 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHART: Human Aligned Reconstruction Transformer
Sep 30, 2025



We introduce HART, a unified framework for sparse-view human reconstruction. Given a small set of uncalibrated RGB images of a person as input, it outputs a watertight clothed mesh, the aligned SMPL-X body mesh, and a Gaussian-splat representation for photorealistic novel-view rendering. Prior methods for clothed human reconstruction either optimize parametric templates, which overlook loose garments and human-object interactions, or train implicit functions under simplified camera assumptions, limiting applicability in real scenes. In contrast, HART predicts per-pixel 3D point maps, normals, and body correspondences, and employs an occlusion-aware Poisson reconstruction to recover complete geometry, even in self-occluded regions. These predictions also align with a parametric SMPL-X body model, ensuring that reconstructed geometry remains consistent with human structure while capturing loose clothing and interactions. These human-aligned meshes initialize Gaussian splats to further enable sparse-view rendering. While trained on only 2.3K synthetic scans, HART achieves state-of-the-art results: Chamfer Distance improves by 18-23 percent for clothed-mesh reconstruction, PA-V2V drops by 6-27 percent for SMPL-X estimation, LPIPS decreases by 15-27 percent for novel-view synthesis on a wide range of datasets. These results suggest that feed-forward transformers can serve as a scalable model for robust human reconstruction in real-world settings. Code and models will be released.
Multi-View 3D Point Tracking
Aug 28, 2025We introduce the first data-driven multi-view 3D point tracker, designed to track arbitrary points in dynamic scenes using multiple camera views. Unlike existing monocular trackers, which struggle with depth ambiguities and occlusion, or prior multi-camera methods that require over 20 cameras and tedious per-sequence optimization, our feed-forward model directly predicts 3D correspondences using a practical number of cameras (e.g., four), enabling robust and accurate online tracking. Given known camera poses and either sensor-based or estimated multi-view depth, our tracker fuses multi-view features into a unified point cloud and applies k-nearest-neighbors correlation alongside a transformer-based update to reliably estimate long-range 3D correspondences, even under occlusion. We train on 5K synthetic multi-view Kubric sequences and evaluate on two real-world benchmarks: Panoptic Studio and DexYCB, achieving median trajectory errors of 3.1 cm and 2.0 cm, respectively. Our method generalizes well to diverse camera setups of 1-8 views with varying vantage points and video lengths of 24-150 frames. By releasing our tracker alongside training and evaluation datasets, we aim to set a new standard for multi-view 3D tracking research and provide a practical tool for real-world applications. Project page available at https://ethz-vlg.github.io/mvtracker.
SplatFormer: Point Transformer for Robust 3D Gaussian Splatting
Nov 12, 2024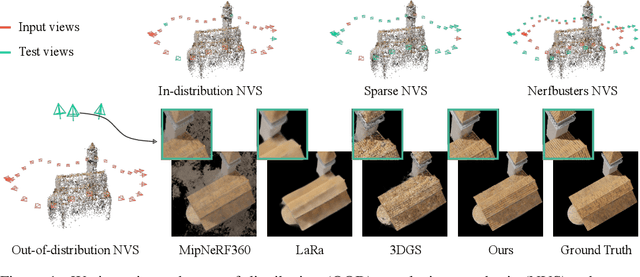
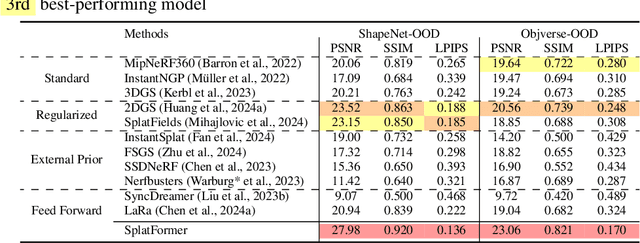
