 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Detection and 6D Pose Estimation of Unseen Surgical Instruments
Mar 26, 2026Purpose: Accurate detection and 6D pose estimation of surgical instruments are crucial for many computer-assisted interventions. However, supervised methods lack flexibility for new or unseen tools and require extensive annotated data. This work introduces a training-free pipeline for accurate multi-view 6D pose estimation of unseen surgical instruments, which only requires a textured CAD model as prior knowledge. Methods: Our pipeline consists of two main stages. First, for detection, we generate object mask proposals in each view and score their similarity to rendered templates using a pre-trained feature extractor. Detections are matched across views, triangulated into 3D instance candidates, and filtered using multi-view geometric consistency. Second, for pose estimation, a set of pose hypotheses is iteratively refined and scored using feature-metric scores with cross-view attention. The best hypothesis undergoes a final refinement using a novel multi-view, occlusion-aware contour registration, which minimizes reprojection errors of unoccluded contour points. Results: The proposed method was rigorously evaluated on real-world surgical data from the MVPSP dataset. The method achieves millimeter-accurate pose estimates that are on par with supervised methods under controlled conditions, while maintaining full generalization to unseen instruments. These results demonstrate the feasibility of training-free, marker-less detection and tracking in surgical scenes, and highlight the unique challenges in surgical environments. Conclusion: We present a novel and flexible pipeline that effectively combines state-of-the-art foundational models, multi-view geometry, and contour-based refinement for high-accuracy 6D pose estimation of surgical instruments without task-specific training. This approach enables robust instrument tracking and scene understanding in dynamic clinical environments.
UltraBoneUDF: Self-supervised Bone Surface Reconstruction from Ultrasound Based on Neural Unsigned Distance Functions
May 23, 2025Background: Bone surface reconstruction plays a critical role in computer-assisted orthopedic surgery. Compared to traditional imaging modalities such as CT and MRI, ultrasound offers a radiation-free, cost-effective, and portable alternative. Continuous bone surface reconstruction can be employed for many clinical applications. However, due to the inherent limitations of ultrasound imaging, B-mode ultrasound typically capture only partial bone surfaces. Existing reconstruction methods struggle with such incomplete data, leading to artifacts and increased reconstruction errors. Effective techniques for accurately reconstructing thin and open bone surfaces from real-world 3D ultrasound volumes remain lacking. Methods: We propose UltraBoneUDF, a self-supervised framework designed for reconstructing open bone surfaces from ultrasound using neural Unsigned Distance Functions. To enhance reconstruction quality, we introduce a novel global feature extractor that effectively fuses ultrasound-specific image characteristics. Additionally, we present a novel loss function based on local tangent plane optimization that substantially improves surface reconstruction quality. UltraBoneUDF and baseline models are extensively evaluated on four open-source datasets. Results: Qualitative results highlight the limitations of the state-of-the-art methods for open bone surface reconstruction and demonstrate the effectiveness of UltraBoneUDF. Quantitatively, UltraBoneUDF significantly outperforms competing methods across all evaluated datasets for both open and closed bone surface reconstruction in terms of mean Chamfer distance error: 1.10 mm on the UltraBones100k dataset (39.6\% improvement compared to the SOTA), 0.23 mm on the OpenBoneCT dataset (69.3\% improvement), 0.18 mm on the ClosedBoneCT dataset (70.2\% improvement), and 0.05 mm on the Prostate dataset (55.3\% improvement).
ArthroPhase: A Novel Dataset and Method for Phase Recognition in Arthroscopic Video
Feb 11, 2025



This study aims to advance surgical phase recognition in arthroscopic procedures, specifically Anterior Cruciate Ligament (ACL) reconstruction, by introducing the first arthroscopy dataset and developing a novel transformer-based model. We aim to establish a benchmark for arthroscopic surgical phase recognition by leveraging spatio-temporal features to address the specific challenges of arthroscopic videos including limited field of view, occlusions, and visual distortions. We developed the ACL27 dataset, comprising 27 videos of ACL surgeries, each labeled with surgical phases. Our model employs a transformer-based architecture, utilizing temporal-aware frame-wise feature extraction through a ResNet-50 and transformer layers. This approach integrates spatio-temporal features and introduces a Surgical Progress Index (SPI) to quantify surgery progression. The model's performance was evaluated using accuracy, precision, recall, and Jaccard Index on the ACL27 and Cholec80 datasets. The proposed model achieved an overall accuracy of 72.91% on the ACL27 dataset. On the Cholec80 dataset, the model achieved a comparable performance with the state-of-the-art methods with an accuracy of 92.4%. The SPI demonstrated an output error of 10.6% and 9.86% on ACL27 and Cholec80 datasets respectively, indicating reliable surgery progression estimation. This study introduces a significant advancement in surgical phase recognition for arthroscopy, providing a comprehensive dataset and a robust transformer-based model. The results validate the model's effectiveness and generalizability, highlighting its potential to improve surgical training, real-time assistance, and operational efficiency in orthopedic surgery. The publicly available dataset and code will facilitate future research and development in this critical field.
