 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Driven Completeness and Consistency Evaluation for Cultural Heritage Data Augmentation in Cross-Modal Retrieval
Nov 09, 2025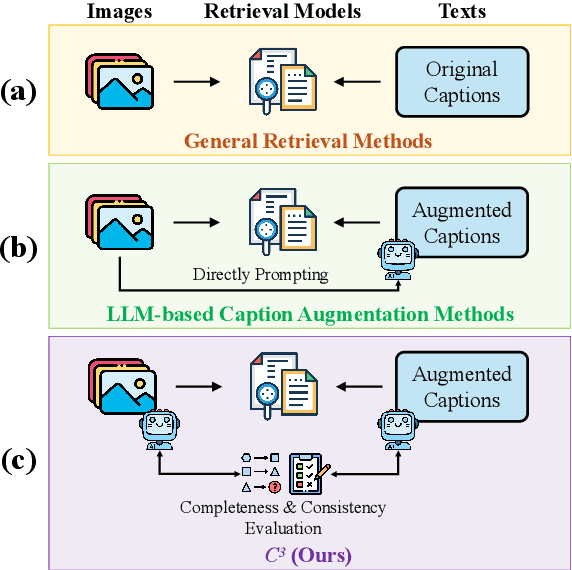
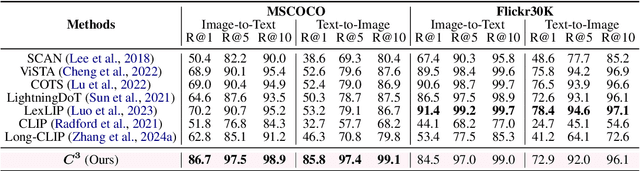
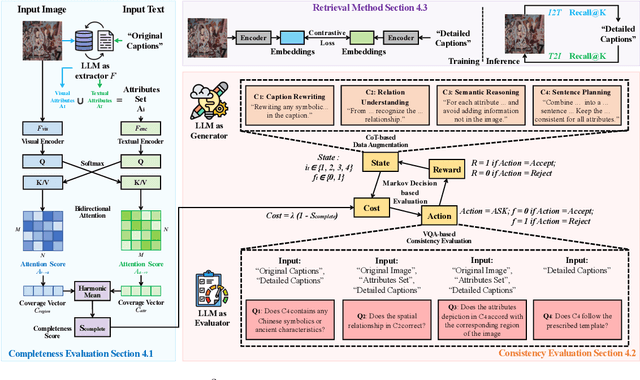
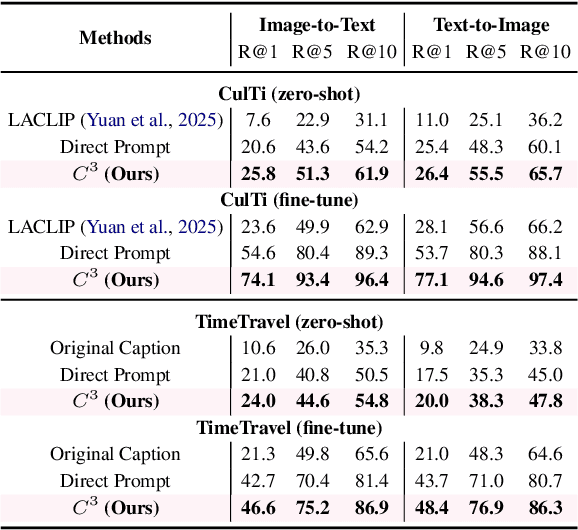
Cross-modal retrieval is essential for interpreting cultural heritage data, but its effectiveness is often limited by incomplete or inconsistent textual descriptions, caused by historical data loss and the high cost of expert annotation. While large language models (LLMs) offer a promising solution by enriching textual descriptions, their outputs frequently suffer from hallucinations or miss visually grounded details. To address these challenges, we propose $C^3$, a data augmentation framework that enhances cross-modal retrieval performance by improving the completeness and consistency of LLM-generated descriptions. $C^3$ introduces a completeness evaluation module to assess semantic coverage using both visual cues and language-model outputs. Furthermore, to mitigate factual inconsistencies, we formulate a Markov Decision Process to supervise Chain-of-Thought reasoning, guiding consistency evaluation through adaptive query control. Experiments on the cultural heritage datasets CulTi and TimeTravel, as well as on general benchmarks MSCOCO and Flickr30K, demonstrate that $C^3$ achieves state-of-the-art performance in both fine-tuned and zero-shot settings.
