 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoison Once, Exploit Forever: Environment-Injected Memory Poisoning Attacks on Web Agents
Apr 03, 2026Memory makes LLM-based web agents personalized, powerful, yet exploitable. By storing past interactions to personalize future tasks, agents inadvertently create a persistent attack surface that spans websites and sessions. While existing security research on memory assumes attackers can directly inject into memory storage or exploit shared memory across users, we present a more realistic threat model: contamination through environmental observation alone. We introduce Environment-injected Trajectory-based Agent Memory Poisoning (eTAMP), the first attack to achieve cross-session, cross-site compromise without requiring direct memory access. A single contaminated observation (e.g., viewing a manipulated product page) silently poisons an agent's memory and activates during future tasks on different websites, bypassing permission-based defenses. Our experiments on (Visual)WebArena reveal two key findings. First, eTAMP achieves substantial attack success rates: up to 32.5% on GPT-5-mini, 23.4% on GPT-5.2, and 19.5% on GPT-OSS-120B. Second, we discover Frustration Exploitation: agents under environmental stress become dramatically more susceptible, with ASR increasing up to 8 times when agents struggle with dropped clicks or garbled text. Notably, more capable models are not more secure. GPT-5.2 shows substantial vulnerability despite superior task performance. With the rise of AI browsers like OpenClaw, ChatGPT Atlas, and Perplexity Comet, our findings underscore the urgent need for defenses against environment-injected memory poisoning.
DreamFlow: Local Navigation Beyond Observation via Conditional Flow Matching in the Latent Space
Mar 03, 2026Local navigation in cluttered environments often suffers from dense obstacles and frequent local minima. Conventional local planners rely on heuristics and are prone to failure, while deep reinforcement learning(DRL)based approaches provide adaptability but are constrained by limited onboard sensing. These limitations lead to navigation failures because the robot cannot perceive structures outside its field of view. In this paper, we propose DreamFlow, a DRL-based local navigation framework that extends the robot's perceptual horizon through conditional flow matching(CFM). The proposed CFM based prediction module learns probabilistic mapping between local height map latent representation and broader spatial representation conditioned on navigation context. This enables the navigation policy to predict unobserved environmental features and proactively avoid potential local minima. Experimental results demonstrate that DreamFlow outperforms existing methods in terms of latent prediction accuracy and navigation performance in simulation. The proposed method was further validated in cluttered real world environments with a quadrupedal robot. The project page is available at https://dreamflow-icra.github.io.
LocoVLM: Grounding Vision and Language for Adapting Versatile Legged Locomotion Policies
Feb 11, 2026Recent advances in legged locomotion learning are still dominated by the utilization of geometric representations of the environment, limiting the robot's capability to respond to higher-level semantics such as human instructions. To address this limitation, we propose a novel approach that integrates high-level commonsense reasoning from foundation models into the process of legged locomotion adaptation. Specifically, our method utilizes a pre-trained large language model to synthesize an instruction-grounded skill database tailored for legged robots. A pre-trained vision-language model is employed to extract high-level environmental semantics and ground them within the skill database, enabling real-time skill advisories for the robot. To facilitate versatile skill control, we train a style-conditioned policy capable of generating diverse and robust locomotion skills with high fidelity to specified styles. To the best of our knowledge, this is the first work to demonstrate real-time adaptation of legged locomotion using high-level reasoning from environmental semantics and instructions with instruction-following accuracy of up to 87% without the need for online query to on-the-cloud foundation models.
DreamFLEX: Learning Fault-Aware Quadrupedal Locomotion Controller for Anomaly Situation in Rough Terrains
Feb 09, 2025



Recent advances in quadrupedal robots have demonstrated impressive agility and the ability to traverse diverse terrains. However, hardware issues, such as motor overheating or joint locking, may occur during long-distance walking or traversing through rough terrains leading to locomotion failures. Although several studies have proposed fault-tolerant control methods for quadrupedal robots, there are still challenges in traversing unstructured terrains. In this paper, we propose DreamFLEX, a robust fault-tolerant locomotion controller that enables a quadrupedal robot to traverse complex environments even under joint failure conditions. DreamFLEX integrates an explicit failure estimation and modulation network that jointly estimates the robot's joint fault vector and utilizes this information to adapt the locomotion pattern to faulty conditions in real-time, enabling quadrupedal robots to maintain stability and performance in rough terrains. Experimental results demonstrate that DreamFLEX outperforms existing methods in both simulation and real-world scenarios, effectively managing hardware failures while maintaining robust locomotion performance.
