 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Detection and 6D Pose Estimation of Unseen Surgical Instruments
Mar 26, 2026Purpose: Accurate detection and 6D pose estimation of surgical instruments are crucial for many computer-assisted interventions. However, supervised methods lack flexibility for new or unseen tools and require extensive annotated data. This work introduces a training-free pipeline for accurate multi-view 6D pose estimation of unseen surgical instruments, which only requires a textured CAD model as prior knowledge. Methods: Our pipeline consists of two main stages. First, for detection, we generate object mask proposals in each view and score their similarity to rendered templates using a pre-trained feature extractor. Detections are matched across views, triangulated into 3D instance candidates, and filtered using multi-view geometric consistency. Second, for pose estimation, a set of pose hypotheses is iteratively refined and scored using feature-metric scores with cross-view attention. The best hypothesis undergoes a final refinement using a novel multi-view, occlusion-aware contour registration, which minimizes reprojection errors of unoccluded contour points. Results: The proposed method was rigorously evaluated on real-world surgical data from the MVPSP dataset. The method achieves millimeter-accurate pose estimates that are on par with supervised methods under controlled conditions, while maintaining full generalization to unseen instruments. These results demonstrate the feasibility of training-free, marker-less detection and tracking in surgical scenes, and highlight the unique challenges in surgical environments. Conclusion: We present a novel and flexible pipeline that effectively combines state-of-the-art foundational models, multi-view geometry, and contour-based refinement for high-accuracy 6D pose estimation of surgical instruments without task-specific training. This approach enables robust instrument tracking and scene understanding in dynamic clinical environments.
NeuralBoneReg: A Novel Self-Supervised Method for Robust and Accurate Multi-Modal Bone Surface Registration
Nov 18, 2025In computer- and robot-assisted orthopedic surgery (CAOS), patient-specific surgical plans derived from preoperative imaging define target locations and implant trajectories. During surgery, these plans must be accurately transferred, relying on precise cross-registration between preoperative and intraoperative data. However, substantial modality heterogeneity across imaging modalities makes this registration challenging and error-prone. Robust, automatic, and modality-agnostic bone surface registration is therefore clinically important. We propose NeuralBoneReg, a self-supervised, surface-based framework that registers bone surfaces using 3D point clouds as a modality-agnostic representation. NeuralBoneReg includes two modules: an implicit neural unsigned distance field (UDF) that learns the preoperative bone model, and an MLP-based registration module that performs global initialization and local refinement by generating transformation hypotheses to align the intraoperative point cloud with the neural UDF. Unlike SOTA supervised methods, NeuralBoneReg operates in a self-supervised manner, without requiring inter-subject training data. We evaluated NeuralBoneReg against baseline methods on two publicly available multi-modal datasets: a CT-ultrasound dataset of the fibula and tibia (UltraBones100k) and a CT-RGB-D dataset of spinal vertebrae (SpineDepth). The evaluation also includes a newly introduced CT--ultrasound dataset of cadaveric subjects containing femur and pelvis (UltraBones-Hip), which will be made publicly available. NeuralBoneReg matches or surpasses existing methods across all datasets, achieving mean RRE/RTE of 1.68°/1.86 mm on UltraBones100k, 1.88°/1.89 mm on UltraBones-Hip, and 3.79°/2.45 mm on SpineDepth. These results demonstrate strong generalizability across anatomies and modalities, providing robust and accurate cross-modal alignment for CAOS.
UltraBoneUDF: Self-supervised Bone Surface Reconstruction from Ultrasound Based on Neural Unsigned Distance Functions
May 23, 2025Background: Bone surface reconstruction plays a critical role in computer-assisted orthopedic surgery. Compared to traditional imaging modalities such as CT and MRI, ultrasound offers a radiation-free, cost-effective, and portable alternative. Continuous bone surface reconstruction can be employed for many clinical applications. However, due to the inherent limitations of ultrasound imaging, B-mode ultrasound typically capture only partial bone surfaces. Existing reconstruction methods struggle with such incomplete data, leading to artifacts and increased reconstruction errors. Effective techniques for accurately reconstructing thin and open bone surfaces from real-world 3D ultrasound volumes remain lacking. Methods: We propose UltraBoneUDF, a self-supervised framework designed for reconstructing open bone surfaces from ultrasound using neural Unsigned Distance Functions. To enhance reconstruction quality, we introduce a novel global feature extractor that effectively fuses ultrasound-specific image characteristics. Additionally, we present a novel loss function based on local tangent plane optimization that substantially improves surface reconstruction quality. UltraBoneUDF and baseline models are extensively evaluated on four open-source datasets. Results: Qualitative results highlight the limitations of the state-of-the-art methods for open bone surface reconstruction and demonstrate the effectiveness of UltraBoneUDF. Quantitatively, UltraBoneUDF significantly outperforms competing methods across all evaluated datasets for both open and closed bone surface reconstruction in terms of mean Chamfer distance error: 1.10 mm on the UltraBones100k dataset (39.6\% improvement compared to the SOTA), 0.23 mm on the OpenBoneCT dataset (69.3\% improvement), 0.18 mm on the ClosedBoneCT dataset (70.2\% improvement), and 0.05 mm on the Prostate dataset (55.3\% improvement).
