 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Content Preservation in Text Style Transfer Using Reverse Attention and Conditional Layer Normalization
Aug 01, 2021

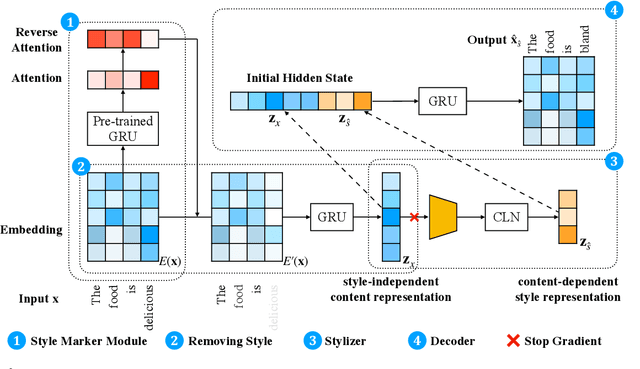
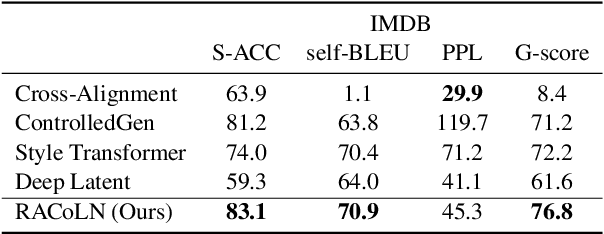
Text style transfer aims to alter the style (e.g., sentiment) of a sentence while preserving its content. A common approach is to map a given sentence to content representation that is free of style, and the content representation is fed to a decoder with a target style. Previous methods in filtering style completely remove tokens with style at the token level, which incurs the loss of content information. In this paper, we propose to enhance content preservation by implicitly removing the style information of each token with reverse attention, and thereby retain the content. Furthermore, we fuse content information when building the target style representation, making it dynamic with respect to the content. Our method creates not only style-independent content representation, but also content-dependent style representation in transferring style. Empirical results show that our method outperforms the state-of-the-art baselines by a large margin in terms of content preservation. In addition, it is also competitive in terms of style transfer accuracy and fluency.
DeepRapper: Neural Rap Generation with Rhyme and Rhythm Modeling
Jul 05, 2021
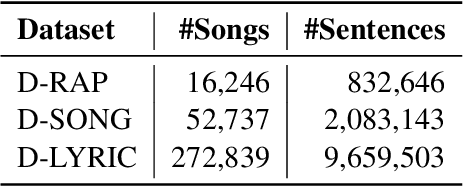
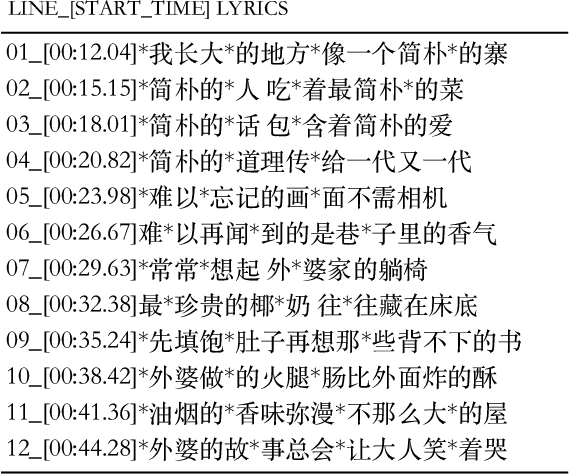