TRG-planner: Traversal Risk Graph-Based Path Planning in Unstructured Environments for Safe and Efficient Navigation
Jan 03, 2025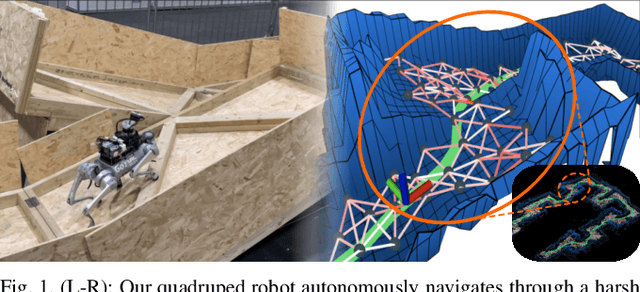
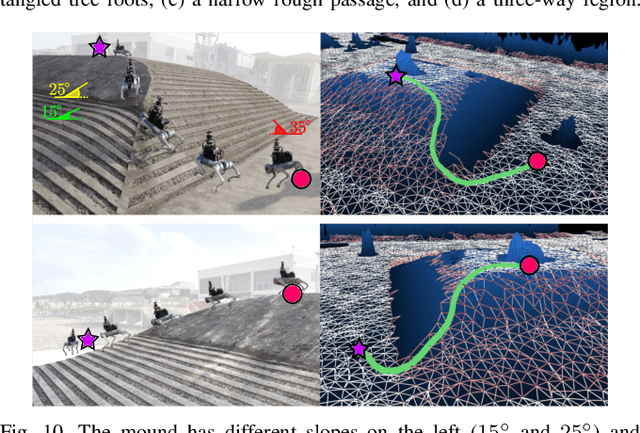
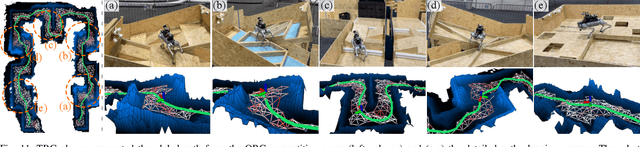
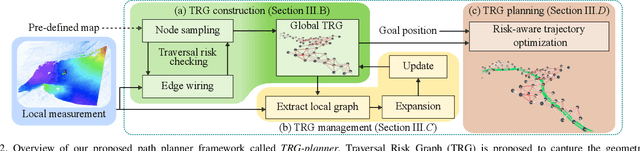
Unstructured environments such as mountains, caves, construction sites, or disaster areas are challenging for autonomous navigation because of terrain irregularities. In particular, it is crucial to plan a path to avoid risky terrain and reach the goal quickly and safely. In this paper, we propose a method for safe and distance-efficient path planning, leveraging Traversal Risk Graph (TRG), a novel graph representation that takes into account geometric traversability of the terrain. TRG nodes represent stability and reachability of the terrain, while edges represent relative traversal risk-weighted path candidates. Additionally, TRG is constructed in a wavefront propagation manner and managed hierarchically, enabling real-time planning even in large-scale environments. Lastly, we formulate a graph optimization problem on TRG that leads the robot to navigate by prioritizing both safe and short paths. Our approach demonstrated superior safety, distance efficiency, and fast processing time compared to the conventional methods. It was also validated in several real-world experiments using a quadrupedal robot. Notably, TRG-planner contributed as the global path planner of an autonomous navigation framework for the DreamSTEP team, which won the Quadruped Robot Challenge at ICRA 2023. The project page is available at https://trg-planner.github.io .
