 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance between Relevant Information Pieces Causes Bias in Long-Context LLMs
Oct 18, 2024



Positional bias in large language models (LLMs) hinders their ability to effectively process long inputs. A prominent example is the "lost in the middle" phenomenon, where LLMs struggle to utilize relevant information situated in the middle of the input. While prior research primarily focuses on single pieces of relevant information, real-world applications often involve multiple relevant information pieces. To bridge this gap, we present LongPiBench, a benchmark designed to assess positional bias involving multiple pieces of relevant information. Thorough experiments are conducted with five commercial and six open-source models. These experiments reveal that while most current models are robust against the "lost in the middle" issue, there exist significant biases related to the spacing of relevant information pieces. These findings highlight the importance of evaluating and reducing positional biases to advance LLM's capabilities.
TIS-DPO: Token-level Importance Sampling for Direct Preference Optimization With Estimated Weights
Oct 06, 2024

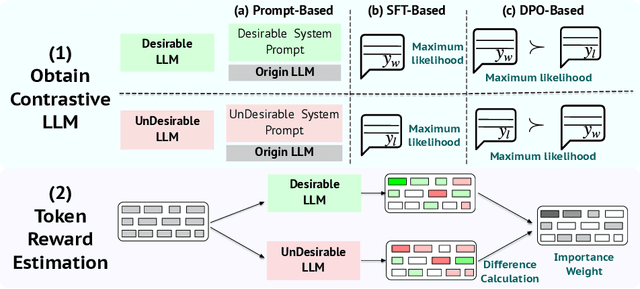
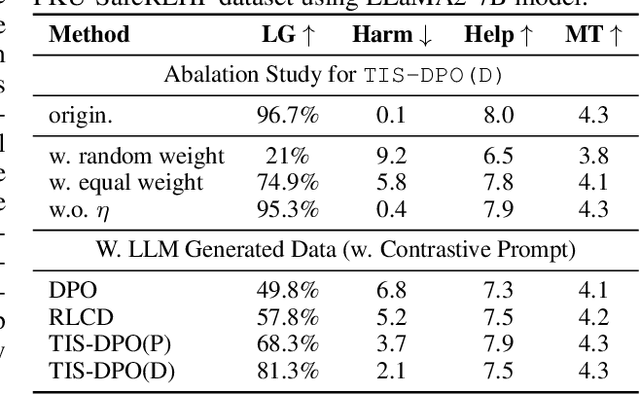
Direct Preference Optimization (DPO) has been widely adopted for preference alignment of Large Language Models (LLMs) due to its simplicity and effectiveness. However, DPO is derived as a bandit problem in which the whole response is treated as a single arm, ignoring the importance differences between tokens, which may affect optimization efficiency and make it difficult to achieve optimal results. In this work, we propose that the optimal data for DPO has equal expected rewards for each token in winning and losing responses, as there is no difference in token importance. However, since the optimal dataset is unavailable in practice, we propose using the original dataset for importance sampling to achieve unbiased optimization. Accordingly, we propose a token-level importance sampling DPO objective named TIS-DPO that assigns importance weights to each token based on its reward. Inspired by previous works, we estimate the token importance weights using the difference in prediction probabilities from a pair of contrastive LLMs. We explore three methods to construct these contrastive LLMs: (1) guiding the original LLM with contrastive prompts, (2) training two separate LLMs using winning and losing responses, and (3) performing forward and reverse DPO training with winning and losing responses. Experiments show that TIS-DPO significantly outperforms various baseline methods on harmlessness and helpfulness alignment and summarization tasks. We also visualize the estimated weights, demonstrating their ability to identify key token positions.