ArthroPhase: A Novel Dataset and Method for Phase Recognition in Arthroscopic Video
Feb 11, 2025



This study aims to advance surgical phase recognition in arthroscopic procedures, specifically Anterior Cruciate Ligament (ACL) reconstruction, by introducing the first arthroscopy dataset and developing a novel transformer-based model. We aim to establish a benchmark for arthroscopic surgical phase recognition by leveraging spatio-temporal features to address the specific challenges of arthroscopic videos including limited field of view, occlusions, and visual distortions. We developed the ACL27 dataset, comprising 27 videos of ACL surgeries, each labeled with surgical phases. Our model employs a transformer-based architecture, utilizing temporal-aware frame-wise feature extraction through a ResNet-50 and transformer layers. This approach integrates spatio-temporal features and introduces a Surgical Progress Index (SPI) to quantify surgery progression. The model's performance was evaluated using accuracy, precision, recall, and Jaccard Index on the ACL27 and Cholec80 datasets. The proposed model achieved an overall accuracy of 72.91% on the ACL27 dataset. On the Cholec80 dataset, the model achieved a comparable performance with the state-of-the-art methods with an accuracy of 92.4%. The SPI demonstrated an output error of 10.6% and 9.86% on ACL27 and Cholec80 datasets respectively, indicating reliable surgery progression estimation. This study introduces a significant advancement in surgical phase recognition for arthroscopy, providing a comprehensive dataset and a robust transformer-based model. The results validate the model's effectiveness and generalizability, highlighting its potential to improve surgical training, real-time assistance, and operational efficiency in orthopedic surgery. The publicly available dataset and code will facilitate future research and development in this critical field.
UltraBones100k: An Ultrasound Image Dataset with CT-Derived Labels for Lower Extremity Long Bone Surface Segmentation
Feb 06, 2025



Ultrasound-based bone surface segmentation is crucial in computer-assisted orthopedic surgery. However, ultrasound images have limitations, including a low signal-to-noise ratio, and acoustic shadowing, which make interpretation difficult. Existing deep learning models for bone segmentation rely primarily on costly manual labeling by experts, limiting dataset size and model generalizability. Additionally, the complexity of ultrasound physics and acoustic shadow makes the images difficult for humans to interpret, leading to incomplete labels in anechoic regions and limiting model performance. To advance ultrasound bone segmentation and establish effective model benchmarks, larger and higher-quality datasets are needed. We propose a methodology for collecting ex-vivo ultrasound datasets with automatically generated bone labels, including anechoic regions. The proposed labels are derived by accurately superimposing tracked bone CT models onto the tracked ultrasound images. These initial labels are refined to account for ultrasound physics. A clinical evaluation is conducted by an expert physician specialized on orthopedic sonography to assess the quality of the generated bone labels. A neural network for bone segmentation is trained on the collected dataset and its predictions are compared to expert manual labels, evaluating accuracy, completeness, and F1-score. We collected the largest known dataset of 100k ultrasound images of human lower limbs with bone labels, called UltraBones100k. A Wilcoxon signed-rank test with Bonferroni correction confirmed that the bone alignment after our method significantly improved the quality of bone labeling (p < 0.001). The model trained on UltraBones100k consistently outperforms manual labeling in all metrics, particularly in low-intensity regions (320% improvement in completeness at a distance threshold of 0.5 mm).