Efficient Multi-Agent Coordination via Dynamic Joint-State Graph Construction
Sep 08, 2025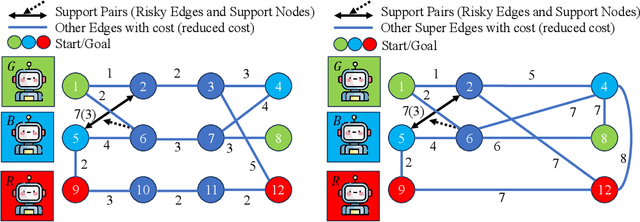

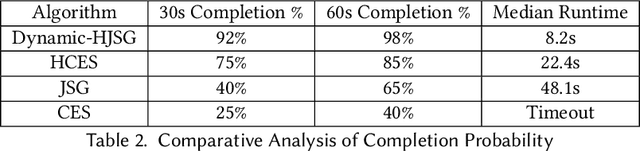
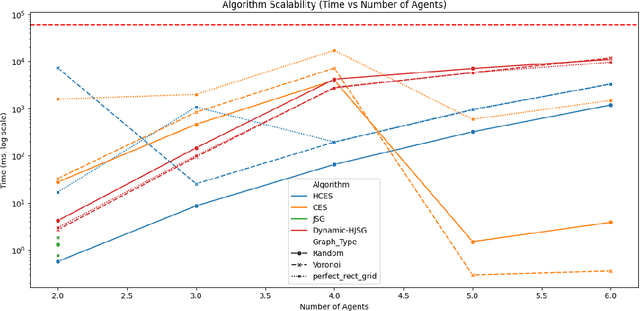
Multi-agent pathfinding (MAPF) traditionally focuses on collision avoidance, but many real-world applications require active coordination between agents to improve team performance. This paper introduces Team Coordination on Graphs with Risky Edges (TCGRE), where agents collaborate to reduce traversal costs on high-risk edges via support from teammates. We reformulate TCGRE as a 3D matching problem-mapping robot pairs, support pairs, and time steps-and rigorously prove its NP-hardness via reduction from Minimum 3D Matching. To address this complexity, (in the conference version) we proposed efficient decomposition methods, reducing the problem to tractable subproblems: Joint-State Graph (JSG): Encodes coordination as a single-agent shortest-path problem. Coordination-Exhaustive Search (CES): Optimizes support assignments via exhaustive pairing. Receding-Horizon Optimistic Cooperative A* (RHOCA*): Balances optimality and scalability via horizon-limited planning. Further in this extension, we introduce a dynamic graph construction method (Dynamic-HJSG), leveraging agent homogeneity to prune redundant states and reduce computational overhead by constructing the joint-state graph dynamically. Theoretical analysis shows Dynamic-HJSG preserves optimality while lowering complexity from exponential to polynomial in key cases. Empirical results validate scalability for large teams and graphs, with HJSG outperforming baselines greatly in runtime in different sizes and types of graphs. This work bridges combinatorial optimization and multi-agent planning, offering a principled framework for collaborative pathfinding with provable guarantees, and the key idea of the solution can be widely extended to many other collaborative optimization problems, such as MAPF.
Regularizing Differentiable Architecture Search with Smooth Activation
Apr 22, 2025Differentiable Architecture Search (DARTS) is an efficient Neural Architecture Search (NAS) method but suffers from robustness, generalization, and discrepancy issues. Many efforts have been made towards the performance collapse issue caused by skip dominance with various regularization techniques towards operation weights, path weights, noise injection, and super-network redesign. It had become questionable at a certain point if there could exist a better and more elegant way to retract the search to its intended goal -- NAS is a selection problem. In this paper, we undertake a simple but effective approach, named Smooth Activation DARTS (SA-DARTS), to overcome skip dominance and discretization discrepancy challenges. By leveraging a smooth activation function on architecture weights as an auxiliary loss, our SA-DARTS mitigates the unfair advantage of weight-free operations, converging to fanned-out architecture weight values, and can recover the search process from skip-dominance initialization. Through theoretical and empirical analysis, we demonstrate that the SA-DARTS can yield new state-of-the-art (SOTA) results on NAS-Bench-201, classification, and super-resolution. Further, we show that SA-DARTS can help improve the performance of SOTA models with fewer parameters, such as Information Multi-distillation Network on the super-resolution task.