Exploring Format Consistency for Instruction Tuning
Jul 28, 2023



Instruction tuning has emerged as a promising approach to enhancing large language models in following human instructions. It is shown that increasing the diversity and number of instructions in the training data can consistently enhance generalization performance, which facilitates a recent endeavor to collect various instructions and integrate existing instruction tuning datasets into larger collections. However, different users have their unique ways of expressing instructions, and there often exist variations across different datasets in the instruction styles and formats, i.e., format inconsistency. In this work, we study how format inconsistency may impact the performance of instruction tuning. We propose a framework called "Unified Instruction Tuning" (UIT), which calls OpenAI APIs for automatic format transfer among different instruction tuning datasets. We show that UIT successfully improves the generalization performance on unseen instructions, which highlights the importance of format consistency for instruction tuning. To make the UIT framework more practical, we further propose a novel perplexity-based denoising method to reduce the noise of automatic format transfer. We also train a smaller offline model that achieves comparable format transfer capability than OpenAI APIs to reduce costs in practice.
Learning to Break the Loop: Analyzing and Mitigating Repetitions for Neural Text Generation
Jun 06, 2022
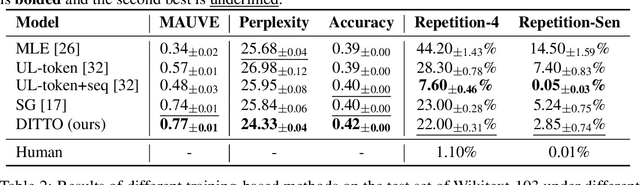
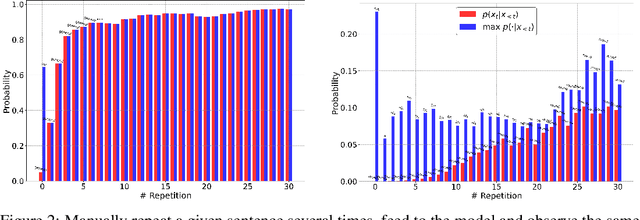
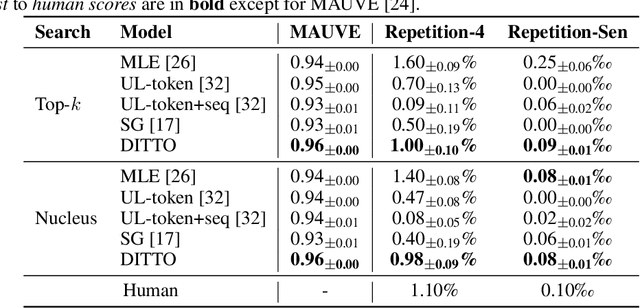
While large-scale neural language models, such as GPT2 and BART, have achieved impressive results on various text generation tasks, they tend to get stuck in undesirable sentence-level loops with maximization-based decoding algorithms (\textit{e.g.}, greedy search). This phenomenon is counter-intuitive since there are few consecutive sentence-level repetitions in human corpora (e.g., 0.02\% in Wikitext-103). To investigate the underlying reasons for generating consecutive sentence-level repetitions, we study the relationship between the probabilities of the repetitive tokens and their previous repetitions in the context. Through our quantitative experiments, we find that 1) Language models have a preference to repeat the previous sentence; 2) The sentence-level repetitions have a \textit{self-reinforcement effect}: the more times a sentence is repeated in the context, the higher the probability of continuing to generate that sentence; 3) The sentences with higher initial probabilities usually have a stronger self-reinforcement effect. Motivated by our findings, we propose a simple and effective training method \textbf{DITTO} (Pseu\underline{D}o-Repet\underline{IT}ion Penaliza\underline{T}i\underline{O}n), where the model learns to penalize probabilities of sentence-level repetitions from pseudo repetitive data. Although our method is motivated by mitigating repetitions, experiments show that DITTO not only mitigates the repetition issue without sacrificing perplexity, but also achieves better generation quality. Extensive experiments on open-ended text generation (Wikitext-103) and text summarization (CNN/DailyMail) demonstrate the generality and effectiveness of our method.