Automatic breach detection during spine pedicle drilling based on vibroacoustic sensing
Mar 27, 2023



Pedicle drilling is a complex and critical spinal surgery task. Detecting breach or penetration of the surgical tool to the cortical wall during pilot-hole drilling is essential to avoid damage to vital anatomical structures adjacent to the pedicle, such as the spinal cord, blood vessels, and nerves. Currently, the guidance of pedicle drilling is done using image-guided methods that are radiation intensive and limited to the preoperative information. This work proposes a new radiation-free breach detection algorithm leveraging a non-visual sensor setup in combination with deep learning approach. Multiple vibroacoustic sensors, such as a contact microphone, a free-field microphone, a tri-axial accelerometer, a uni-axial accelerometer, and an optical tracking system were integrated into the setup. Data were collected on four cadaveric human spines, ranging from L5 to T10. An experienced spine surgeon drilled the pedicles relying on optical navigation. A new automatic labeling method based on the tracking data was introduced. Labeled data was subsequently fed to the network in mel-spectrograms, classifying the data into breach and non-breach. Different sensor types, sensor positioning, and their combinations were evaluated. The best results in breach recall for individual sensors could be achieved using contact microphones attached to the dorsal skin (85.8\%) and uni-axial accelerometers clamped to the spinous process of the drilled vertebra (81.0\%). The best-performing data fusion model combined the latter two sensors with a breach recall of 98\%. The proposed method shows the great potential of non-visual sensor fusion for avoiding screw misplacement and accidental bone breaches during pedicle drilling and could be extended to further surgical applications.
Improved Techniques for the Conditional Generative Augmentation of Clinical Audio Data
Nov 05, 2022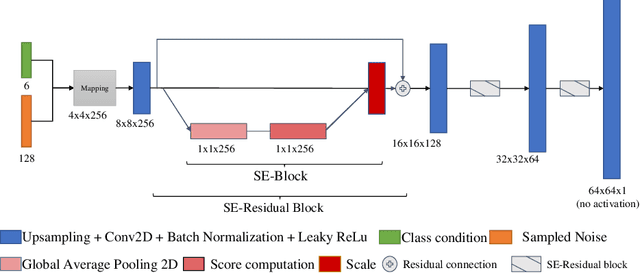

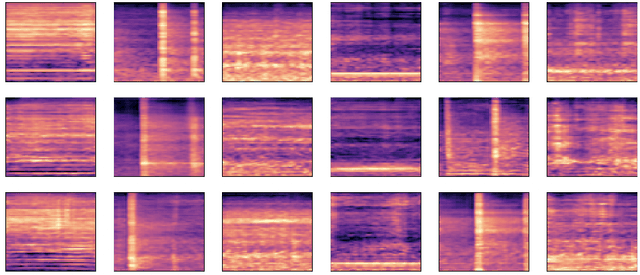
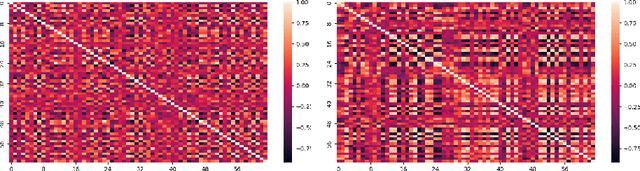
Data augmentation is a valuable tool for the design of deep learning systems to overcome data limitations and stabilize the training process. Especially in the medical domain, where the collection of large-scale data sets is challenging and expensive due to limited access to patient data, relevant environments, as well as strict regulations, community-curated large-scale public datasets, pretrained models, and advanced data augmentation methods are the main factors for developing reliable systems to improve patient care. However, for the development of medical acoustic sensing systems, an emerging field of research, the community lacks large-scale publicly available data sets and pretrained models. To address the problem of limited data, we propose a conditional generative adversarial neural network-based augmentation method which is able to synthesize mel spectrograms from a learned data distribution of a source data set. In contrast to previously proposed fully convolutional models, the proposed model implements residual Squeeze and Excitation modules in the generator architecture. We show that our method outperforms all classical audio augmentation techniques and previously published generative methods in terms of generated sample quality and a performance improvement of 2.84% of Macro F1-Score for a classifier trained on the augmented data set, an enhancement of $1.14\%$ in relation to previous work. By analyzing the correlation of intermediate feature spaces, we show that the residual Squeeze and Excitation modules help the model to reduce redundancy in the latent features. Therefore, the proposed model advances the state-of-the-art in the augmentation of clinical audio data and improves the data bottleneck for the design of clinical acoustic sensing systems.
