 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Molecular Generation with Hierarchical Textual Inversion
May 05, 2024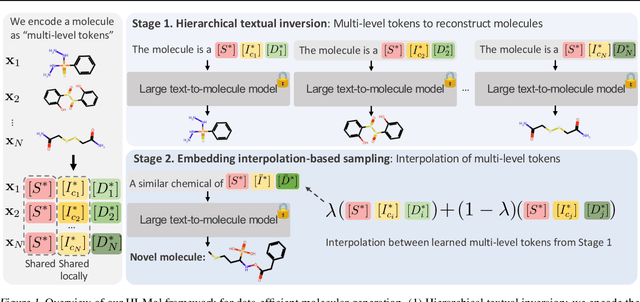



Developing an effective molecular generation framework even with a limited number of molecules is often important for its practical deployment, e.g., drug discovery, since acquiring task-related molecular data requires expensive and time-consuming experimental costs. To tackle this issue, we introduce Hierarchical textual Inversion for Molecular generation (HI-Mol), a novel data-efficient molecular generation method. HI-Mol is inspired by the importance of hierarchical information, e.g., both coarse- and fine-grained features, in understanding the molecule distribution. We propose to use multi-level embeddings to reflect such hierarchical features based on the adoption of the recent textual inversion technique in the visual domain, which achieves data-efficient image generation. Compared to the conventional textual inversion method in the image domain using a single-level token embedding, our multi-level token embeddings allow the model to effectively learn the underlying low-shot molecule distribution. We then generate molecules based on the interpolation of the multi-level token embeddings. Extensive experiments demonstrate the superiority of HI-Mol with notable data-efficiency. For instance, on QM9, HI-Mol outperforms the prior state-of-the-art method with 50x less training data. We also show the effectiveness of molecules generated by HI-Mol in low-shot molecular property prediction.
IR-UWB Radar-Based Contactless Silent Speech Recognition of Vowels, Consonants, Words, and Phrases
Dec 15, 2023



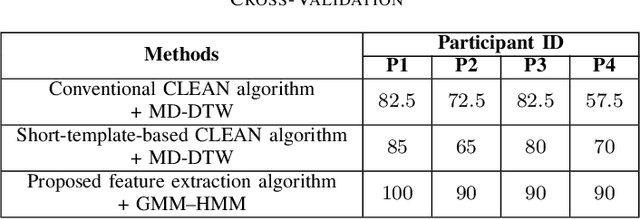
Several sensing techniques have been proposed for silent speech recognition (SSR); however, many of these methods require invasive processes or sensor attachment to the skin using adhesive tape or glue, rendering them unsuitable for frequent use in daily life. By contrast, impulse radio ultra-wideband (IR-UWB) radar can operate without physical contact with users' articulators and related body parts, offering several advantages for SSR. These advantages include high range resolution, high penetrability, low power consumption, robustness to external light or sound interference, and the ability to be embedded in space-constrained handheld devices. This study demonstrated IR-UWB radar-based contactless SSR using four types of speech stimuli (vowels, consonants, words, and phrases). To achieve this, a novel speech feature extraction algorithm specifically designed for IR-UWB radar-based SSR is proposed. Each speech stimulus is recognized by applying a classification algorithm to the extracted speech features. Two different algorithms, multidimensional dynamic time warping (MD-DTW) and deep neural network-hidden Markov model (DNN-HMM), were compared for the classification task. Additionally, a favorable radar antenna position, either in front of the user's lips or below the user's chin, was determined to achieve higher recognition accuracy. Experimental results demonstrated the efficacy of the proposed speech feature extraction algorithm combined with DNN-HMM for classifying vowels, consonants, words, and phrases. Notably, this study represents the first demonstration of phoneme-level SSR using contactless radar.
Camera-Driven Representation Learning for Unsupervised Domain Adaptive Person Re-identification
Aug 23, 2023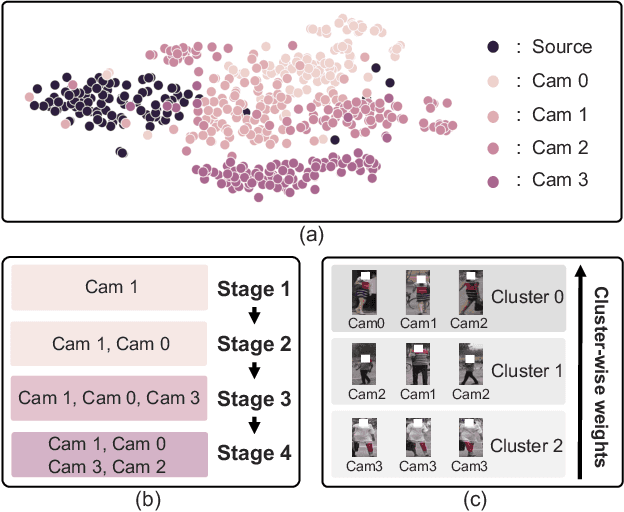

