 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDon't Parse, Insert: Multilingual Semantic Parsing with Insertion Based Decoding
Oct 08, 2020
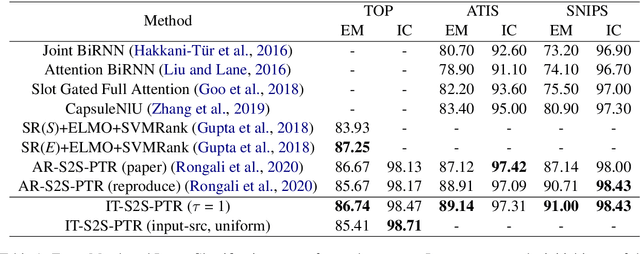


Semantic parsing is one of the key components of natural language understanding systems. A successful parse transforms an input utterance to an action that is easily understood by the system. Many algorithms have been proposed to solve this problem, from conventional rulebased or statistical slot-filling systems to shiftreduce based neural parsers. For complex parsing tasks, the state-of-the-art method is based on autoregressive sequence to sequence models to generate the parse directly. This model is slow at inference time, generating parses in O(n) decoding steps (n is the length of the target sequence). In addition, we demonstrate that this method performs poorly in zero-shot cross-lingual transfer learning settings. In this paper, we propose a non-autoregressive parser which is based on the insertion transformer to overcome these two issues. Our approach 1) speeds up decoding by 3x while outperforming the autoregressive model and 2) significantly improves cross-lingual transfer in the low-resource setting by 37% compared to autoregressive baseline. We test our approach on three well-known monolingual datasets: ATIS, SNIPS and TOP. For cross lingual semantic parsing, we use the MultiATIS++ and the multilingual TOP datasets.
Asking Complex Questions with Multi-hop Answer-focused Reasoning
Sep 16, 2020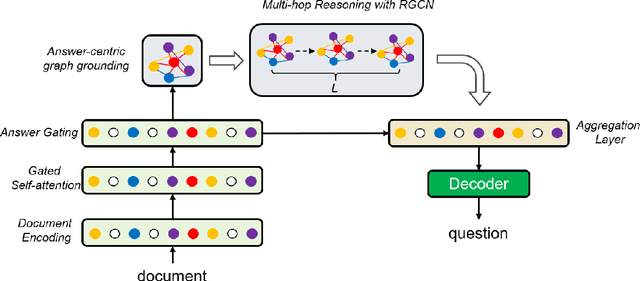
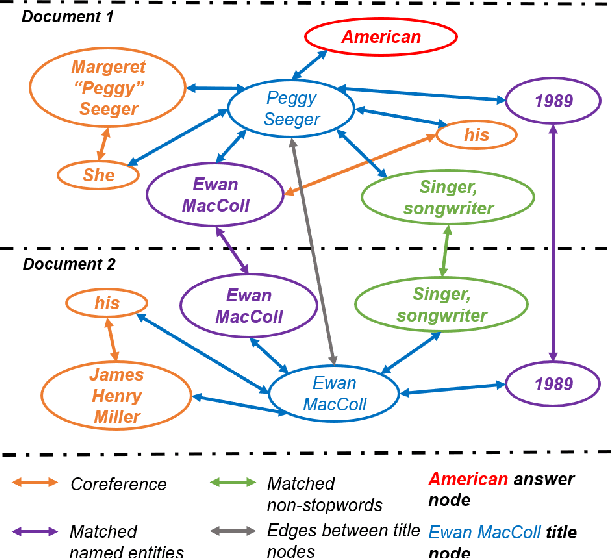
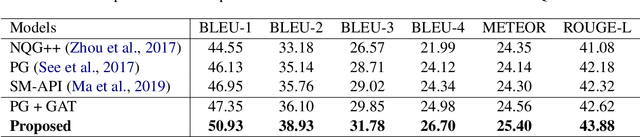
Asking questions from natural language text has attracted increasing attention recently, and several schemes have been proposed with promising results by asking the right question words and copy relevant words from the input to the question. However, most state-of-the-art methods focus on asking simple questions involving single-hop relations. In this paper, we propose a new task called multihop question generation that asks complex and semantically relevant questions by additionally discovering and modeling the multiple entities and their semantic relations given a collection of documents and the corresponding answer 1. To solve the problem, we propose multi-hop answer-focused reasoning on the grounded answer-centric entity graph to include different granularity levels of semantic information including the word-level and document-level semantics of the entities and their semantic relations. Through extensive experiments on the HOTPOTQA dataset, we demonstrate the superiority and effectiveness of our proposed model that serves as a baseline to motivate future work.
