 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Motion Compensation in Autonomous Robotic Subretinal Injections
Nov 27, 2024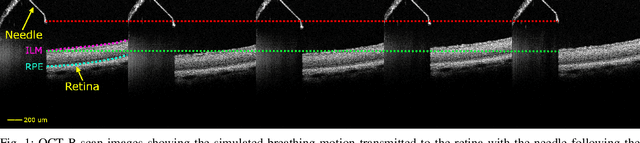
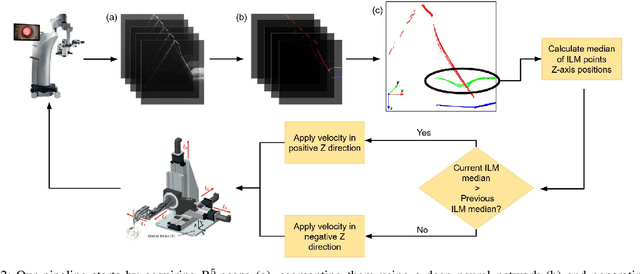


Exudative (wet) age-related macular degeneration (AMD) is a leading cause of vision loss in older adults, typically treated with intravitreal injections. Emerging therapies, such as subretinal injections of stem cells, gene therapy, small molecules or RPE cells require precise delivery to avoid damaging delicate retinal structures. Autonomous robotic systems can potentially offer the necessary precision for these procedures. This paper presents a novel approach for motion compensation in robotic subretinal injections, utilizing real-time Optical Coherence Tomography (OCT). The proposed method leverages B$^{5}$-scans, a rapid acquisition of small-volume OCT data, for dynamic tracking of retinal motion along the Z-axis, compensating for physiological movements such as breathing and heartbeat. Validation experiments on \textit{ex vivo} porcine eyes revealed challenges in maintaining a consistent tool-to-retina distance, with deviations of up to 200 $\mu m$ for 100 $\mu m$ amplitude motions and over 80 $\mu m$ for 25 $\mu m$ amplitude motions over one minute. Subretinal injections faced additional difficulties, with horizontal shifts causing the needle to move off-target and inject into the vitreous. These results highlight the need for improved motion prediction and horizontal stability to enhance the accuracy and safety of robotic subretinal procedures.
Real-time Deformation-aware Control for Autonomous Robotic Subretinal Injection under iOCT Guidance
Nov 10, 2024



Robotic platforms provide repeatable and precise tool positioning that significantly enhances retinal microsurgery. Integration of such systems with intraoperative optical coherence tomography (iOCT) enables image-guided robotic interventions, allowing to autonomously perform advanced treatment possibilities, such as injecting therapeutic agents into the subretinal space. Yet, tissue deformations due to tool-tissue interactions are a major challenge in autonomous iOCT-guided robotic subretinal injection, impacting correct needle positioning and, thus, the outcome of the procedure. This paper presents a novel method for autonomous subretinal injection under iOCT guidance that considers tissue deformations during the insertion procedure. This is achieved through real-time segmentation and 3D reconstruction of the surgical scene from densely sampled iOCT B-scans, which we refer to as B5-scans, to monitor the positioning of the instrument regarding a virtual target layer defined at a relative position between the ILM and RPE. Our experiments on ex-vivo porcine eyes demonstrate dynamic adjustment of the insertion depth and overall improved accuracy in needle positioning compared to previous autonomous insertion approaches. Compared to a 35% success rate in subretinal bleb generation with previous approaches, our proposed method reliably and robustly created subretinal blebs in all our experiments.