Dialogue Generation on Infrequent Sentence Functions via Structured Meta-Learning
Oct 04, 2020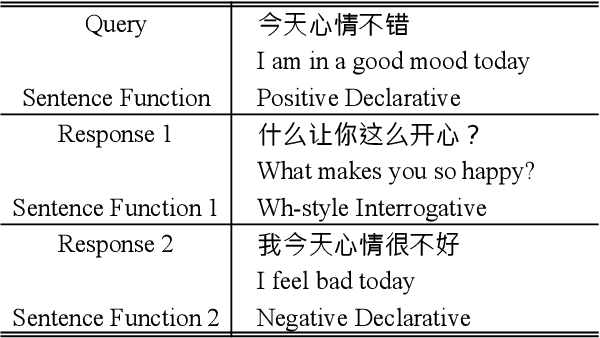


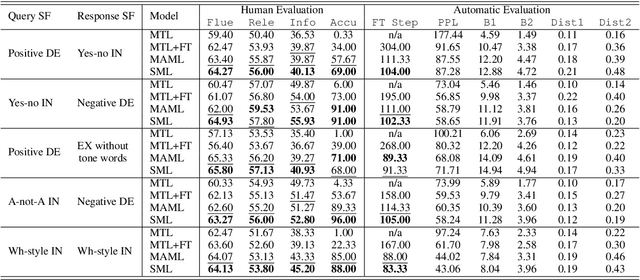
Sentence function is an important linguistic feature indicating the communicative purpose in uttering a sentence. Incorporating sentence functions into conversations has shown improvements in the quality of generated responses. However, the number of utterances for different types of fine-grained sentence functions is extremely imbalanced. Besides a small number of high-resource sentence functions, a large portion of sentence functions is infrequent. Consequently, dialogue generation conditioned on these infrequent sentence functions suffers from data deficiency. In this paper, we investigate a structured meta-learning (SML) approach for dialogue generation on infrequent sentence functions. We treat dialogue generation conditioned on different sentence functions as separate tasks, and apply model-agnostic meta-learning to high-resource sentence functions data. Furthermore, SML enhances meta-learning effectiveness by promoting knowledge customization among different sentence functions but simultaneously preserving knowledge generalization for similar sentence functions. Experimental results demonstrate that SML not only improves the informativeness and relevance of generated responses, but also can generate responses consistent with the target sentence functions.
Profile Consistency Identification for Open-domain Dialogue Agents
Sep 30, 2020
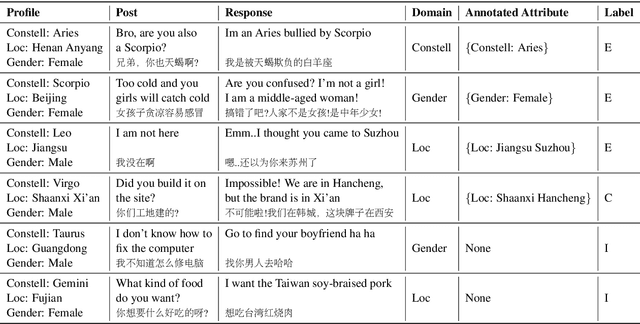
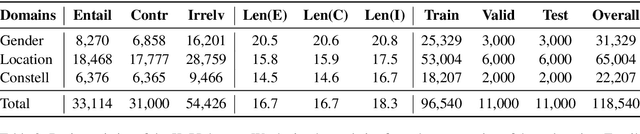
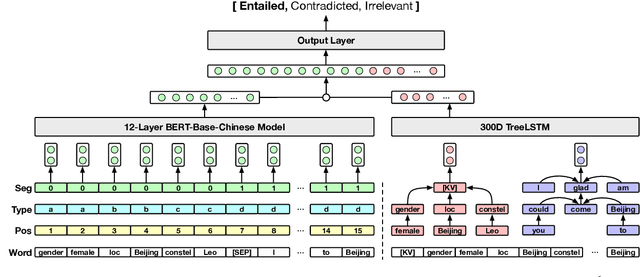
Maintaining a consistent attribute profile is crucial for dialogue agents to naturally converse with humans. Existing studies on improving attribute consistency mainly explored how to incorporate attribute information in the responses, but few efforts have been made to identify the consistency relations between response and attribute profile. To facilitate the study of profile consistency identification, we create a large-scale human-annotated dataset with over 110K single-turn conversations and their key-value attribute profiles. Explicit relation between response and profile is manually labeled. We also propose a key-value structure information enriched BERT model to identify the profile consistency, and it gained improvements over strong baselines. Further evaluations on downstream tasks demonstrate that the profile consistency identification model is conducive for improving dialogue consistency.