A Batch Normalized Inference Network Keeps the KL Vanishing Away
Jun 01, 2020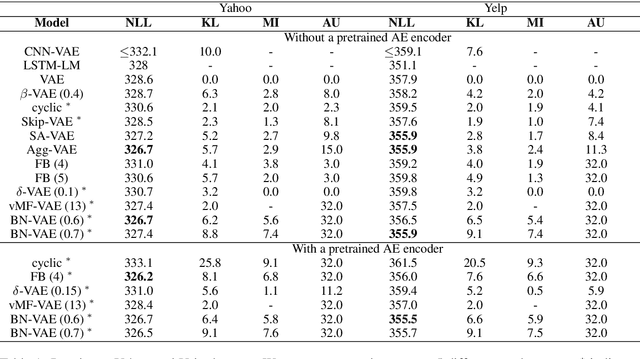
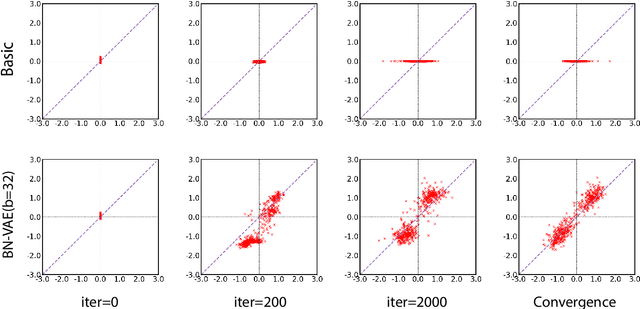
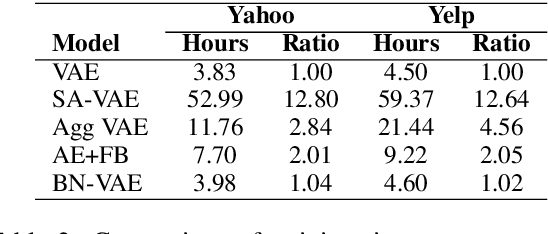
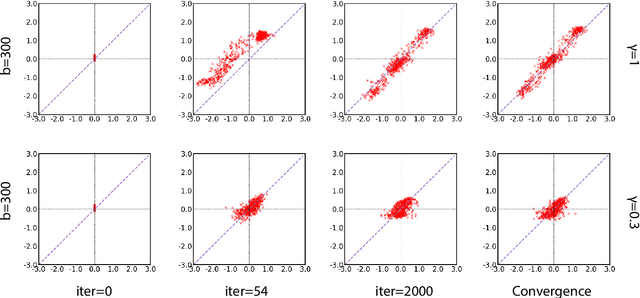
Variational Autoencoder (VAE) is widely used as a generative model to approximate a model's posterior on latent variables by combining the amortized variational inference and deep neural networks. However, when paired with strong autoregressive decoders, VAE often converges to a degenerated local optimum known as "posterior collapse". Previous approaches consider the Kullback Leibler divergence (KL) individual for each datapoint. We propose to let the KL follow a distribution across the whole dataset, and analyze that it is sufficient to prevent posterior collapse by keeping the expectation of the KL's distribution positive. Then we propose Batch Normalized-VAE (BN-VAE), a simple but effective approach to set a lower bound of the expectation by regularizing the distribution of the approximate posterior's parameters. Without introducing any new model component or modifying the objective, our approach can avoid the posterior collapse effectively and efficiently. We further show that the proposed BN-VAE can be extended to conditional VAE (CVAE). Empirically, our approach surpasses strong autoregressive baselines on language modeling, text classification and dialogue generation, and rivals more complex approaches while keeping almost the same training time as VAE.