Sonification as a Reliable Alternative to Conventional Visual Surgical Navigation
Jun 30, 2022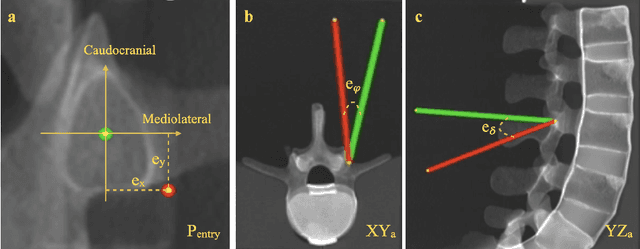
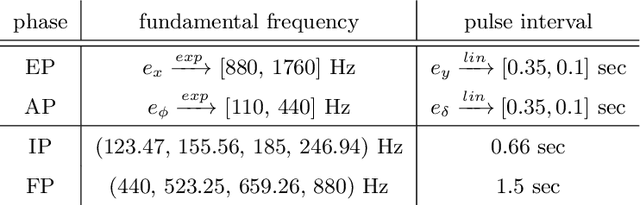
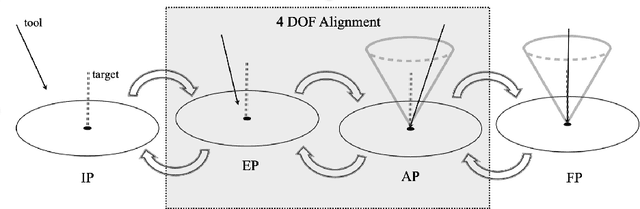
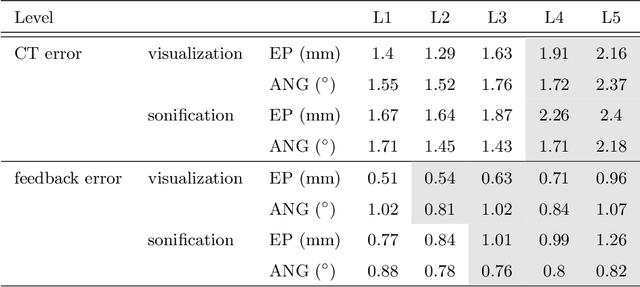
Despite the undeniable advantages of image-guided surgical assistance systems in terms of accuracy, such systems have not yet fully met surgeons' needs or expectations regarding usability, time efficiency, and their integration into the surgical workflow. On the other hand, perceptual studies have shown that presenting independent but causally correlated information via multimodal feedback involving different sensory modalities can improve task performance. This article investigates an alternative method for computer-assisted surgical navigation, introduces a novel sonification methodology for navigated pedicle screw placement, and discusses advanced solutions based on multisensory feedback. The proposed method comprises a novel sonification solution for alignment tasks in four degrees of freedom based on frequency modulation (FM) synthesis. We compared the resulting accuracy and execution time of the proposed sonification method with visual navigation, which is currently considered the state of the art. We conducted a phantom study in which 17 surgeons executed the pedicle screw placement task in the lumbar spine, guided by either the proposed sonification-based or the traditional visual navigation method. The results demonstrated that the proposed method is as accurate as the state of the art while decreasing the surgeon's need to focus on visual navigation displays instead of the natural focus on surgical tools and targeted anatomy during task execution.