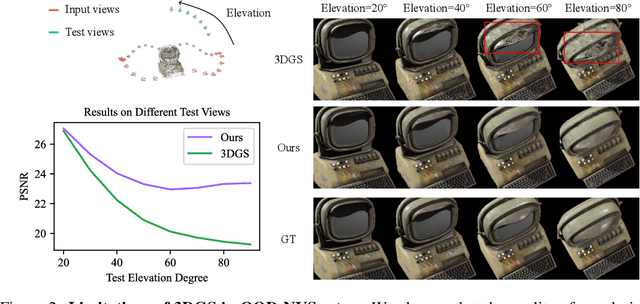
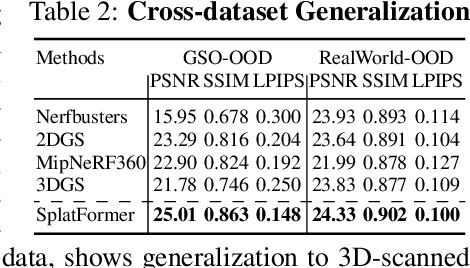
3D Gaussian Splatting (3DGS) has recently transformed photorealistic reconstruction, achieving high visual fidelity and real-time performance. However, rendering quality significantly deteriorates when test views deviate from the camera angles used during training, posing a major challenge for applications in immersive free-viewpoint rendering and navigation. In this work, we conduct a comprehensive evaluation of 3DGS and related novel view synthesis methods under out-of-distribution (OOD) test camera scenarios. By creating diverse test cases with synthetic and real-world datasets, we demonstrate that most existing methods, including those incorporating various regularization techniques and data-driven priors, struggle to generalize effectively to OOD views. To address this limitation, we introduce SplatFormer, the first point transformer model specifically designed to operate on Gaussian splats. SplatFormer takes as input an initial 3DGS set optimized under limited training views and refines it in a single forward pass, effectively removing potential artifacts in OOD test views. To our knowledge, this is the first successful application of point transformers directly on 3DGS sets, surpassing the limitations of previous multi-scene training methods, which could handle only a restricted number of input views during inference. Our model significantly improves rendering quality under extreme novel views, achieving state-of-the-art performance in these challenging scenarios and outperforming various 3DGS regularization techniques, multi-scene models tailored for sparse view synthesis, and diffusion-based frameworks.
FreSh: Frequency Shifting for Accelerated Neural Representation Learning
Oct 07, 2024Implicit Neural Representations (INRs) have recently gained attention as a powerful approach for continuously representing signals such as images, videos, and 3D shapes using multilayer perceptrons (MLPs). However, MLPs are known to exhibit a low-frequency bias, limiting their ability to capture high-frequency details accurately. This limitation is typically addressed by incorporating high-frequency input embeddings or specialized activation layers. In this work, we demonstrate that these embeddings and activations are often configured with hyperparameters that perform well on average but are suboptimal for specific input signals under consideration, necessitating a costly grid search to identify optimal settings. Our key observation is that the initial frequency spectrum of an untrained model's output correlates strongly with the model's eventual performance on a given target signal. Leveraging this insight, we propose frequency shifting (or FreSh), a method that selects embedding hyperparameters to align the frequency spectrum of the model's initial output with that of the target signal. We show that this simple initialization technique improves performance across various neural representation methods and tasks, achieving results comparable to extensive hyperparameter sweeps but with only marginal computational overhead compared to training a single model with default hyperparameters.