Enhancing Dialogue Generation via Multi-Level Contrastive Learning
Sep 19, 2020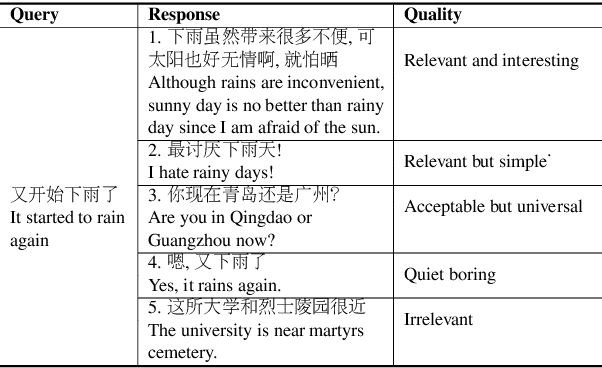
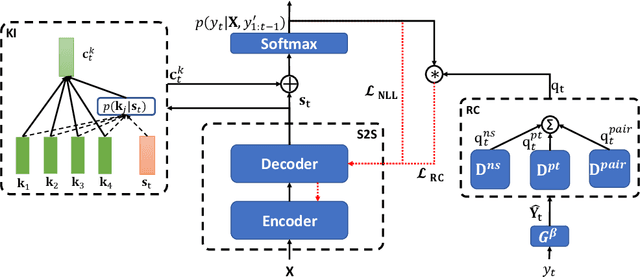
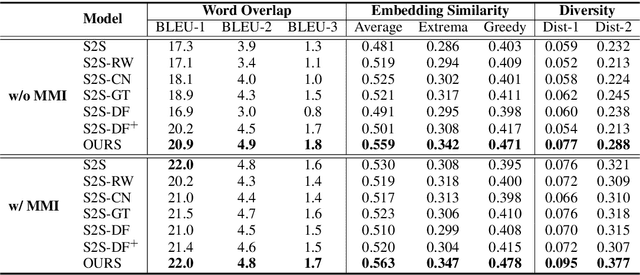

Most of the existing works for dialogue generation are data-driven models trained directly on corpora crawled from websites. They mainly focus on improving the model architecture to produce better responses but pay little attention to considering the quality of the training data contrastively. In this paper, we propose a multi-level contrastive learning paradigm to model the fine-grained quality of the responses with respect to the query. A Rank-aware Calibration (RC) network is designed to construct the multi-level contrastive optimization objectives. Since these objectives are calculated based on the sentence level, which may erroneously encourage/suppress the generation of uninformative/informative words. To tackle this incidental issue, on one hand, we design an exquisite token-level strategy for estimating the instance loss more accurately. On the other hand, we build a Knowledge Inference (KI) component to capture the keyword knowledge from the reference during training and exploit such information to encourage the generation of informative words. We evaluate the proposed model on a carefully annotated dialogue dataset and the results suggest that our model can generate more relevant and diverse responses compared to the baseline models.
