 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory-Guided Diffusion for Foreground-Preserving Background Generation in Multi-Layer Documents
Jan 29, 2026We present a diffusion-based framework for document-centric background generation that achieves foreground preservation and multi-page stylistic consistency through latent-space design rather than explicit constraints. Instead of suppressing diffusion updates or applying masking heuristics, our approach reinterprets diffusion as the evolution of stochastic trajectories through a structured latent space. By shaping the initial noise and its geometric alignment, background generation naturally avoids designated foreground regions, allowing readable content to remain intact without auxiliary mechanisms. To address the long-standing issue of stylistic drift across pages, we decouple style control from text conditioning and introduce cached style directions as persistent vectors in latent space. Once selected, these directions constrain diffusion trajectories to a shared stylistic subspace, ensuring consistent appearance across pages and editing iterations. This formulation eliminates the need for repeated prompt-based style specification and provides a more stable foundation for multi-page generation. Our framework admits a geometric and physical interpretation, where diffusion paths evolve on a latent manifold shaped by preferred directions, and foreground regions are rarely traversed as a consequence of trajectory initialization rather than explicit exclusion. The proposed method is training-free, compatible with existing diffusion backbones, and produces visually coherent, foreground-preserving results across complex documents. By reframing diffusion as trajectory design in latent space, we offer a principled approach to consistent and structured generative modeling.
Text-Conditioned Background Generation for Editable Multi-Layer Documents
Dec 19, 2025



We present a framework for document-centric background generation with multi-page editing and thematic continuity. To ensure text regions remain readable, we employ a \emph{latent masking} formulation that softly attenuates updates in the diffusion space, inspired by smooth barrier functions in physics and numerical optimization. In addition, we introduce \emph{Automated Readability Optimization (ARO)}, which automatically places semi-transparent, rounded backing shapes behind text regions. ARO determines the minimal opacity needed to satisfy perceptual contrast standards (WCAG 2.2) relative to the underlying background, ensuring readability while maintaining aesthetic harmony without human intervention. Multi-page consistency is maintained through a summarization-and-instruction process, where each page is distilled into a compact representation that recursively guides subsequent generations. This design reflects how humans build continuity by retaining prior context, ensuring that visual motifs evolve coherently across an entire document. Our method further treats a document as a structured composition in which text, figures, and backgrounds are preserved or regenerated as separate layers, allowing targeted background editing without compromising readability. Finally, user-provided prompts allow stylistic adjustments in color and texture, balancing automated consistency with flexible customization. Our training-free framework produces visually coherent, text-preserving, and thematically aligned documents, bridging generative modeling with natural design workflows.
HART: Human Aligned Reconstruction Transformer
Sep 30, 2025



We introduce HART, a unified framework for sparse-view human reconstruction. Given a small set of uncalibrated RGB images of a person as input, it outputs a watertight clothed mesh, the aligned SMPL-X body mesh, and a Gaussian-splat representation for photorealistic novel-view rendering. Prior methods for clothed human reconstruction either optimize parametric templates, which overlook loose garments and human-object interactions, or train implicit functions under simplified camera assumptions, limiting applicability in real scenes. In contrast, HART predicts per-pixel 3D point maps, normals, and body correspondences, and employs an occlusion-aware Poisson reconstruction to recover complete geometry, even in self-occluded regions. These predictions also align with a parametric SMPL-X body model, ensuring that reconstructed geometry remains consistent with human structure while capturing loose clothing and interactions. These human-aligned meshes initialize Gaussian splats to further enable sparse-view rendering. While trained on only 2.3K synthetic scans, HART achieves state-of-the-art results: Chamfer Distance improves by 18-23 percent for clothed-mesh reconstruction, PA-V2V drops by 6-27 percent for SMPL-X estimation, LPIPS decreases by 15-27 percent for novel-view synthesis on a wide range of datasets. These results suggest that feed-forward transformers can serve as a scalable model for robust human reconstruction in real-world settings. Code and models will be released.
