouds exist only in limited places. Different from previous works that train networks to produce shared embedding directly between the 2D image and 3D point cloud, we transform both data into 2.5D depth images for matching. In this work, we propose a novel cross-matching method, called (LC)$^2$, for achieving LiDAR localization without a prior point cloud map. To this end, LiDAR measurements are expressed in the form of range images before matching them to reduce the modality discrepancy. Subsequently, the network is trained to extract localization descriptors from disparity and range images. Next, the best matches are employed as a loop factor in a pose graph. Using public datasets that include multiple sessions in significantly different lighting conditions, we demonstrated that LiDAR-based navigation systems could be optimized from image databases and vice versa.
Low-cost Thermal Mapping for Concrete Heat Monitoring
Nov 04, 2022Robotics has been widely applied in smart construction for generating the digital twin or for autonomous inspection of construction sites. For example, for thermal inspection during concrete curing, continual monitoring of the concrete temperature is required to ensure concrete strength and to avoid cracks. However, buildings are typically too large to be monitored by installing fixed thermal cameras, and post-processing is required to compute the accumulated heat of each measurement point. Thus, by using an autonomous monitoring system with the capability of long-term thermal mapping at a large construction site, both cost-effectiveness and a precise safety margin of the curing period estimation can be acquired. Therefore, this study proposes a low-cost thermal mapping system consisting of a 2D range scanner attached to a consumer-level inertial measurement unit and a thermal camera for automated heat monitoring in construction using mobile robots.
DynaVINS: A Visual-Inertial SLAM for Dynamic Environments
Aug 24, 2022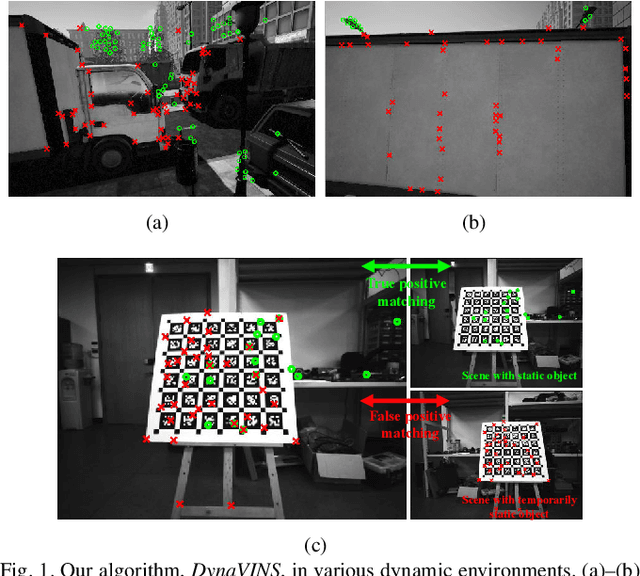
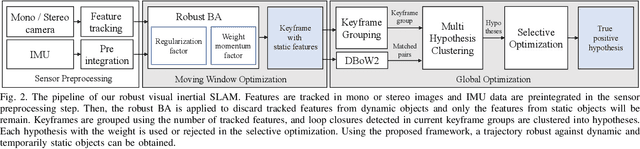
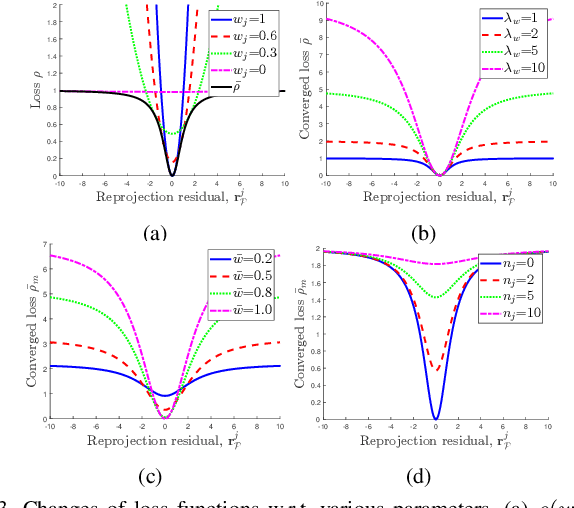
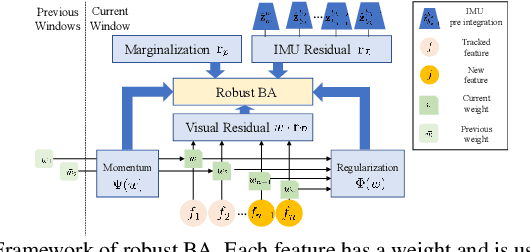
Visual inertial odometry and SLAM algorithms are widely used in various fields, such as service robots, drones, and autonomous vehicles. Most of the SLAM algorithms are based on assumption that landmarks are static. However, in the real-world, various dynamic objects exist, and they degrade the pose estimation accuracy. In addition, temporarily static objects, which are static during observation but move when they are out of sight, trigger false positive loop closings. To overcome these problems, we propose a novel visual-inertial SLAM framework, called DynaVINS, which is robust against both dynamic objects and temporarily static objects. In our framework, we first present a robust bundle adjustment that could reject the features from dynamic objects by leveraging pose priors estimated by the IMU preintegration. Then, a keyframe grouping and a multi-hypothesis-based constraints grouping methods are proposed to reduce the effect of temporarily static objects in the loop closing. Subsequently, we evaluated our method in a public dataset that contains numerous dynamic objects. Finally, the experimental results corroborate that our DynaVINS has promising performance compared with other state-of-the-art methods by successfully rejecting the effect of dynamic and temporarily static objects. Our code is available at https://github.com/url-kaist/dynaVINS.
eCDT: Event Clustering for Simultaneous Feature Detection and Tracking-
Jul 20, 2022