Local Contextual Attention with Hierarchical Structure for Dialogue Act Recognition
Mar 12, 2020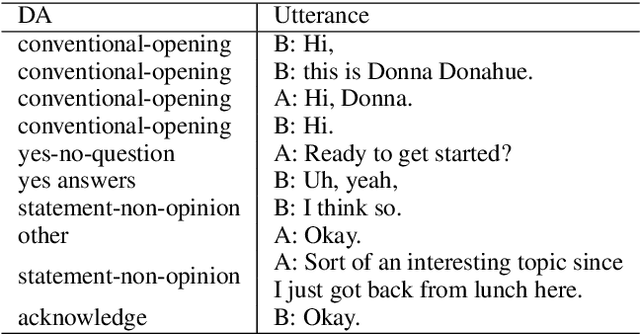
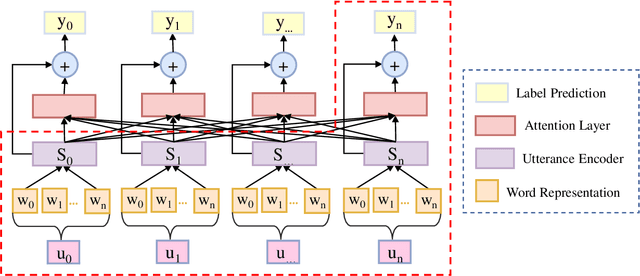
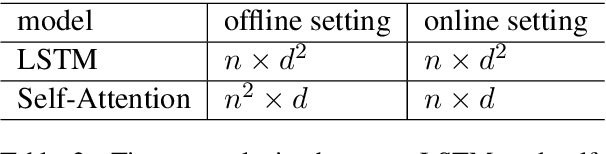
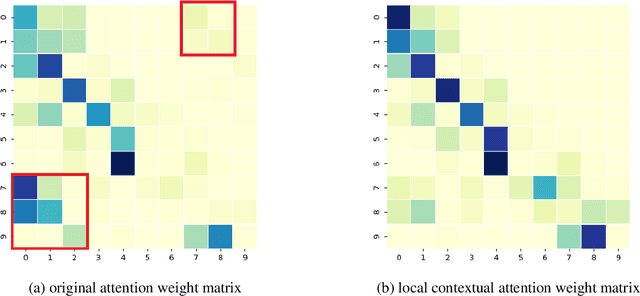
Dialogue act recognition is a fundamental task for an intelligent dialogue system. Previous work models the whole dialog to predict dialog acts, which may bring the noise from unrelated sentences. In this work, we design a hierarchical model based on self-attention to capture intra-sentence and inter-sentence information. We revise the attention distribution to focus on the local and contextual semantic information by incorporating the relative position information between utterances. Based on the found that the length of dialog affects the performance, we introduce a new dialog segmentation mechanism to analyze the effect of dialog length and context padding length under online and offline settings. The experiment shows that our method achieves promising performance on two datasets: Switchboard Dialogue Act and DailyDialog with the accuracy of 80.34\% and 85.81\% respectively. Visualization of the attention weights shows that our method can learn the context dependency between utterances explicitly.