Interpretable Real-Time Win Prediction for Honor of Kings, a Popular Mobile MOBA Esport
Sep 04, 2020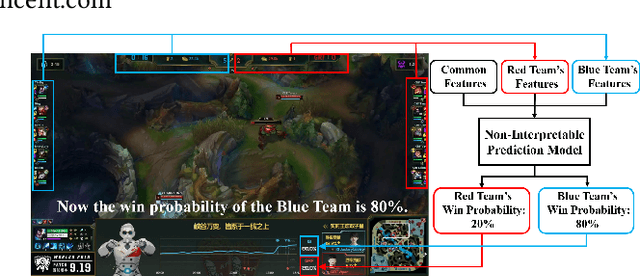

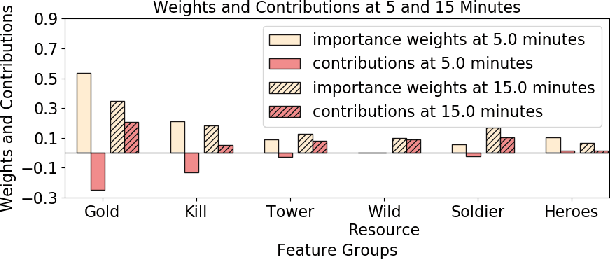
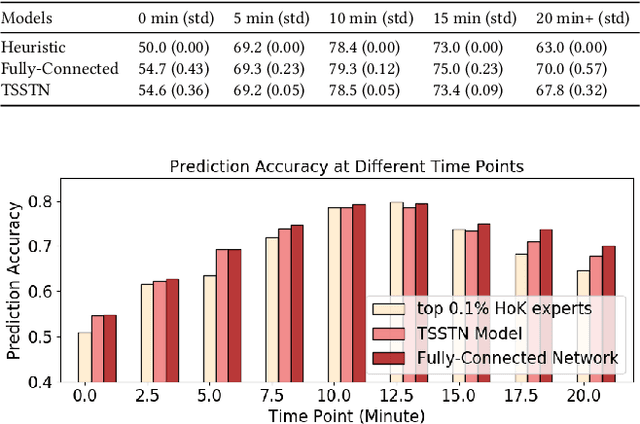
With the rapid prevalence and explosive development of MOBA esports (Multiplayer Online Battle Arena electronic sports), many research efforts have been devoted to automatically predicting the game results (win predictions). While this task has great potential in various applications such as esports live streaming and game commentator AI systems, previous studies suffer from two major limitations: 1) insufficient real-time input features and high-quality training data; 2) non-interpretable inference processes of the black-box prediction models. To mitigate these issues, we collect and release a large-scale dataset that contains real-time game records with rich input features of the popular MOBA game Honor of Kings. For interpretable predictions, we propose a Two-Stage Spatial-Temporal Network (TSSTN) that can not only provide accurate real-time win predictions but also attribute the ultimate prediction results to the contributions of different features for interpretability. Experiment results and applications in real-world live streaming scenarios show that the proposed TSSTN model is effective both in prediction accuracy and interpretability.
A Batch Normalized Inference Network Keeps the KL Vanishing Away
Jun 01, 2020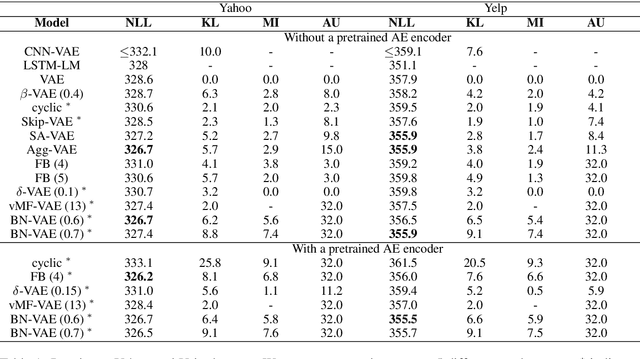
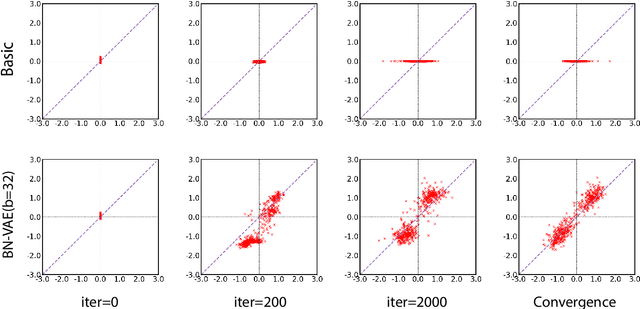
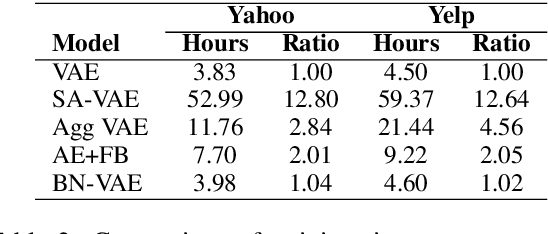
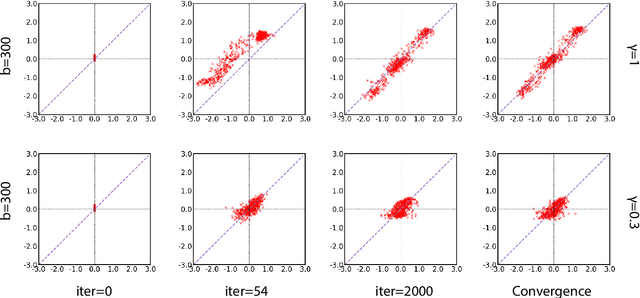
Variational Autoencoder (VAE) is widely used as a generative model to approximate a model's posterior on latent variables by combining the amortized variational inference and deep neural networks. However, when paired with strong autoregressive decoders, VAE often converges to a degenerated local optimum known as "posterior collapse". Previous approaches consider the Kullback Leibler divergence (KL) individual for each datapoint. We propose to let the KL follow a distribution