 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM$^3$-DTI: A Large Language Model and Multi-modal data co-powered framework for Drug-Target Interaction prediction
Nov 09, 2025Drug-target interaction (DTI) prediction is of great significance for drug discovery and drug repurposing. With the accumulation of a large volume of valuable data, data-driven methods have been increasingly harnessed to predict DTIs, reducing costs across various dimensions. Therefore, this paper proposes a $\textbf{L}$arge $\textbf{L}$anguage $\textbf{M}$odel and $\textbf{M}$ulti-$\textbf{M}$odel data co-powered $\textbf{D}$rug $\textbf{T}$arget $\textbf{I}$nteraction prediction framework, named LLM$^3$-DTI. LLM$^3$-DTI constructs multi-modal data embedding to enhance DTI prediction performance. In this framework, the text semantic embeddings of drugs and targets are encoded by a domain-specific LLM. To effectively align and fuse multi-modal embedding. We propose the dual cross-attention mechanism and the TSFusion module. Finally, these multi-modal data are utilized for the DTI task through an output network. The experimental results indicate that LLM$^3$-DTI can proficiently identify validated DTIs, surpassing the performance of the models employed for comparison across diverse scenarios. Consequently, LLM$^3$-DTI is adept at fulfilling the task of DTI prediction with excellence. The data and code are available at https://github.com/chaser-gua/LLM3DTI.
HART: Human Aligned Reconstruction Transformer
Sep 30, 2025



We introduce HART, a unified framework for sparse-view human reconstruction. Given a small set of uncalibrated RGB images of a person as input, it outputs a watertight clothed mesh, the aligned SMPL-X body mesh, and a Gaussian-splat representation for photorealistic novel-view rendering. Prior methods for clothed human reconstruction either optimize parametric templates, which overlook loose garments and human-object interactions, or train implicit functions under simplified camera assumptions, limiting applicability in real scenes. In contrast, HART predicts per-pixel 3D point maps, normals, and body correspondences, and employs an occlusion-aware Poisson reconstruction to recover complete geometry, even in self-occluded regions. These predictions also align with a parametric SMPL-X body model, ensuring that reconstructed geometry remains consistent with human structure while capturing loose clothing and interactions. These human-aligned meshes initialize Gaussian splats to further enable sparse-view rendering. While trained on only 2.3K synthetic scans, HART achieves state-of-the-art results: Chamfer Distance improves by 18-23 percent for clothed-mesh reconstruction, PA-V2V drops by 6-27 percent for SMPL-X estimation, LPIPS decreases by 15-27 percent for novel-view synthesis on a wide range of datasets. These results suggest that feed-forward transformers can serve as a scalable model for robust human reconstruction in real-world settings. Code and models will be released.
SplatFormer: Point Transformer for Robust 3D Gaussian Splatting
Nov 12, 2024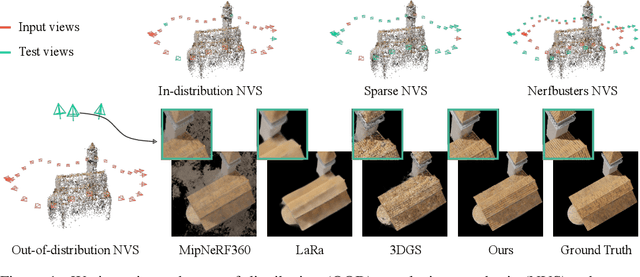
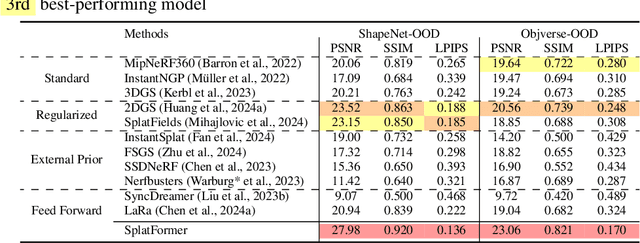
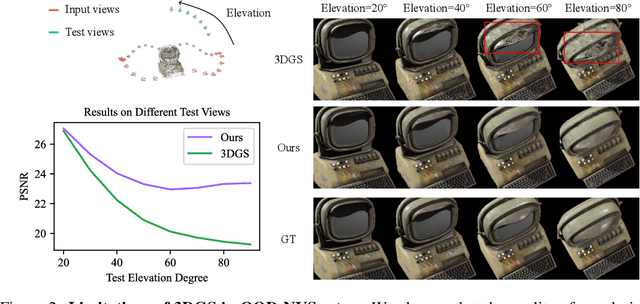
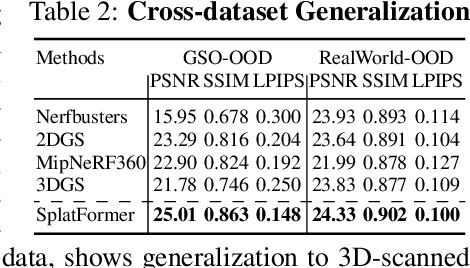
3D Gaussian Splatting (3DGS) has recently transformed photorealistic reconstruction, achieving high visual fidelity and real-time performance. However, rendering quality significantly deteriorates when test views deviate from the camera angles used during training, posing a major challenge for applications in immersive free-viewpoint rendering and navigation. In this work, we conduct a comprehensive evaluation of 3DGS and related novel view synthesis methods under out-of-distribution (OOD) test camera scenarios. By creating diverse test cases with synthetic and real-world datasets, we demonstrate that most existing methods, including those incorporating various regularization techniques and data-driven priors, struggle to generalize effectively to OOD views. To address this limitation, we introduce SplatFormer, the first point transformer model specifically designed to operate on Gaussian splats. SplatFormer takes as input an initial 3DGS set optimized under limited training views and refines it in a single forward pass, effectively removing potential artifacts in OOD test views. To our knowledge, this is the first successful application of point transformers directly on 3DGS sets, surpassing the limitations of previous multi-scene training methods, which could handle only a restricted number of input views during inference. Our model significantly improves rendering quality under extreme novel views, achieving state-of-the-art performance in these challenging scenarios and outperforming various 3DGS regularization techniques, multi-scene models tailored for sparse view synthesis, and diffusion-based frameworks.
Morphable Diffusion: 3D-Consistent Diffusion for Single-image Avatar Creation
Jan 09, 2024



Recent advances in generative diffusion models have enabled the previously unfeasible capability of generating 3D assets from a single input image or a text prompt. In this work, we aim to enhance the quality and functionality of these models for the task of creating controllable, photorealistic human avatars. We achieve this by integrating a 3D morphable model into the state-of-the-art multiview-consistent diffusion approach. We demonstrate that accurate conditioning of a generative pipeline on the articulated 3D model enhances the baseline model performance on the task of novel view synthesis from a single image. More importantly, this integration facilitates a seamless and accurate incorporation of facial expression and body pose control into the generation process. To the best of our knowledge, our proposed framework is the first diffusion model to enable the creation of fully 3D-consistent, animatable, and photorealistic human avatars from a single image of an unseen subject; extensive quantitative and qualitative evaluations demonstrate the advantages of our approach over existing state-of-the-art avatar creation models on both novel view and novel expression synthesis tasks.