Rap generation, which aims to produce lyrics and corresponding singing beats, needs to model both rhymes and rhythms. Previous works for rap generation focused on rhyming lyrics but ignored rhythmic beats, which are important for rap performance. In this paper, we develop DeepRapper, a Transformer-based rap generation system that can model both rhymes and rhythms. Since there is no available rap dataset with rhythmic beats, we develop a data mining pipeline to collect a large-scale rap dataset, which includes a large number of rap songs with aligned lyrics and rhythmic beats. Second, we design a Transformer-based autoregressive language model which carefully models rhymes and rhythms. Specifically, we generate lyrics in the reverse order with rhyme representation and constraint for rhyme enhancement and insert a beat symbol into lyrics for rhythm/beat modeling. To our knowledge, DeepRapper is the first system to generate rap with both rhymes and rhythms. Both objective and subjective evaluations demonstrate that DeepRapper generates creative and high-quality raps with rhymes and rhythms. Code will be released on GitHub.
Response-Anticipated Memory for On-Demand Knowledge Integration in Response Generation
May 13, 2020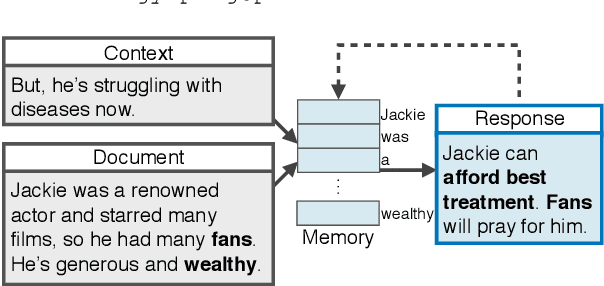
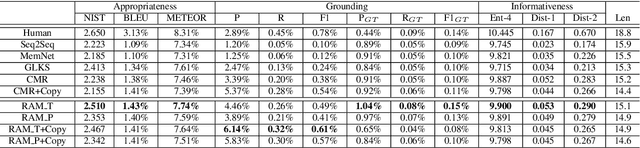
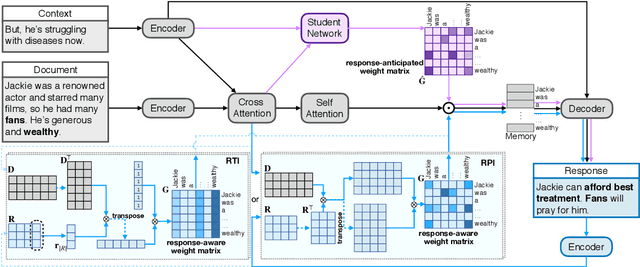

Neural conversation models are known to generate appropriate but non-informative responses in general. A scenario where informativeness can be significantly enhanced is Conversing by Reading (CbR), where conversations take place with respect to a given external document. In previous work, the external document is utilized by (1) creating a context-aware document memory that integrates information from the document and the conversational context, and then (2) generating responses referring to the memory. In this paper, we propose to create the document memory with some anticipated responses in mind. This is achieved using a teacher-student framework. The teacher is given the external document, the context, and the ground-truth response, and learns how to build a response-aware document memory from three sources of information. The student learns to construct a response-anticipated document memory from the first two sources, and the teacher's insight on memory creation. Empirical results show that our model outperforms the previous state-of-the-art for the CbR task.
Not All Attention Is Needed: Gated Attention Network for Sequence Data
Dec 01, 2019
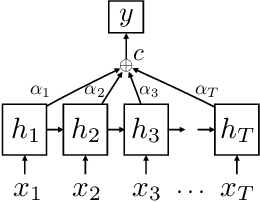
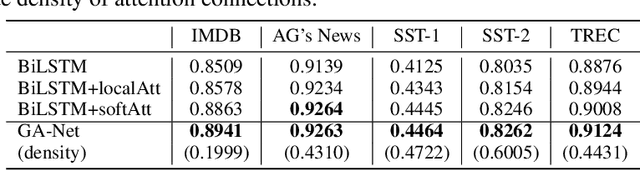
Although deep neural networks generally have fixed network structures, the concept of dynamic mechanism has drawn more and more attention in recent years. Attention mechanisms compute input-dependent dynamic attention weights for aggregating a sequence of hidden states. Dynamic network configuration in convolutional neural networks (CNNs) selectively activates only part of the network at a time for different inputs. In this paper, we combine the two dynamic mechanisms for text classification tasks. Traditional attention mechanisms attend to the whole sequence of hidden states for an input sentence, while in most cases not all attention is needed especially for long sequences. We propose a novel method called Gated Attention Network (GA-Net) to dynamically select a subset of elements to attend to using an auxiliary network, and compute attention weights to aggregate the selected elements. It avoids a significant amount of unnecessary computation on unattended elements, and allows the model to pay attention to important parts of the sequence. Experiments in various datasets show that the proposed method achieves better performance compared with all baseline models with global or local attention while requiring less computation and achieving better interpretability. It is also promising to extend the idea to more complex attention-based models, such as transformers and seq-to-seq models.