Heterogeneous Team Coordination on Partially Observable Graphs with Realistic Communication
Oct 29, 2024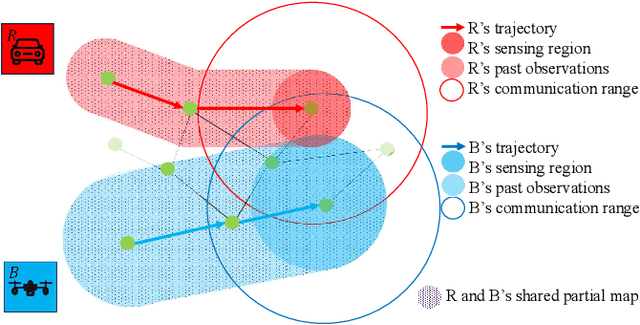

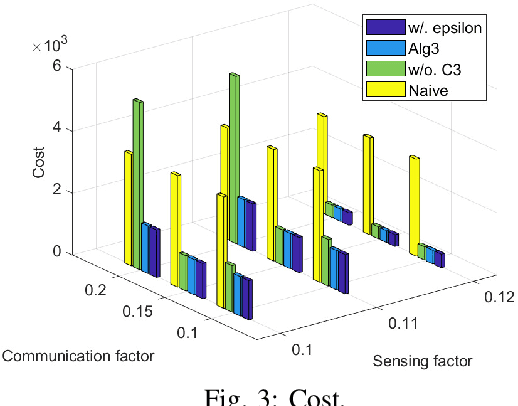
Team Coordination on Graphs with Risky Edges (\textsc{tcgre}) is a recently proposed problem, in which robots find paths to their goals while considering possible coordination to reduce overall team cost. However, \textsc{tcgre} assumes that the \emph{entire} environment is available to a \emph{homogeneous} robot team with \emph{ubiquitous} communication. In this paper, we study an extended version of \textsc{tcgre}, called \textsc{hpr-tcgre}, with three relaxations: Heterogeneous robots, Partial observability, and Realistic communication. To this end, we form a new combinatorial optimization problem on top of \textsc{tcgre}. After analysis, we divide it into two sub-problems, one for robots moving individually, another for robots in groups, depending on their communication availability. Then, we develop an algorithm that exploits real-time partial maps to solve local shortest path(s) problems, with a A*-like sub-goal(s) assignment mechanism that explores potential coordination opportunities for global interests. Extensive experiments indicate that our algorithm is able to produce team coordination behaviors in order to reduce overall cost even with our three relaxations.
A Protein Structure Prediction Approach Leveraging Transformer and CNN Integration
Mar 08, 2024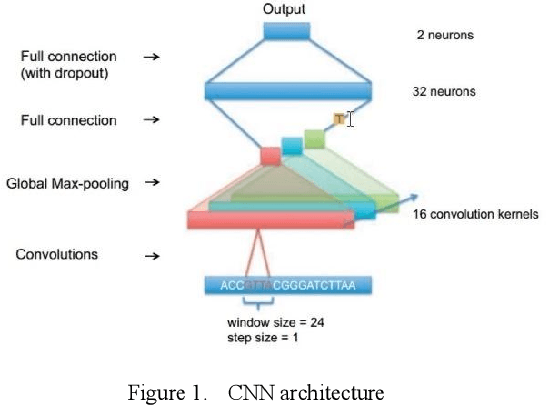
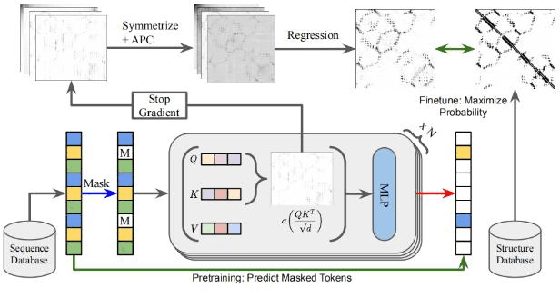
Proteins are essential for life, and their structure determines their function. The protein secondary structure is formed by the folding of the protein primary structure, and the protein tertiary structure is formed by the bending and folding of the secondary structure. Therefore, the study of protein secondary structure is very helpful to the overall understanding of protein structure. Although the accuracy of protein secondary structure prediction has continuously improved with the development of machine learning and deep learning, progress in the field of protein structure prediction, unfortunately, remains insufficient to meet the large demand for protein information. Therefore, based on the advantages of deep learning-based methods in feature extraction and learning ability, this paper adopts a two-dimensional fusion deep neural network model, DstruCCN, which uses Convolutional Neural Networks (CCN) and a supervised Transformer protein language model for single-sequence protein structure prediction. The training features of the two are combined to predict the protein Transformer binding site matrix, and then the three-dimensional structure is reconstructed using energy minimization.