Enhancing eLoran Timing Accuracy via Machine Learning with Meteorological and Terrain Data
Jun 18, 2025The vulnerabilities of global navigation satellite systems (GNSS) to signal interference have increased the demand for complementary positioning, navigation, and timing (PNT) systems. To address this, South Korea has decided to deploy an enhanced long-range navigation (eLoran) system as a complementary PNT solution. Similar to GNSS, eLoran provides highly accurate timing information, which is essential for applications such as telecommunications, financial systems, and power distribution. However, the primary sources of error for GNSS and eLoran differ. For eLoran, the main source of error is signal propagation delay over land, known as the additional secondary factor (ASF). This delay, influenced by ground conductivity and weather conditions along the signal path, is challenging to predict and mitigate. In this paper, we measure the time difference (TD) between GPS and eLoran using a time interval counter and analyze the correlations between eLoran/GPS TD and eleven meteorological factors. Accurate estimation of eLoran/GPS TD could enable eLoran to achieve timing accuracy comparable to that of GPS. We propose two estimation models for eLoran/GPS TD and compare their performance with existing TD estimation methods. The proposed WLR-AGRNN model captures the linear relationships between meteorological factors and eLoran/GPS TD using weighted linear regression (WLR) and models nonlinear relationships between outputs from expert networks through an anisotropic general regression neural network (AGRNN). The model incorporates terrain elevation to appropriately weight meteorological data, as elevation influences signal propagation delay. Experimental results based on four months of data demonstrate that the WLR-AGRNN model outperforms other models, highlighting its effectiveness in improving eLoran/GPS TD estimation accuracy.
Action2Dialogue: Generating Character-Centric Narratives from Scene-Level Prompts
May 22, 2025Recent advances in scene-based video generation have enabled systems to synthesize coherent visual narratives from structured prompts. However, a crucial dimension of storytelling -- character-driven dialogue and speech -- remains underexplored. In this paper, we present a modular pipeline that transforms action-level prompts into visually and auditorily grounded narrative dialogue, enriching visual storytelling with natural voice and character expression. Our method takes as input a pair of prompts per scene, where the first defines the setting and the second specifies a character's behavior. While a story generation model such as Text2Story generates the corresponding visual scene, we focus on generating expressive character utterances from these prompts and the scene image. We apply a pretrained vision-language encoder to extract a high-level semantic feature from the representative frame, capturing salient visual context. This feature is then combined with the structured prompts and used to guide a large language model in synthesizing natural, character-consistent dialogue. To ensure contextual consistency across scenes, we introduce a Recursive Narrative Bank that conditions each dialogue generation on the accumulated dialogue history from prior scenes. This approach enables characters to speak in ways that reflect their evolving goals and interactions throughout a story. Finally, we render each utterance as expressive, character-consistent speech, resulting in fully-voiced video narratives. Our framework requires no additional training and demonstrates applicability across a variety of story settings, from fantasy adventures to slice-of-life episodes.
Text2Story: Advancing Video Storytelling with Text Guidance
Mar 08, 2025



Generating coherent long-form video sequences from discrete input using only text prompts is a critical task in content creation. While diffusion-based models excel at short video synthesis, long-form storytelling from text remains largely unexplored and a challenge due to challenges pertaining to temporal coherency, preserving semantic meaning and action continuity across the video. We introduce a novel storytelling approach to enable seamless video generation with natural action transitions and structured narratives. We present a bidirectional time-weighted latent blending strategy to ensure temporal consistency between segments of the long-form video being generated. Further, our method extends the Black-Scholes algorithm from prompt mixing for image generation to video generation, enabling controlled motion evolution through structured text conditioning. To further enhance motion continuity, we propose a semantic action representation framework to encode high-level action semantics into the blending process, dynamically adjusting transitions based on action similarity, ensuring smooth yet adaptable motion changes. Latent space blending maintains spatial coherence between objects in a scene, while time-weighted blending enforces bidirectional constraints for temporal consistency. This integrative approach prevents abrupt transitions while ensuring fluid storytelling. Extensive experiments demonstrate significant improvements over baselines, achieving temporally consistent and visually compelling video narratives without any additional training. Our approach bridges the gap between short clips and extended video to establish a new paradigm in GenAI-driven video synthesis from text.