Conditional Generative Data Augmentation for Clinical Audio Datasets
Mar 22, 2022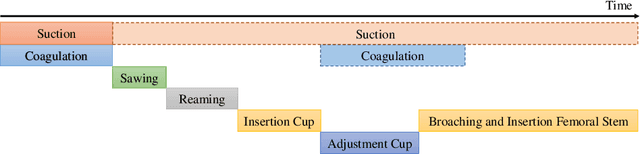
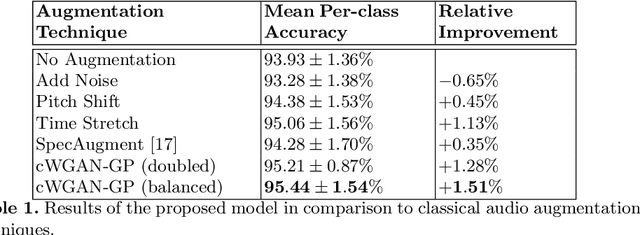
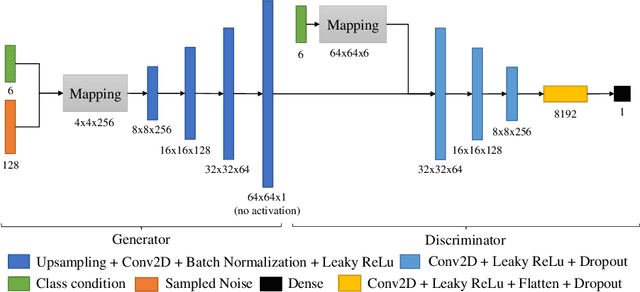
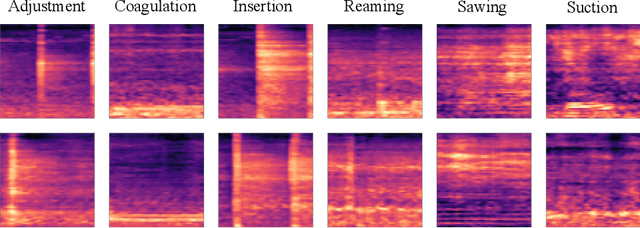
In this work, we propose a novel data augmentation method for clinical audio datasets based on a conditional Wasserstein Generative Adversarial Network with Gradient Penalty (cWGAN-GP), operating on log-mel spectrograms. To validate our method, we created a clinical audio dataset which was recorded in a real-world operating room during Total Hip Arthroplasty (THA) procedures and contains typical sounds which resemble the different phases of the intervention. We demonstrate the capability of the proposed method to generate realistic class-conditioned samples from the dataset distribution and show that training with the generated augmented samples outperforms classical audio augmentation methods in terms of classification accuracy. The performance was evaluated using a ResNet-18 classifier which shows a mean per-class accuracy improvement of 1.51% in a 5-fold cross validation experiment using the proposed augmentation method. Because clinical data is often expensive to acquire, the development of realistic and high-quality data augmentation methods is crucial to improve the robustness and generalization capabilities of learning-based algorithms which is especially important for safety-critical medical applications. Therefore, the proposed data augmentation method is an important step towards improving the data bottleneck for clinical audio-based machine learning systems. The code and dataset will be published upon acceptance.
Pivot calibration concept for sensor attached mobile c-arms
Jan 09, 2020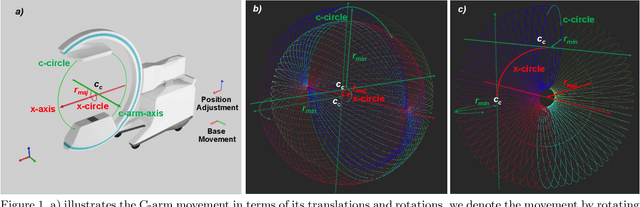
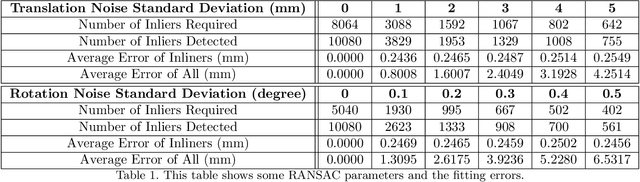


Medical augmented reality has been actively studied for decades and many methods have been proposed torevolutionize clinical procedures. One example is the camera augmented mobile C-arm (CAMC), which providesa real-time video augmentation onto medical images by rigidly mounting and calibrating a camera to the imagingdevice. Since then, several CAMC variations have been suggested by calibrating 2D/3D cameras, trackers, andmore recently a Microsoft HoloLens to the C-arm. Different calibration methods have been applied to establishthe correspondence between the rigidly attached sensor and the imaging device. A crucial step for these methodsis the acquisition of X-Ray images or 3D reconstruction volumes; therefore, requiring the emission of ionizingradiation. In this work, we analyze the mechanical motion of the device and propose an alternatative methodto calibrate sensors to the C-arm without emitting any radiation. Given a sensor is rigidly attached to thedevice, we introduce an extended pivot calibration concept to compute the fixed translation from the sensor tothe C-arm rotation center. The fixed relationship between the sensor and rotation center can be formulated as apivot calibration problem with the pivot point moving on a locus. Our method exploits the rigid C-arm motiondescribing a Torus surface to solve this calibration problem. We explain the geometry of the C-arm motion andits relation to the attached sensor, propose a calibration algorithm and show its robustness against noise, as wellas trajectory and observed pose density by computer simulations. We discuss this geometric-based formulationand its potential extensions to different C-arm applications.