UltraBones100k: An Ultrasound Image Dataset with CT-Derived Labels for Lower Extremity Long Bone Surface Segmentation
Feb 06, 2025



Ultrasound-based bone surface segmentation is crucial in computer-assisted orthopedic surgery. However, ultrasound images have limitations, including a low signal-to-noise ratio, and acoustic shadowing, which make interpretation difficult. Existing deep learning models for bone segmentation rely primarily on costly manual labeling by experts, limiting dataset size and model generalizability. Additionally, the complexity of ultrasound physics and acoustic shadow makes the images difficult for humans to interpret, leading to incomplete labels in anechoic regions and limiting model performance. To advance ultrasound bone segmentation and establish effective model benchmarks, larger and higher-quality datasets are needed. We propose a methodology for collecting ex-vivo ultrasound datasets with automatically generated bone labels, including anechoic regions. The proposed labels are derived by accurately superimposing tracked bone CT models onto the tracked ultrasound images. These initial labels are refined to account for ultrasound physics. A clinical evaluation is conducted by an expert physician specialized on orthopedic sonography to assess the quality of the generated bone labels. A neural network for bone segmentation is trained on the collected dataset and its predictions are compared to expert manual labels, evaluating accuracy, completeness, and F1-score. We collected the largest known dataset of 100k ultrasound images of human lower limbs with bone labels, called UltraBones100k. A Wilcoxon signed-rank test with Bonferroni correction confirmed that the bone alignment after our method significantly improved the quality of bone labeling (p < 0.001). The model trained on UltraBones100k consistently outperforms manual labeling in all metrics, particularly in low-intensity regions (320% improvement in completeness at a distance threshold of 0.5 mm).
Automatic Calibration of a Multi-Camera System with Limited Overlapping Fields of View for 3D Surgical Scene Reconstruction
Jan 27, 2025Purpose: The purpose of this study is to develop an automated and accurate external camera calibration method for multi-camera systems used in 3D surgical scene reconstruction (3D-SSR), eliminating the need for operator intervention or specialized expertise. The method specifically addresses the problem of limited overlapping fields of view caused by significant variations in optical zoom levels and camera locations. Methods: We contribute a novel, fast, and fully automatic calibration method based on the projection of multi-scale markers (MSMs) using a ceiling-mounted projector. MSMs consist of 2D patterns projected at varying scales, ensuring accurate extraction of well distributed point correspondences across significantly different viewpoints and zoom levels. Validation is performed using both synthetic and real data captured in a mock-up OR, with comparisons to traditional manual marker-based methods as well as markerless calibration methods. Results: The method achieves accuracy comparable to manual, operator-dependent calibration methods while exhibiting higher robustness under conditions of significant differences in zoom levels. Additionally, we show that state-of-the-art Structure-from-Motion (SfM) pipelines are ineffective in 3D-SSR settings, even when additional texture is projected onto the OR floor. Conclusion: The use of a ceiling-mounted entry-level projector proves to be an effective alternative to operator-dependent, traditional marker-based methods, paving the way for fully automated 3D-SSR.
Acquiring Submillimeter-Accurate Multi-Task Vision Datasets for Computer-Assisted Orthopedic Surgery
Jan 26, 2025Advances in computer vision, particularly in optical image-based 3D reconstruction and feature matching, enable applications like marker-less surgical navigation and digitization of surgery. However, their development is hindered by a lack of suitable datasets with 3D ground truth. This work explores an approach to generating realistic and accurate ex vivo datasets tailored for 3D reconstruction and feature matching in open orthopedic surgery. A set of posed images and an accurately registered ground truth surface mesh of the scene are required to develop vision-based 3D reconstruction and matching methods suitable for surgery. We propose a framework consisting of three core steps and compare different methods for each step: 3D scanning, calibration of viewpoints for a set of high-resolution RGB images, and an optical-based method for scene registration. We evaluate each step of this framework on an ex vivo scoliosis surgery using a pig spine, conducted under real operating room conditions. A mean 3D Euclidean error of 0.35 mm is achieved with respect to the 3D ground truth. The proposed method results in submillimeter accurate 3D ground truths and surgical images with a spatial resolution of 0.1 mm. This opens the door to acquiring future surgical datasets for high-precision applications.