A Data-Driven Model with Hysteresis Compensation for I2RIS Robot
Mar 10, 2023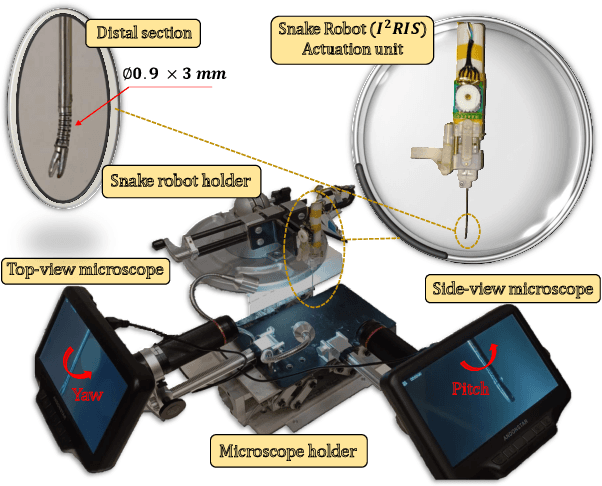
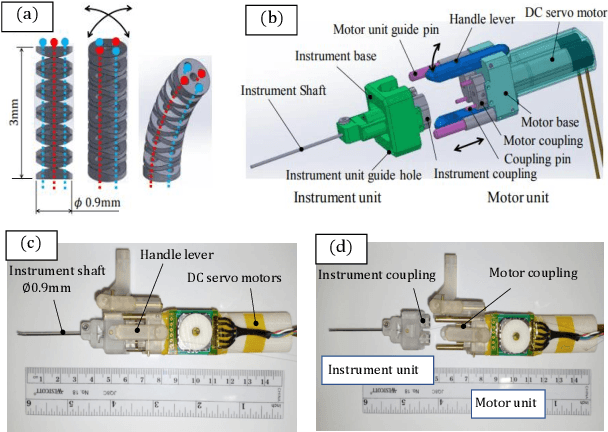

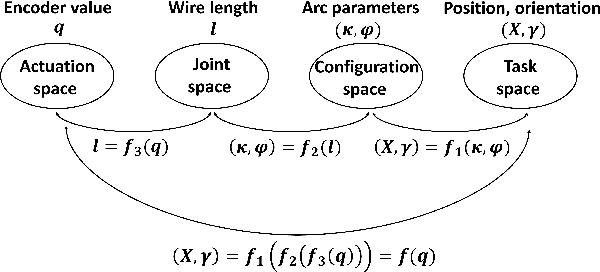
Retinal microsurgery is a high-precision surgery performed on an exceedingly delicate tissue. It now requires extensively trained and highly skilled surgeons. Given the restricted range of instrument motion in the confined intraocular space, and also potentially restricting instrument contact with the sclera, snake-like robots may prove to be a promising technology to provide surgeons with greater flexibility, dexterity, space access, and positioning accuracy during retinal procedures requiring high precision and advantageous tooltip approach angles, such as retinal vein cannulation and epiretinal membrane peeling. Kinematics modeling of these robots is an essential step toward accurate position control, however, as opposed to conventional manipulators, modeling of these robots does not follow a straightforward method due to their complex mechanical structure and actuation mechanisms. Especially, in wire-driven snake-like robots, the hysteresis problem due to the wire tension condition can have a significant impact on the positioning accuracy of these robots. In this paper, we proposed an experimental kinematics model with a hysteresis compensation algorithm using the probabilistic Gaussian mixture models (GMM) Gaussian mixture regression (GMR) approach. Experimental results on the two-degree-of-freedom (DOF) integrated robotic intraocular snake (I2RIS) show that the proposed model provides 0.4 deg accuracy, which is an overall 60% and 70% of improvement for yaw and pitch degrees of freedom, respectively, compared to a previous model of this robot.
Robotic Navigation Autonomy for Subretinal Injection via Intelligent Real-Time Virtual iOCT Volume Slicing
Jan 17, 2023In the last decade, various robotic platforms have been introduced that could support delicate retinal surgeries. Concurrently, to provide semantic understanding of the surgical area, recent advances have enabled microscope-integrated intraoperative Optical Coherent Tomography (iOCT) with high-resolution 3D imaging at near video rate. The combination of robotics and semantic understanding enables task autonomy in robotic retinal surgery, such as for subretinal injection. This procedure requires precise needle insertion for best treatment outcomes. However, merging robotic systems with iOCT introduces new challenges. These include, but are not limited to high demands on data processing rates and dynamic registration of these systems during the procedure. In this work, we propose a framework for autonomous robotic navigation for subretinal injection, based on intelligent real-time processing of iOCT volumes. Our method consists of an instrument pose estimation method, an online registration between the robotic and the iOCT system, and trajectory planning tailored for navigation to an injection target. We also introduce intelligent virtual B-scans, a volume slicing approach for rapid instrument pose estimation, which is enabled by Convolutional Neural Networks (CNNs). Our experiments on ex-vivo porcine eyes demonstrate the precision and repeatability of the method. Finally, we discuss identified challenges in this work and suggest potential solutions to further the development of such systems.