Construction and application of artificial intelligence crowdsourcing map based on multi-track GPS data
Feb 24, 2024



In recent years, the rapid development of high-precision map technology combined with artificial intelligence has ushered in a new development opportunity in the field of intelligent vehicles. High-precision map technology is an important guarantee for intelligent vehicles to achieve autonomous driving. However, due to the lack of research on high-precision map technology, it is difficult to rationally use this technology in the field of intelligent vehicles. Therefore, relevant researchers studied a fast and effective algorithm to generate high-precision GPS data from a large number of low-precision GPS trajectory data fusion, and generated several key data points to simplify the description of GPS trajectory, and realized the "crowdsourced update" model based on a large number of social vehicles for map data collection came into being. This kind of algorithm has the important significance to improve the data accuracy, reduce the measurement cost and reduce the data storage space. On this basis, this paper analyzes the implementation form of crowdsourcing map, so as to improve the various information data in the high-precision map according to the actual situation, and promote the high-precision map can be reasonably applied to the intelligent car.
Open Compound Domain Adaptation with Object Style Compensation for Semantic Segmentation
Sep 28, 2023



Many methods of semantic image segmentation have borrowed the success of open compound domain adaptation. They minimize the style gap between the images of source and target domains, more easily predicting the accurate pseudo annotations for target domain's images that train segmentation network. The existing methods globally adapt the scene style of the images, whereas the object styles of different categories or instances are adapted improperly. This paper proposes the Object Style Compensation, where we construct the Object-Level Discrepancy Memory with multiple sets of discrepancy features. The discrepancy features in a set capture the style changes of the same category's object instances adapted from target to source domains. We learn the discrepancy features from the images of source and target domains, storing the discrepancy features in memory. With this memory, we select appropriate discrepancy features for compensating the style information of the object instances of various categories, adapting the object styles to a unified style of source domain. Our method enables a more accurate computation of the pseudo annotations for target domain's images, thus yielding state-of-the-art results on different datasets.
A Data-Driven Model with Hysteresis Compensation for I2RIS Robot