Creating a Digital Twin of Spinal Surgery: A Proof of Concept
Mar 25, 2024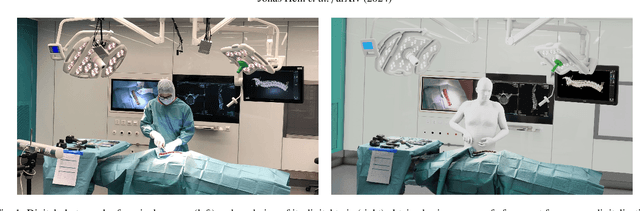
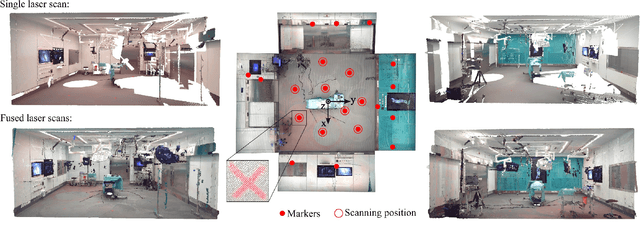
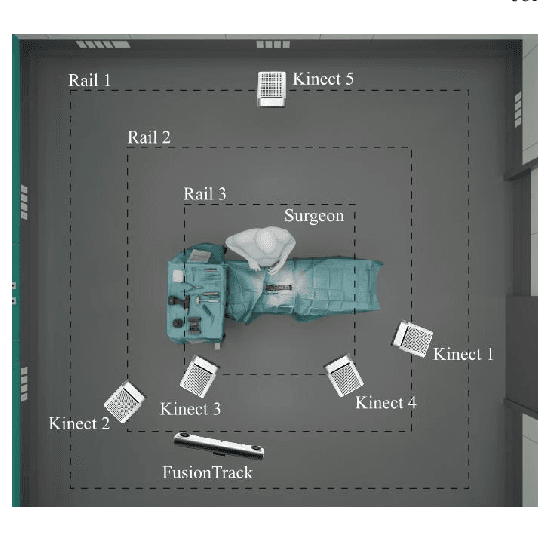
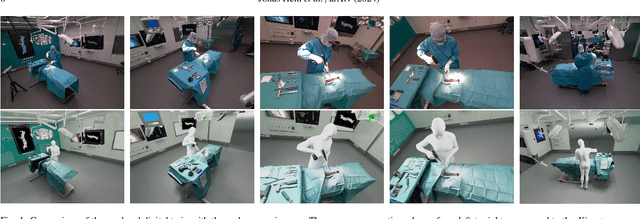
Surgery digitalization is the process of creating a virtual replica of real-world surgery, also referred to as a surgical digital twin (SDT). It has significant applications in various fields such as education and training, surgical planning, and automation of surgical tasks. Given their detailed representations of surgical procedures, SDTs are an ideal foundation for machine learning methods, enabling automatic generation of training data. In robotic surgery, SDTs can provide realistic virtual environments in which robots may learn through trial and error. In this paper, we present a proof of concept (PoC) for surgery digitalization that is applied to an ex-vivo spinal surgery performed in realistic conditions. The proposed digitalization focuses on the acquisition and modelling of the geometry and appearance of the entire surgical scene. We employ five RGB-D cameras for dynamic 3D reconstruction of the surgeon, a high-end camera for 3D reconstruction of the anatomy, an infrared stereo camera for surgical instrument tracking, and a laser scanner for 3D reconstruction of the operating room and data fusion. We justify the proposed methodology, discuss the challenges faced and further extensions of our prototype. While our PoC partially relies on manual data curation, its high quality and great potential motivate the development of automated methods for the creation of SDTs. The quality of our SDT can be assessed in a rendered video available at https://youtu.be/LqVaWGgaTMY .
Next-generation Surgical Navigation: Multi-view Marker-less 6DoF Pose Estimation of Surgical Instruments
May 05, 2023



State-of-the-art research of traditional computer vision is increasingly leveraged in the surgical domain. A particular focus in computer-assisted surgery is to replace marker-based tracking systems for instrument localization with pure image-based 6DoF pose estimation. However, the state of the art has not yet met the accuracy required for surgical navigation. In this context, we propose a high-fidelity marker-less optical tracking system for surgical instrument localization. We developed a multi-view camera setup consisting of static and mobile cameras and collected a large-scale RGB-D video dataset with dedicated synchronization and data fusions methods. Different state-of-the-art pose estimation methods were integrated into a deep learning pipeline and evaluated on multiple camera configurations. Furthermore, the performance impacts of different input modalities and camera positions, as well as training on purely synthetic data, were compared. The best model achieved an average position and orientation error of 1.3 mm and 1.0{\deg} for a surgical drill as well as 3.8 mm and 5.2{\deg} for a screwdriver. These results significantly outperform related methods in the literature and are close to clinical-grade accuracy, demonstrating that marker-less tracking of surgical instruments is becoming a feasible alternative to existing marker-based systems.