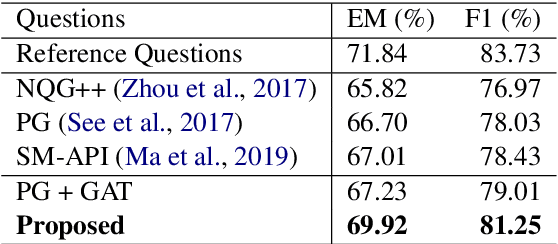
Improving Question Generation with Sentence-level Semantic Matching and Answer Position Inferring
Feb 03, 2020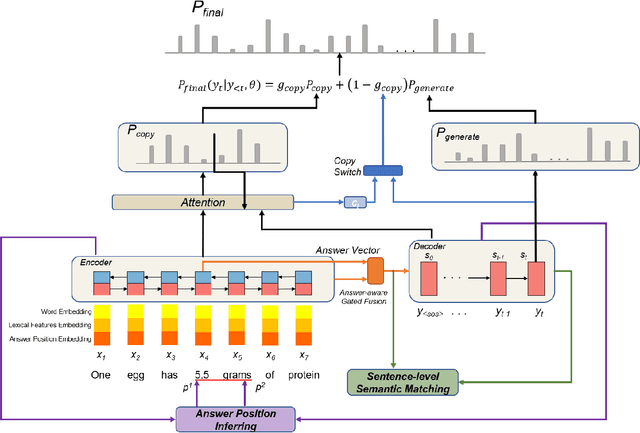

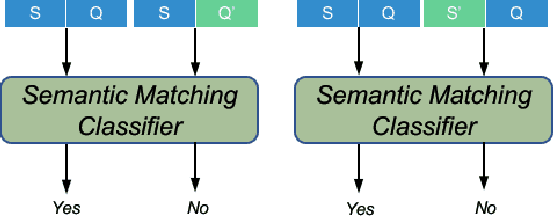
Taking an answer and its context as input, sequence-to-sequence models have made considerable progress on question generation. However, we observe that these approaches often generate wrong question words or keywords and copy answer-irrelevant words from the input. We believe that lacking global question semantics and exploiting answer position-awareness not well are the key root causes. In this paper, we propose a neural question generation model with two concrete modules: sentence-level semantic matching and answer position inferring. Further, we enhance the initial state of the decoder by leveraging the answer-aware gated fusion mechanism. Experimental results demonstrate that our model outperforms the state-of-the-art (SOTA) models on SQuAD and MARCO datasets. Owing to its generality, our work also improves the existing models significantly.
Adversarial Examples: Attacks and Defenses for Deep Learning
Jul 07, 2018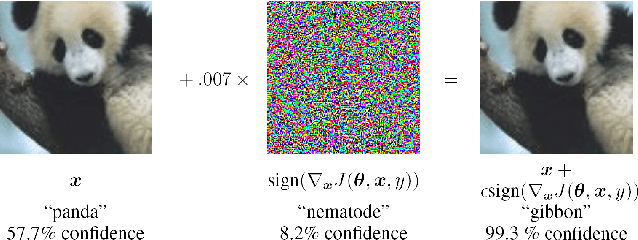
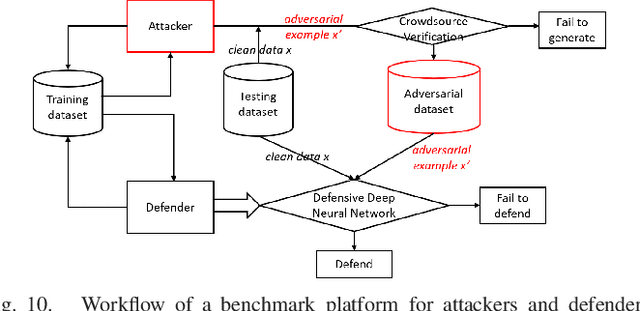
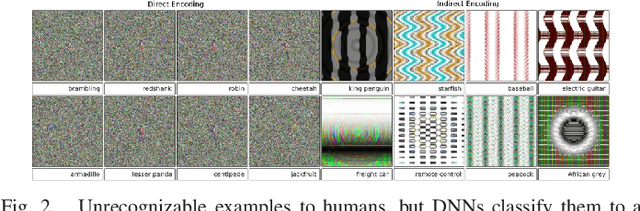
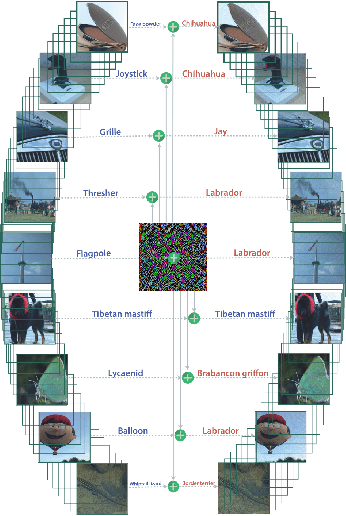
With rapid progress and significant successes in a wide spectrum of applications, deep learning is being applied in many safety-critical environments. However, deep neural networks have been recently found vulnerable to well-designed input samples, called adversarial examples. Adversarial examples are imperceptible to human but can easily fool deep neural networks in the testing/deploying stage. The vulnerability to adversarial examples becomes one of the major risks for applying deep neural networks in safety-critical environments. Therefore, attacks and defenses on adversarial examples draw great attention. In this paper, we review recent findings on adversarial examples for deep neural networks, summarize the methods for generating adversarial examples, and propose a taxonomy of these methods. Under the taxonomy, applications for adversarial examples are investigated. We further elaborate on countermeasures for adversarial examples and explore the challenges and the potential solutions.