across the whole dataset, and analyze that it is sufficient to prevent posterior collapse by keeping the expectation of the KL's distribution positive. Then we propose Batch Normalized-VAE (BN-VAE), a simple but effective approach to set a lower bound of the expectation by regularizing the distribution of the approximate posterior's parameters. Without introducing any new model component or modifying the objective, our approach can avoid the posterior collapse effectively and efficiently. We further show that the proposed BN-VAE can be extended to conditional VAE (CVAE). Empirically, our approach surpasses strong autoregressive baselines on language modeling, text classification and dialogue generation, and rivals more complex approaches while keeping almost the same training time as VAE.
Response-Anticipated Memory for On-Demand Knowledge Integration in Response Generation
May 13, 2020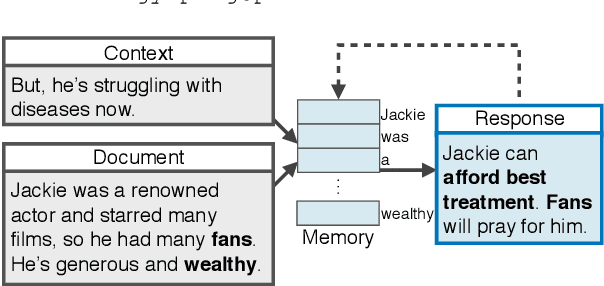
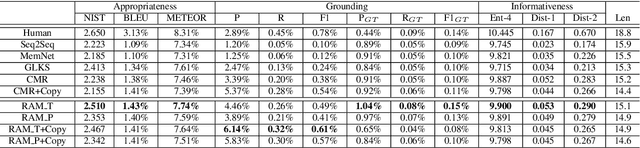
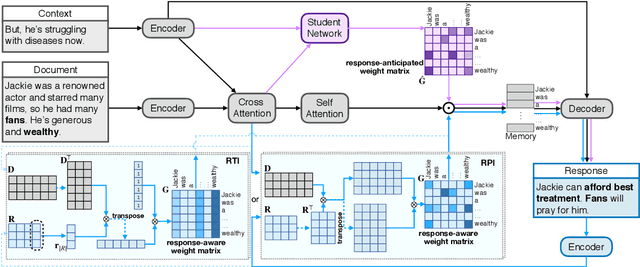

Neural conversation models are known to generate appropriate but non-informative responses in general. A scenario where informativeness can be significantly enhanced is Conversing by Reading (CbR), where conversations take place with respect to a given external document. In previous work, the external document is utilized by (1) creating a context-aware document memory that integrates information from the document and the conversational context, and then (2) generating responses referring to the memory. In this paper, we propose to create the document memory with some anticipated responses in mind. This is achieved using a teacher-student framework. The teacher is given the external document, the context, and the ground-truth response, and learns how to build a response-aware document memory from three sources of information. The student learns to construct a response-anticipated document memory from the first two sources, and the teacher's insight on memory creation. Empirical results show that our model outperforms the previous state-of-the-art for the CbR task.