RISE-SDF: a Relightable Information-Shared Signed Distance Field for Glossy Object Inverse Rendering
Sep 30, 2024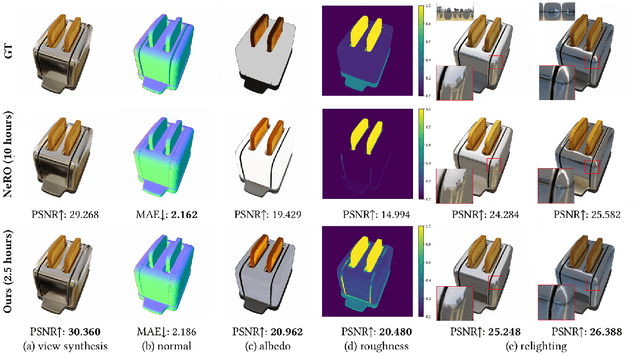
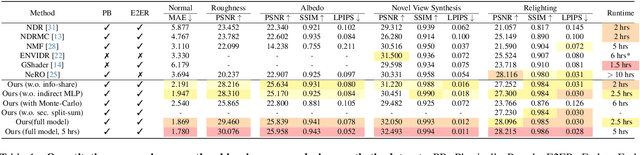
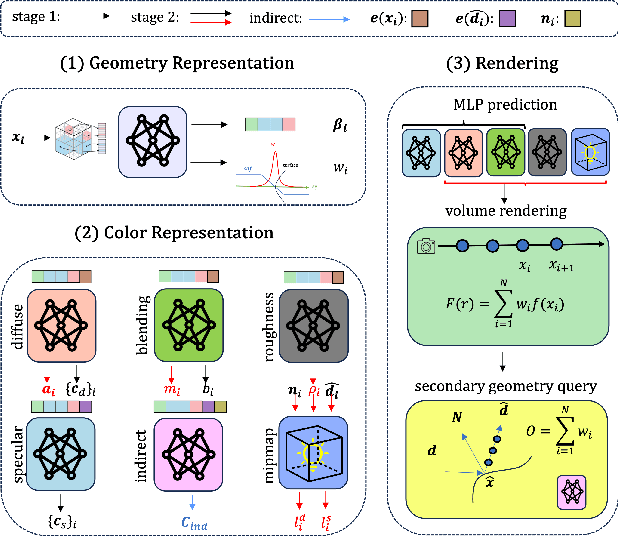

In this paper, we propose a novel end-to-end relightable neural inverse rendering system that achieves high-quality reconstruction of geometry and material properties, thus enabling high-quality relighting. The cornerstone of our method is a two-stage approach for learning a better factorization of scene parameters. In the first stage, we develop a reflection-aware radiance field using a neural signed distance field (SDF) as the geometry representation and deploy an MLP (multilayer perceptron) to estimate indirect illumination. In the second stage, we introduce a novel information-sharing network structure to jointly learn the radiance field and the physically based factorization of the scene. For the physically based factorization, to reduce the noise caused by Monte Carlo sampling, we apply a split-sum approximation with a simplified Disney BRDF and cube mipmap as the environment light representation. In the relighting phase, to enhance the quality of indirect illumination, we propose a second split-sum algorithm to trace secondary rays under the split-sum rendering framework.Furthermore, there is no dataset or protocol available to quantitatively evaluate the inverse rendering performance for glossy objects. To assess the quality of material reconstruction and relighting, we have created a new dataset with ground truth BRDF parameters and relighting results. Our experiments demonstrate that our algorithm achieves state-of-the-art performance in inverse rendering and relighting, with particularly strong results in the reconstruction of highly reflective objects.
SplatFields: Neural Gaussian Splats for Sparse 3D and 4D Reconstruction
Sep 17, 2024



Digitizing 3D static scenes and 4D dynamic events from multi-view images has long been a challenge in computer vision and graphics. Recently, 3D Gaussian Splatting (3DGS) has emerged as a practical and scalable reconstruction method, gaining popularity due to its impressive reconstruction quality, real-time rendering capabilities, and compatibility with widely used visualization tools. However, the method requires a substantial number of input views to achieve high-quality scene reconstruction, introducing a significant practical bottleneck. This challenge is especially severe in capturing dynamic scenes, where deploying an extensive camera array can be prohibitively costly. In this work, we identify the lack of spatial autocorrelation of splat features as one of the factors contributing to the suboptimal performance of the 3DGS technique in sparse reconstruction settings. To address the issue, we propose an optimization strategy that effectively regularizes splat features by modeling them as the outputs of a corresponding implicit neural field. This results in a consistent enhancement of reconstruction quality across various scenarios. Our approach effectively handles static and dynamic cases, as demonstrated by extensive testing across different setups and scene complexities.