Mar 10, 2023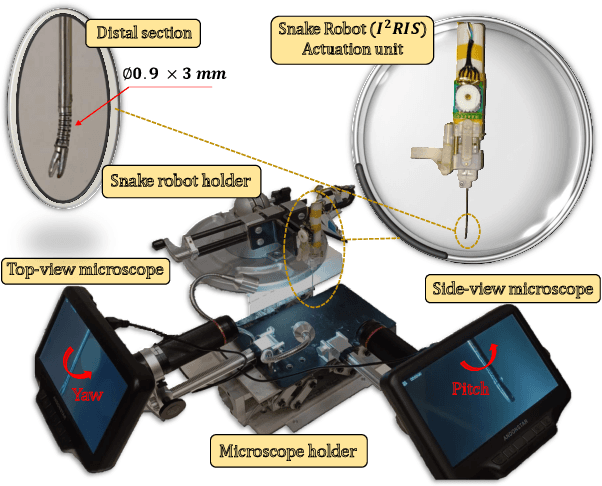
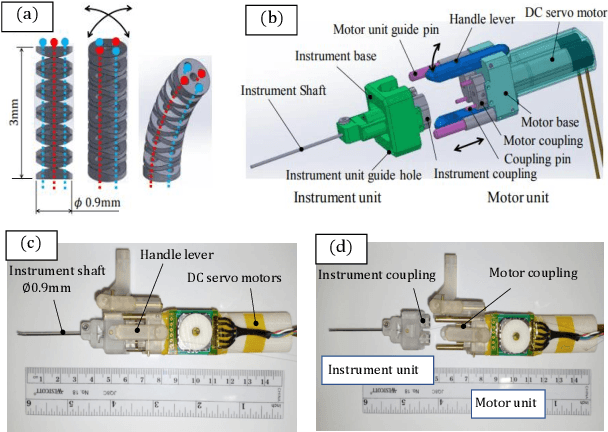

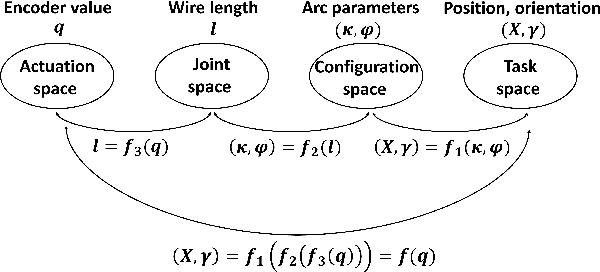
Retinal microsurgery is a high-precision surgery performed on an exceedingly delicate tissue. It now requires extensively trained and highly skilled surgeons. Given the restricted range of instrument motion in the confined intraocular space, and also potentially restricting instrument contact with the sclera, snake-like robots may prove to be a promising technology to provide surgeons with greater flexibility, dexterity, space access, and positioning accuracy during retinal procedures requiring high precision and advantageous tooltip approach angles, such as retinal vein cannulation and epiretinal membrane peeling. Kinematics modeling of these robots is an essential step toward accurate position control, however, as opposed to conventional manipulators, modeling of these robots does not follow a straightforward method due to their complex mechanical structure and actuation mechanisms. Especially, in wire-driven snake-like robots, the hysteresis problem due to the wire tension condition can have a significant impact on the positioning accuracy of these robots. In this paper, we proposed an experimental kinematics model with a hysteresis compensation algorithm using the probabilistic Gaussian mixture models (GMM) Gaussian mixture regression (GMR) approach. Experimental results on the two-degree-of-freedom (DOF) integrated robotic intraocular snake (I2RIS) show that the proposed model provides 0.4 deg accuracy, which is an overall 60% and 70% of improvement for yaw and pitch degrees of freedom, respectively, compared to a previous model of this robot.
Server Averaging for Federated Learning
Mar 22, 2021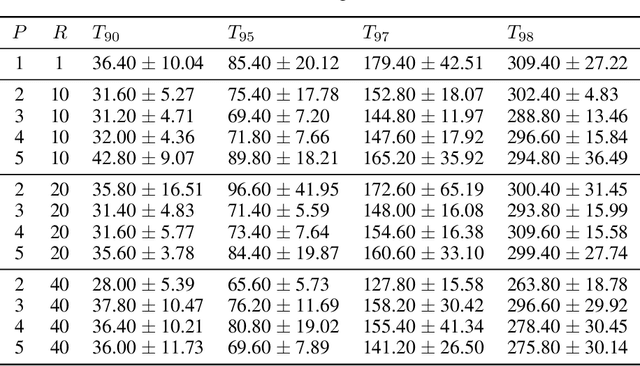
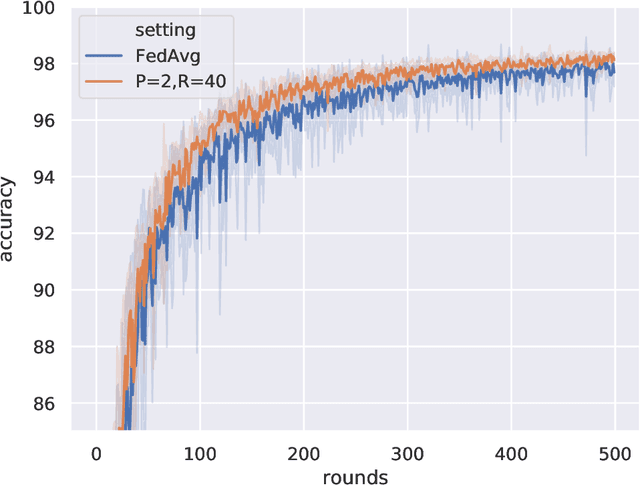
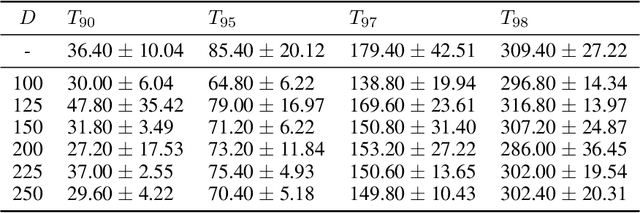
Federated learning allows distributed devices to collectively train a model without sharing or disclosing the local dataset with a central server. The global model is optimized by training and averaging the model parameters of all local participants. However, the improved privacy of federated learning also introduces challenges including higher computation and communication costs. In particular, federated learning converges slower than centralized training. We propose the server averaging algorithm to accelerate convergence. Sever averaging constructs the shared global model by periodically averaging a set of previous global models. Our experiments indicate that server averaging not only converges faster, to a target accuracy, than federated averaging (FedAvg), but also reduces the computation costs on the client-level through epoch decay.