Learning Fast and Slow: PROPEDEUTICA for Real-time Malware Detection
Dec 04, 2017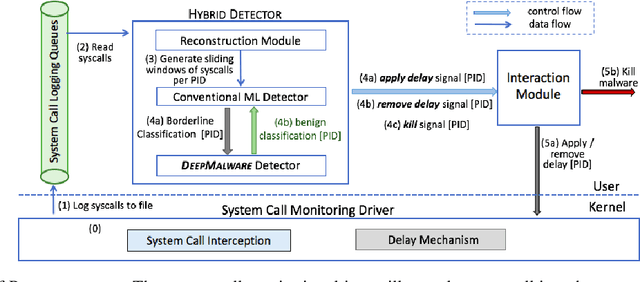
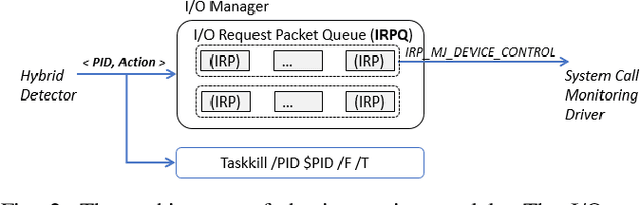
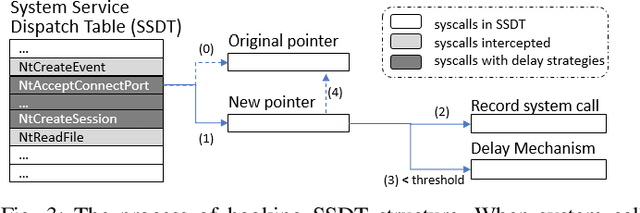
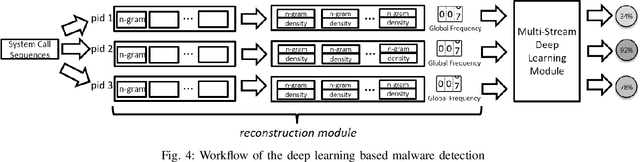
In this paper, we introduce and evaluate PROPEDEUTICA, a novel methodology and framework for efficient and effective real-time malware detection, leveraging the best of conventional machine learning (ML) and deep learning (DL) algorithms. In PROPEDEUTICA, all software processes in the system start execution subjected to a conventional ML detector for fast classification. If a piece of software receives a borderline classification, it is subjected to further analysis via more performance expensive and more accurate DL methods, via our newly proposed DL algorithm DEEPMALWARE. Further, we introduce delays to the execution of software subjected to deep learning analysis as a way to "buy time" for DL analysis and to rate-limit the impact of possible malware in the system. We evaluated PROPEDEUTICA with a set of 9,115 malware samples and 877 commonly used benign software samples from various categories for the Windows OS. Our results show that the false positive rate for conventional ML methods can reach 20%, and for modern DL methods it is usually below 6%. However, the classification time for DL can be 100X longer than conventional ML methods. PROPEDEUTICA improved the detection F1-score from 77.54% (conventional ML method) to 90.25%, and reduced the detection time by 54.86%. Further, the percentage of software subjected to DL analysis was approximately 40% on average. Further, the application of delays in software subjected to ML reduced the detection time by approximately 10%. Finally, we found and discussed a discrepancy between the detection accuracy offline (analysis after all traces are collected) and on-the-fly (analysis in tandem with trace collection). Our insights show that conventional ML and modern DL-based malware detectors in isolation cannot meet the needs of efficient and effective malware detection: high accuracy, low false positive rate, and short classification time.