Sonification as a Reliable Alternative to Conventional Visual Surgical Navigation
Jun 30, 2022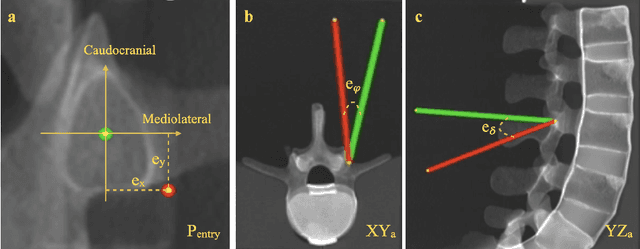
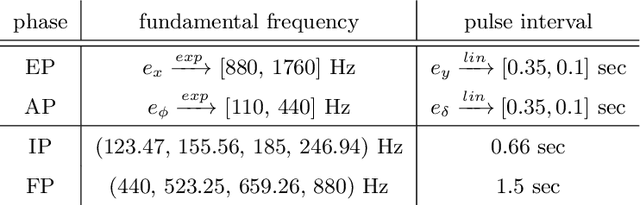
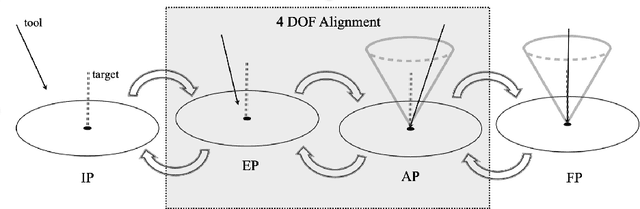
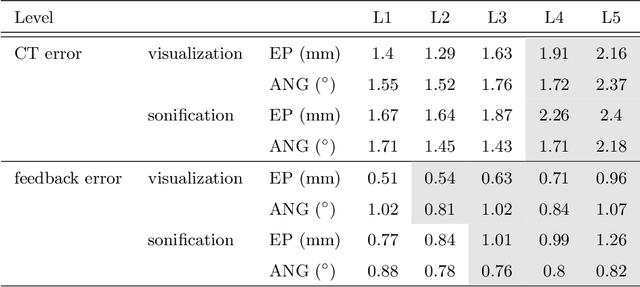
Despite the undeniable advantages of image-guided surgical assistance systems in terms of accuracy, such systems have not yet fully met surgeons' needs or expectations regarding usability, time efficiency, and their integration into the surgical workflow. On the other hand, perceptual studies have shown that presenting independent but causally correlated information via multimodal feedback involving different sensory modalities can improve task performance. This article investigates an alternative method for computer-assisted surgical navigation, introduces a novel sonification methodology for navigated pedicle screw placement, and discusses advanced solutions based on multisensory feedback. The proposed method comprises a novel sonification solution for alignment tasks in four degrees of freedom based on frequency modulation (FM) synthesis. We compared the resulting accuracy and execution time of the proposed sonification method with visual navigation, which is currently considered the state of the art. We conducted a phantom study in which 17 surgeons executed the pedicle screw placement task in the lumbar spine, guided by either the proposed sonification-based or the traditional visual navigation method. The results demonstrated that the proposed method is as accurate as the state of the art while decreasing the surgeon's need to focus on visual navigation displays instead of the natural focus on surgical tools and targeted anatomy during task execution.
BFS-Net: Weakly Supervised Cell Instance Segmentation from Bright-Field Microscopy Z-Stacks
Jun 09, 2022



Despite its broad availability, volumetric information acquisition from Bright-Field Microscopy (BFM) is inherently difficult due to the projective nature of the acquisition process. We investigate the prediction of 3D cell instances from a set of BFM Z-Stack images. We propose a novel two-stage weakly supervised method for volumetric instance segmentation of cells which only requires approximate cell centroids annotation. Created pseudo-labels are thereby refined with a novel refinement loss with Z-stack guidance. The evaluations show that our approach can generalize not only to BFM Z-Stack data, but to other 3D cell imaging modalities. A comparison of our pipeline against fully supervised methods indicates that the significant gain in reduced data collection and labelling results in minor performance difference.