TRIP: Terrain Traversability Mapping With Risk-Aware Prediction for Enhanced Online Quadrupedal Robot Navigation
Nov 26, 2024



Accurate traversability estimation using an online dense terrain map is crucial for safe navigation in challenging environments like construction and disaster areas. However, traversability estimation for legged robots on rough terrains faces substantial challenges owing to limited terrain information caused by restricted field-of-view, and data occlusion and sparsity. To robustly map traversable regions, we introduce terrain traversability mapping with risk-aware prediction (TRIP). TRIP reconstructs the terrain maps while predicting multi-modal traversability risks, enhancing online autonomous navigation with the following contributions. Firstly, estimating steppability in a spherical projection space allows for addressing data sparsity while accomodating scalable terrain properties. Moreover, the proposed traversability-aware Bayesian generalized kernel (T-BGK)-based inference method enhances terrain completion accuracy and efficiency. Lastly, leveraging the steppability-based Mahalanobis distance contributes to robustness against outliers and dynamic elements, ultimately yielding a static terrain traversability map. As verified in both public and our in-house datasets, our TRIP shows significant performance increases in terms of terrain reconstruction and navigation map. A demo video that demonstrates its feasibility as an integral component within an onboard online autonomous navigation system for quadruped robots is available at https://youtu.be/d7HlqAP4l0c.
Conditional Synthesis of 3D Molecules with Time Correction Sampler
Nov 01, 2024Diffusion models have demonstrated remarkable success in various domains, including molecular generation. However, conditional molecular generation remains a fundamental challenge due to an intrinsic trade-off between targeting specific chemical properties and generating meaningful samples from the data distribution. In this work, we present Time-Aware Conditional Synthesis (TACS), a novel approach to conditional generation on diffusion models. It integrates adaptively controlled plug-and-play "online" guidance into a diffusion model, driving samples toward the desired properties while maintaining validity and stability. A key component of our algorithm is our new type of diffusion sampler, Time Correction Sampler (TCS), which is used to control guidance and ensure that the generated molecules remain on the correct manifold at each reverse step of the diffusion process at the same time. Our proposed method demonstrates significant performance in conditional 3D molecular generation and offers a promising approach towards inverse molecular design, potentially facilitating advancements in drug discovery, materials science, and other related fields.
Obstacle-Aware Quadrupedal Locomotion With Resilient Multi-Modal Reinforcement Learning
Sep 29, 2024


Quadrupedal robots hold promising potential for applications in navigating cluttered environments with resilience akin to their animal counterparts. However, their floating base configuration makes them vulnerable to real-world uncertainties, yielding substantial challenges in their locomotion control. Deep reinforcement learning has become one of the plausible alternatives for realizing a robust locomotion controller. However, the approaches that rely solely on proprioception sacrifice collision-free locomotion because they require front-feet contact to detect the presence of stairs to adapt the locomotion gait. Meanwhile, incorporating exteroception necessitates a precisely modeled map observed by exteroceptive sensors over a period of time. Therefore, this work proposes a novel method to fuse proprioception and exteroception featuring a resilient multi-modal reinforcement learning. The proposed method yields a controller that showcases agile locomotion performance on a quadrupedal robot over a myriad of real-world courses, including rough terrains, steep slopes, and high-rise stairs, while retaining its robustness against out-of-distribution situations.