Novel View Synthesis from a Single Image with Pretrained Diffusion Guidance
Aug 12, 2024



Recent 3D novel view synthesis (NVS) methods are limited to single-object-centric scenes generated from new viewpoints and struggle with complex environments. They often require extensive 3D data for training, lacking generalization beyond training distribution. Conversely, 3D-free methods can generate text-controlled views of complex, in-the-wild scenes using a pretrained stable diffusion model without tedious fine-tuning, but lack camera control. In this paper, we introduce HawkI++, a method capable of generating camera-controlled viewpoints from a single input image. HawkI++ excels in handling complex and diverse scenes without additional 3D data or extensive training. It leverages widely available pretrained NVS models for weak guidance, integrating this knowledge into a 3D-free view synthesis approach to achieve the desired results efficiently. Our experimental results demonstrate that HawkI++ outperforms existing models in both qualitative and quantitative evaluations, providing high-fidelity and consistent novel view synthesis at desired camera angles across a wide variety of scenes.
Detection of Pedestrian Turning Motions to Enhance Indoor Map Matching Performance
Sep 04, 2023A pedestrian navigation system (PNS) in indoor environments, where global navigation satellite system (GNSS) signal access is difficult, is necessary, particularly for search and rescue (SAR) operations in large buildings. This paper focuses on studying pedestrian walking behaviors to enhance the performance of indoor pedestrian dead reckoning (PDR) and map matching techniques. Specifically, our research aims to detect pedestrian turning motions using smartphone inertial measurement unit (IMU) information in a given PDR trajectory. To improve existing methods, including the threshold-based turn detection method, hidden Markov model (HMM)-based turn detection method, and pruned exact linear time (PELT) algorithm-based turn detection method, we propose enhanced algorithms that better detect pedestrian turning motions. During field tests, using the threshold-based method, we observed a missed detection rate of 20.35% and a false alarm rate of 7.65%. The PELT-based method achieved a significant improvement with a missed detection rate of 8.93% and a false alarm rate of 6.97%. However, the best results were obtained using the HMM-based method, which demonstrated a missed detection rate of 5.14% and a false alarm rate of 2.00%. In summary, our research contributes to the development of a more accurate and reliable pedestrian navigation system by leveraging smartphone IMU data and advanced algorithms for turn detection in indoor environments.