ColibriDoc: An Eye-in-Hand Autonomous Trocar Docking System
Nov 30, 2021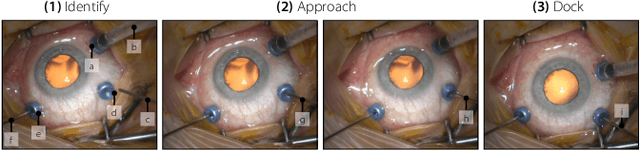

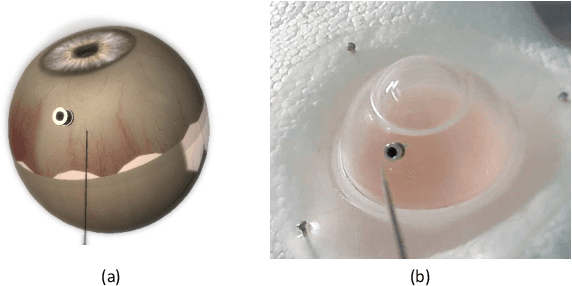
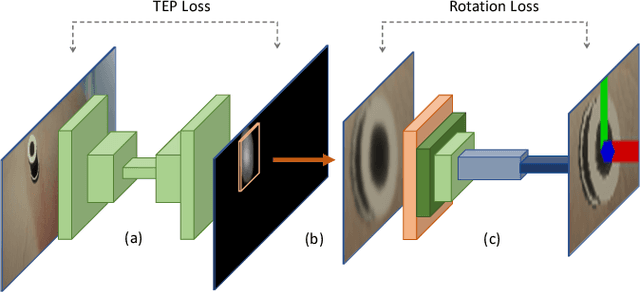
Retinal surgery is a complex medical procedure that requires exceptional expertise and dexterity. For this purpose, several robotic platforms are currently being developed to enable or improve the outcome of microsurgical tasks. Since the control of such robots is often designed for navigation inside the eye in proximity to the retina, successful trocar docking and inserting the instrument into the eye represents an additional cognitive effort, and is, therefore, one of the open challenges in robotic retinal surgery. For this purpose, we present a platform for autonomous trocar docking that combines computer vision and a robotic setup. Inspired by the Cuban Colibri (hummingbird) aligning its beak to a flower using only vision, we mount a camera onto the endeffector of a robotic system. By estimating the position and pose of the trocar, the robot is able to autonomously align and navigate the instrument towards the Trocar's Entry Point (TEP) and finally perform the insertion. Our experiments show that the proposed method is able to accurately estimate the position and pose of the trocar and achieve repeatable autonomous docking. The aim of this work is to reduce the complexity of robotic setup preparation prior to the surgical task and therefore, increase the intuitiveness of the system integration into the clinical workflow.
Graphite: GRAPH-Induced feaTure Extraction for Point Cloud Registration
Oct 18, 2020
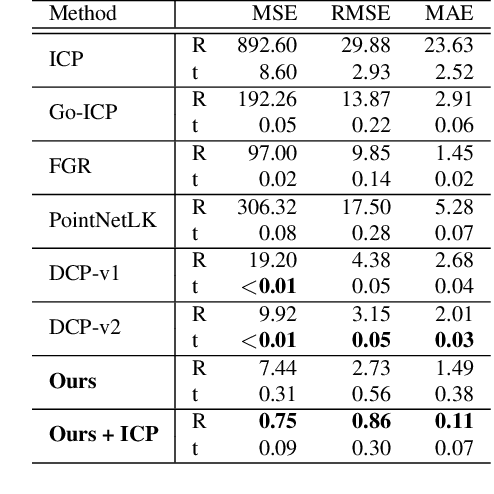
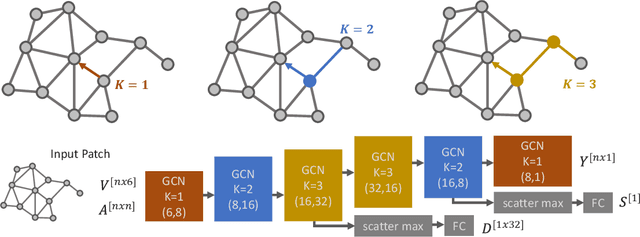

3D Point clouds are a rich source of information that enjoy growing popularity in the vision community. However, due to the sparsity of their representation, learning models based on large point clouds is still a challenge. In this work, we introduce Graphite, a GRAPH-Induced feaTure Extraction pipeline, a simple yet powerful feature transform and keypoint detector. Graphite enables intensive down-sampling of point clouds with keypoint detection accompanied by a descriptor. We construct a generic graph-based learning scheme to describe point cloud regions and extract salient points. To this end, we take advantage of 6D pose information and metric learning to learn robust descriptions and keypoints across different scans. We Reformulate the 3D keypoint pipeline with graph neural networks which allow efficient processing of the point set while boosting its descriptive power which ultimately results in more accurate 3D registrations. We demonstrate our lightweight descriptor on common 3D descriptor matching and point cloud registration benchmarks and achieve comparable results with the state of the art. Describing 100 patches of a point cloud and detecting their keypoints takes only ~0.018 seconds with our proposed network.