B-TMS: Bayesian Traversable Terrain Modeling and Segmentation Across 3D LiDAR Scans and Maps for Enhanced Off-Road Navigation
Jun 26, 2024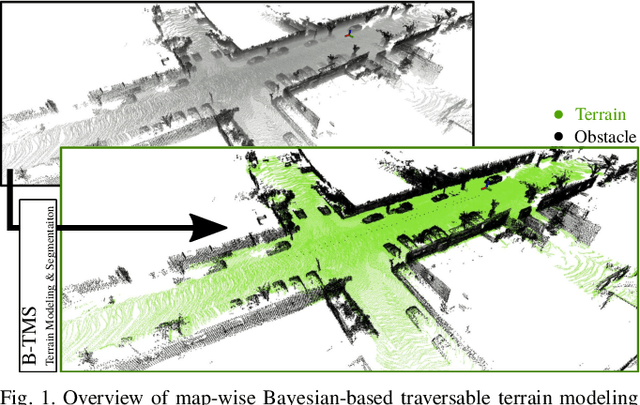

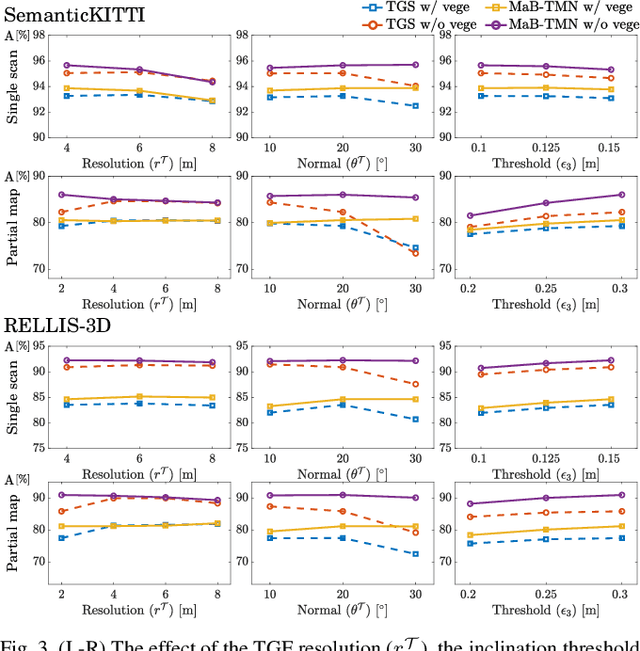
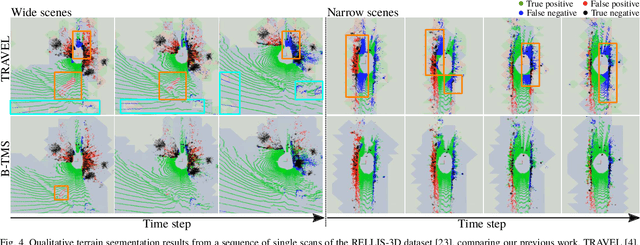
Recognizing traversable terrain from 3D point cloud data is critical, as it directly impacts the performance of autonomous navigation in off-road environments. However, existing segmentation algorithms often struggle with challenges related to changes in data distribution, environmental specificity, and sensor variations. Moreover, when encountering sunken areas, their performance is frequently compromised, and they may even fail to recognize them. To address these challenges, we introduce B-TMS, a novel approach that performs map-wise terrain modeling and segmentation by utilizing Bayesian generalized kernel (BGK) within the graph structure known as the tri-grid field (TGF). Our experiments encompass various data distributions, ranging from single scans to partial maps, utilizing both public datasets representing urban scenes and off-road environments, and our own dataset acquired from extremely bumpy terrains. Our results demonstrate notable contributions, particularly in terms of robustness to data distribution variations, adaptability to diverse environmental conditions, and resilience against the challenges associated with parameter changes.
MATTER: Memory-Augmented Transformer Using Heterogeneous Knowledge Sources
Jun 07, 2024



Leveraging external knowledge is crucial for achieving high performance in knowledge-intensive tasks, such as question answering. The retrieve-and-read approach is widely adopted for integrating external knowledge into a language model. However, this approach suffers from increased computational cost and latency due to the long context length, which grows proportionally with the number of retrieved knowledge. Furthermore, existing retrieval-augmented models typically retrieve information from a single type of knowledge source, limiting their scalability to diverse knowledge sources with varying structures. In this work, we introduce an efficient memory-augmented transformer called MATTER, designed to retrieve relevant knowledge from multiple heterogeneous knowledge sources. Specifically, our model retrieves and reads from both unstructured sources (paragraphs) and semi-structured sources (QA pairs) in the form of fixed-length neural memories. We demonstrate that our model outperforms existing efficient retrieval-augmented models on popular QA benchmarks in terms of both accuracy and speed. Furthermore, MATTER achieves competitive results compared to conventional read-and-retrieve models while having 100x throughput during inference.