Degrees of Freedom Matter: Inferring Dynamics from Point Trajectories
Jun 05, 2024



Understanding the dynamics of generic 3D scenes is fundamentally challenging in computer vision, essential in enhancing applications related to scene reconstruction, motion tracking, and avatar creation. In this work, we address the task as the problem of inferring dense, long-range motion of 3D points. By observing a set of point trajectories, we aim to learn an implicit motion field parameterized by a neural network to predict the movement of novel points within the same domain, without relying on any data-driven or scene-specific priors. To achieve this, our approach builds upon the recently introduced dynamic point field model that learns smooth deformation fields between the canonical frame and individual observation frames. However, temporal consistency between consecutive frames is neglected, and the number of required parameters increases linearly with the sequence length due to per-frame modeling. To address these shortcomings, we exploit the intrinsic regularization provided by SIREN, and modify the input layer to produce a spatiotemporally smooth motion field. Additionally, we analyze the motion field Jacobian matrix, and discover that the motion degrees of freedom (DOFs) in an infinitesimal area around a point and the network hidden variables have different behaviors to affect the model's representational power. This enables us to improve the model representation capability while retaining the model compactness. Furthermore, to reduce the risk of overfitting, we introduce a regularization term based on the assumption of piece-wise motion smoothness. Our experiments assess the model's performance in predicting unseen point trajectories and its application in temporal mesh alignment with guidance. The results demonstrate its superiority and effectiveness. The code and data for the project are publicly available: \url{https://yz-cnsdqz.github.io/eigenmotion/DOMA/}
Creating a Digital Twin of Spinal Surgery: A Proof of Concept
Mar 25, 2024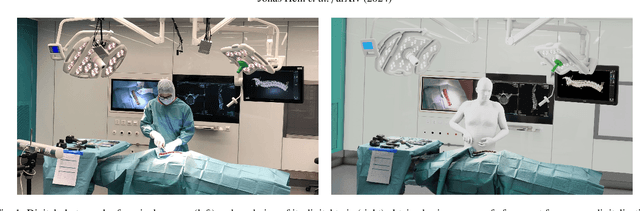
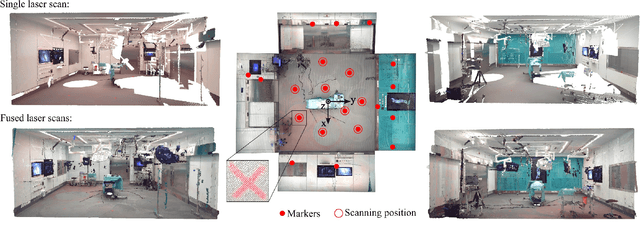
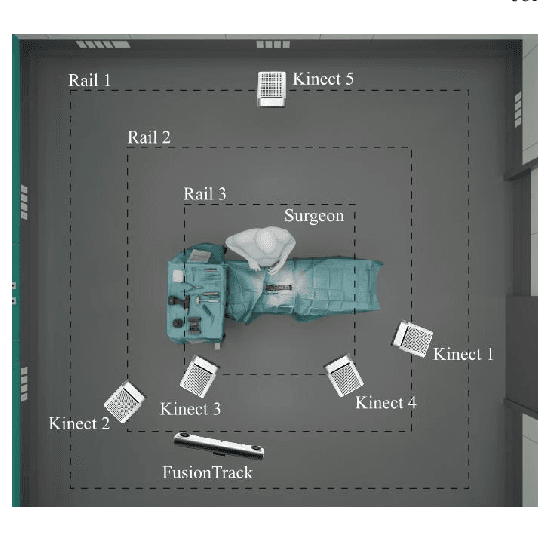
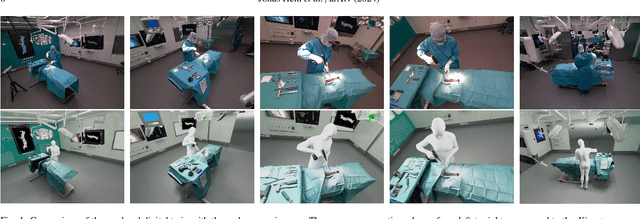
Surgery digitalization is the process of creating a virtual replica of real-world surgery, also referred to as a surgical digital twin (SDT). It has significant applications in various fields such as education and training, surgical planning, and automation of surgical tasks. Given their detailed representations of surgical procedures, SDTs are an ideal foundation for machine learning methods, enabling automatic generation of training data. In robotic surgery, SDTs can provide realistic virtual environments in which robots may learn through trial and error. In this paper, we present a proof of concept (PoC) for surgery digitalization that is applied to an ex-vivo spinal surgery performed in realistic conditions. The proposed digitalization focuses on the acquisition and modelling of the geometry and appearance of the entire surgical scene. We employ five RGB-D cameras for dynamic 3D reconstruction of the surgeon, a high-end camera for 3D reconstruction of the anatomy, an infrared stereo camera for surgical instrument tracking, and a laser scanner for 3D reconstruction of the operating room and data fusion. We justify the proposed methodology, discuss the challenges faced and further extensions of our prototype. While our PoC partially relies on manual data curation, its high quality and great potential motivate the development of automated methods for the creation of SDTs. The quality of our SDT can be assessed in a rendered video available at https://youtu.be/LqVaWGgaTMY .