Distilled One-Shot Federated Learning
Sep 17, 2020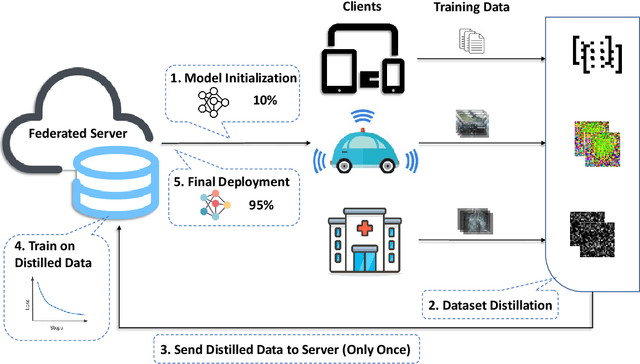
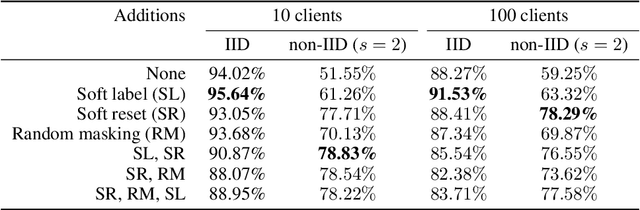
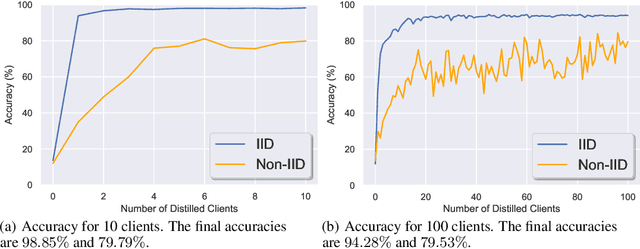
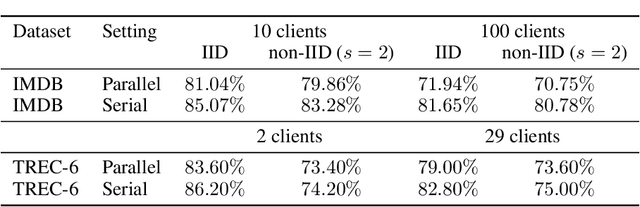
Current federated learning algorithms take tens of communication rounds transmitting unwieldy model weights under ideal circumstances and hundreds when data is poorly distributed. Inspired by recent work on dataset distillation and distributed one-shot learning, we propose Distilled One-Shot Federated Learning, which reduces the number of communication rounds required to train a performant model to only one. Each client distills their private dataset and sends the synthetic data (e.g. images or sentences) to the server. The distilled data look like noise and become useless after model fitting. We empirically show that, in only one round of communication, our method can achieve 96% test accuracy on federated MNIST with LeNet (centralized 99%), 81% on federated IMDB with a customized CNN (centralized 86%), and 84% on federated TREC-6 with a Bi-LSTM (centralized 89%). Using only a few rounds, DOSFL can match the centralized baseline on all three tasks. By evading the need for model-wise updates (i.e., weights, gradients, loss, etc.), the total communication cost of DOSFL is reduced by over an order of magnitude. We believe that DOSFL represents a new direction orthogonal to previous work, towards weight-less and gradient-less federated learning.