Evaluation of RF Fingerprinting-Aided RSS-Based Target Localization for Emergency Response
Jun 19, 2022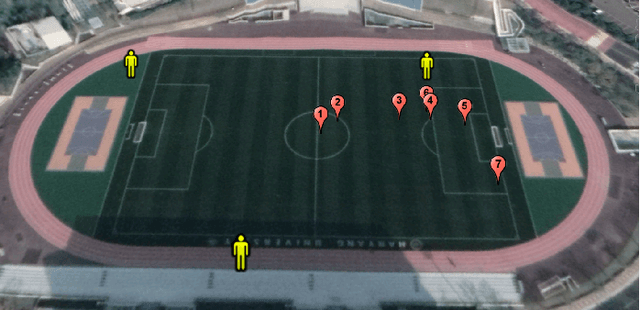
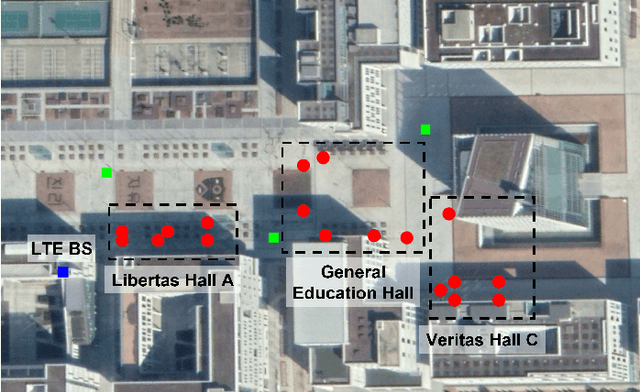
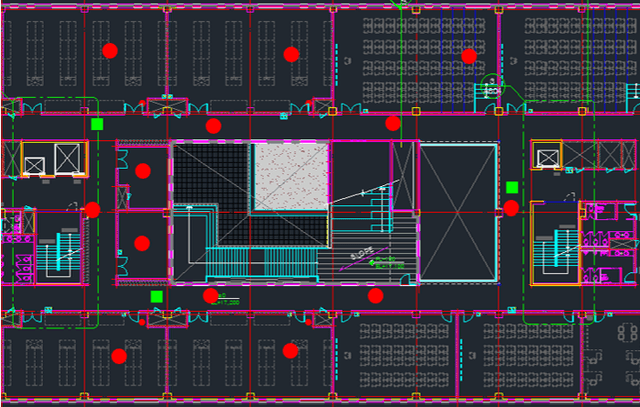
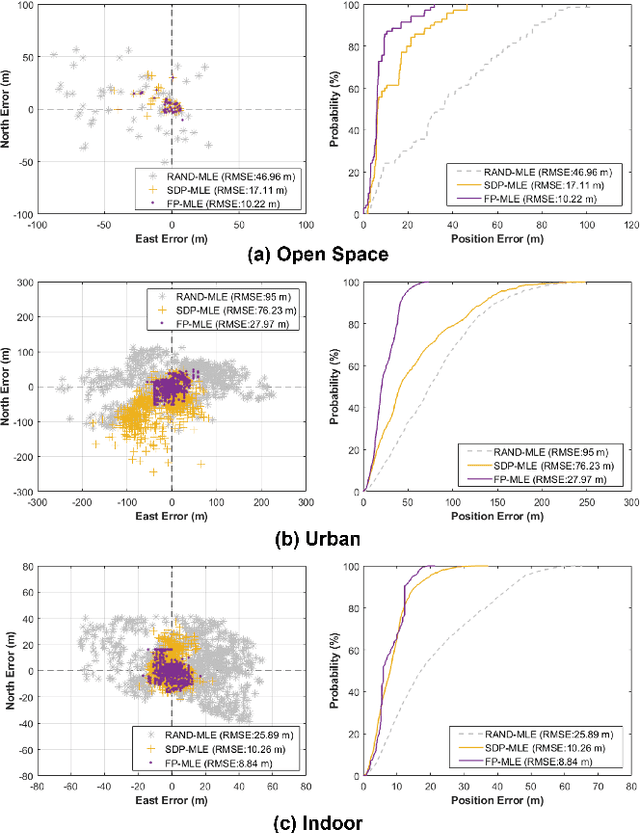
Target localization is essential for emergency dispatching situations. Maximum likelihood estimation (MLE) methods are widely used to estimate the target position based on the received signal strength measurements. However, the performance of MLE solvers is significantly affected by the initialization (i.e., initial guess of the solution or solution search space). To address this, a previous study proposed the semidefinite programming (SDP)-based MLE initialization. However, the performance of the SDP-based initialization technique is largely affected by the shadowing variance and geometric diversity between the target and receivers. In this study, a radio frequency (RF) fingerprinting-based MLE initialization is proposed. Further, a maximum likelihood problem for target localization combining RF fingerprinting is formulated. In the three test environments of open space, urban, and indoor, the proposed RF fingerprinting-aided target localization method showed a performance improvement of up to 63.31% and an average of 39.13%, compared to the MLE algorithm initialized with SDP. Furthermore, unlike the SDP-MLE method, the proposed method was not significantly affected by the poor geometry between the target and receivers in our experiments.
Data Augmentation using Random Image Cropping for High-resolution Virtual Try-On (VITON-CROP)
Nov 16, 2021

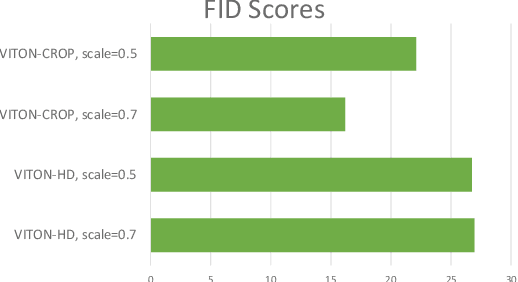
Image-based virtual try-on provides the capacity to transfer a clothing item onto a photo of a given person, which is usually accomplished by warping the item to a given human pose and adjusting the warped item to the person. However, the results of real-world synthetic images (e.g., selfies) from the previous method is not realistic because of the limitations which result in the neck being misrepresented and significant changes to the style of the garment. To address these challenges, we propose a novel method to solve this unique issue, called VITON-CROP. VITON-CROP synthesizes images more robustly when integrated with random crop augmentation compared to the existing state-of-the-art virtual try-on models. In the experiments, we demonstrate that VITON-CROP is superior to VITON-HD both qualitatively and quantitatively.