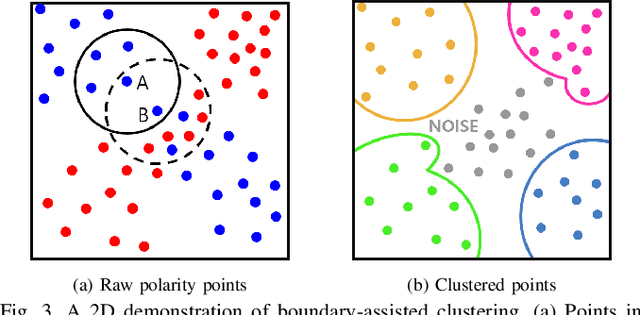

Contrary to other standard cameras, event cameras interpret the world in an entirely different manner; as a collection of asynchronous events. Despite event camera's unique data output, many event feature detection and tracking algorithms have shown significant progress by making detours to frame-based data representations. This paper questions the need to do so and proposes a novel event data-friendly method that achieve simultaneous feature detection and tracking, called event Clustering-based Detection and Tracking (eCDT). Our method employs a novel clustering method, named as k-NN Classifier-based Spatial Clustering and Applications with Noise (KCSCAN), to cluster adjacent polarity events to retrieve event trajectories.With the aid of a Head and Tail Descriptor Matching process, event clusters that reappear in a different polarity are continually tracked, elongating the feature tracks. Thanks to our clustering approach in spatio-temporal space, our method automatically solves feature detection and feature tracking simultaneously. Also, eCDT can extract feature tracks at any frequency with an adjustable time window, which does not corrupt the high temporal resolution of the original event data. Our method achieves 30% better feature tracking ages compared with the state-of-the-art approach while also having a low error approximately equal to it.
ViViD++: Vision for Visibility Dataset
Apr 14, 2022
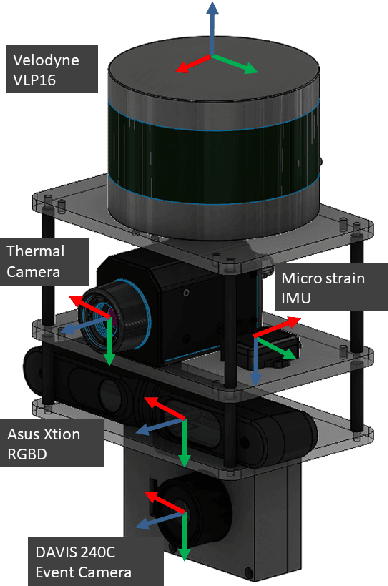


In this paper, we present a dataset capturing diverse visual data formats that target varying luminance conditions. While RGB cameras provide nourishing and intuitive information, changes in lighting conditions potentially result in catastrophic failure for robotic applications based on vision sensors. Approaches overcoming illumination problems have included developing more robust algorithms or other types of visual sensors, such as thermal and event cameras. Despite the alternative sensors' potential, there still are few datasets with alternative vision sensors. Thus, we provided a dataset recorded from alternative vision sensors, by handheld or mounted on a car, repeatedly in the same space but in different conditions. We aim to acquire visible information from co-aligned alternative vision sensors. Our sensor system collects data more independently from visible light intensity by measuring the amount of infrared dissipation, depth by structured reflection, and instantaneous temporal changes in luminance. We provide these measurements along with inertial sensors and ground-truth for developing robust visual SLAM under poor illumination. The full dataset is available at: https://visibilitydataset.github.io/