Morphable Diffusion: 3D-Consistent Diffusion for Single-image Avatar Creation
Jan 09, 2024



Recent advances in generative diffusion models have enabled the previously unfeasible capability of generating 3D assets from a single input image or a text prompt. In this work, we aim to enhance the quality and functionality of these models for the task of creating controllable, photorealistic human avatars. We achieve this by integrating a 3D morphable model into the state-of-the-art multiview-consistent diffusion approach. We demonstrate that accurate conditioning of a generative pipeline on the articulated 3D model enhances the baseline model performance on the task of novel view synthesis from a single image. More importantly, this integration facilitates a seamless and accurate incorporation of facial expression and body pose control into the generation process. To the best of our knowledge, our proposed framework is the first diffusion model to enable the creation of fully 3D-consistent, animatable, and photorealistic human avatars from a single image of an unseen subject; extensive quantitative and qualitative evaluations demonstrate the advantages of our approach over existing state-of-the-art avatar creation models on both novel view and novel expression synthesis tasks.
ResFields: Residual Neural Fields for Spatiotemporal Signals
Sep 06, 2023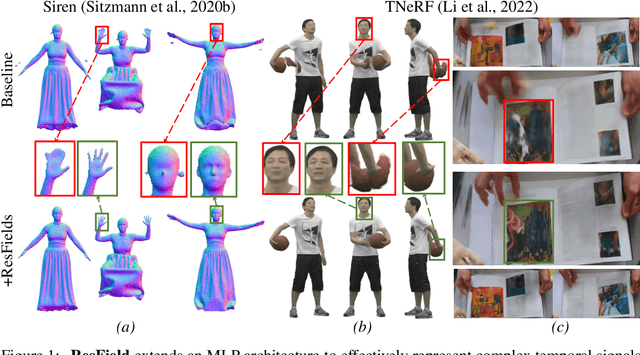
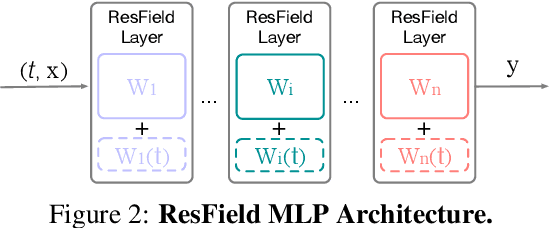
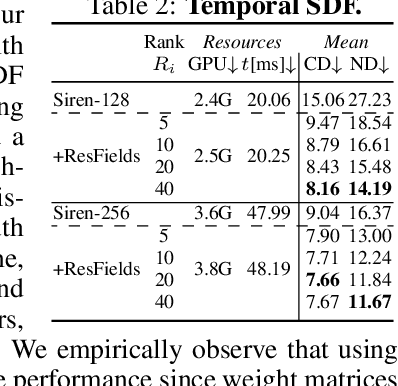
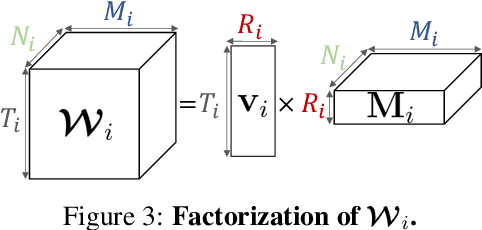
Neural fields, a category of neural networks trained to represent high-frequency signals, have gained significant attention in recent years due to their impressive performance in modeling complex 3D data, especially large neural signed distance (SDFs) or radiance fields (NeRFs) via a single multi-layer perceptron (MLP). However, despite the power and simplicity of representing signals with an MLP, these methods still face challenges when modeling large and complex temporal signals due to the limited capacity of MLPs. In this paper, we propose an effective approach to address this limitation by incorporating temporal residual layers into neural fields, dubbed ResFields, a novel class of networks specifically designed to effectively represent complex temporal signals. We conduct a comprehensive analysis of the properties of ResFields and propose a matrix factorization technique to reduce the number of trainable parameters and enhance generalization capabilities. Importantly, our formulation seamlessly integrates with existing techniques and consistently improves results across various challenging tasks: 2D video approximation, dynamic shape modeling via temporal SDFs, and dynamic NeRF reconstruction. Lastly, we demonstrate the practical utility of ResFields by showcasing its effectiveness in capturing dynamic 3D scenes from sparse sensory inputs of a lightweight capture system.