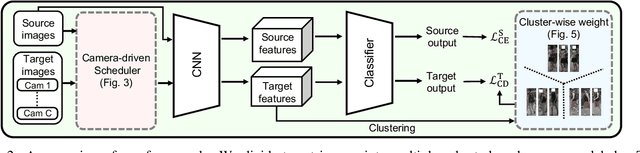

We present a novel unsupervised domain adaption method for person re-identification (reID) that generalizes a model trained on a labeled source domain to an unlabeled target domain. We introduce a camera-driven curriculum learning (CaCL) framework that leverages camera labels of person images to transfer knowledge from source to target domains progressively. To this end, we divide target domain dataset into multiple subsets based on the camera labels, and initially train our model with a single subset (i.e., images captured by a single camera). We then gradually exploit more subsets for training, according to a curriculum sequence obtained with a camera-driven scheduling rule. The scheduler considers maximum mean discrepancies (MMD) between each subset and the source domain dataset, such that the subset closer to the source domain is exploited earlier within the curriculum. For each curriculum sequence, we generate pseudo labels of person images in a target domain to train a reID model in a supervised way. We have observed that the pseudo labels are highly biased toward cameras, suggesting that person images obtained from the same camera are likely to have the same pseudo labels, even for different IDs. To address the camera bias problem, we also introduce a camera-diversity (CD) loss encouraging person images of the same pseudo label, but captured across various cameras, to involve more for discriminative feature learning, providing person representations robust to inter-camera variations. Experimental results on standard benchmarks, including real-to-real and synthetic-to-real scenarios, demonstrate the effectiveness of our framework.
Movement Detection of Tongue and Related Body Parts Using IR-UWB Radar
Sep 05, 2022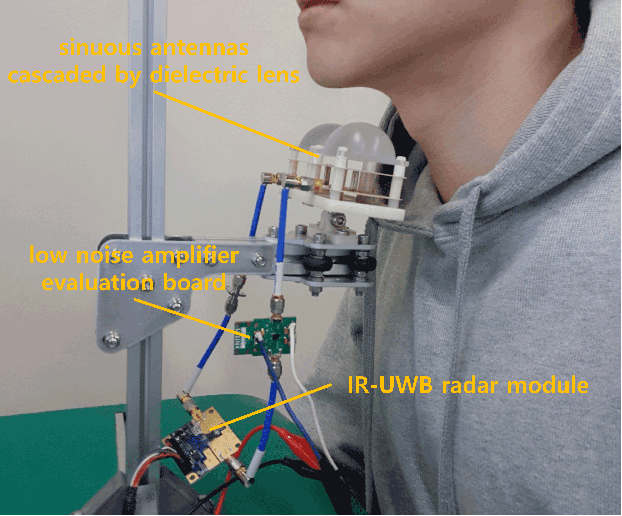

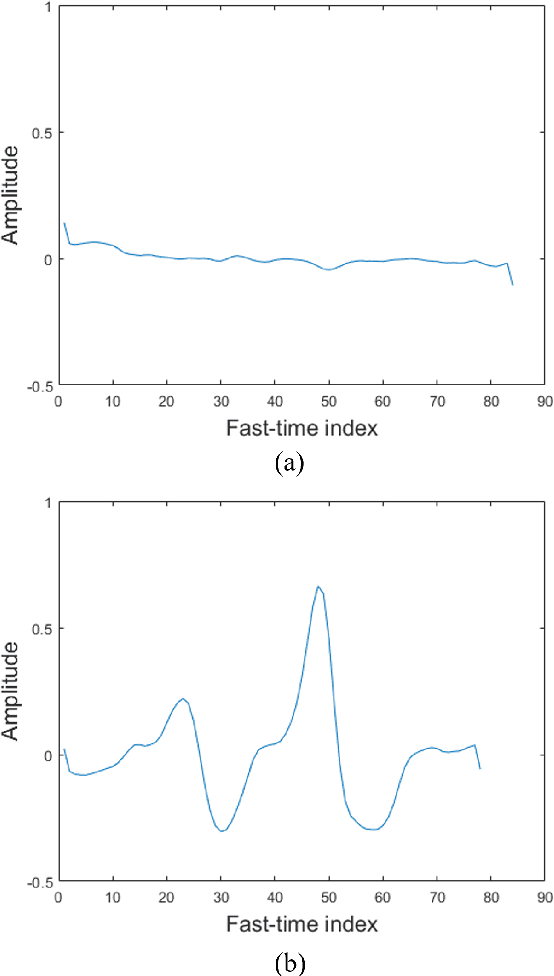
Because an impulse radio ultra-wideband (IR-UWB) radar can detect targets with high accuracy, work through occluding materials, and operate without contact, it is an attractive hardware solution for building silent speech interfaces, which are non-audio-based speech communication devices. As tongue movement is strongly engaged in pronunciation, detecting its movement is crucial for developing silent speech interfaces. In this study, we attempted to classify the motionless and moving states of an invisible tongue and its related body parts using an IR-UWB radar whose antennas were pointed toward the participant's chin. Using the proposed feature extraction algorithm and a Gaussian mixture model - hidden Markov model, we classified two states of the invisible tongue of four individual participants with a minimum accuracy of 90%.
Indoor Navigation Algorithm Based on a Smartphone Inertial Measurement Unit and Map Matching
Sep 24, 2021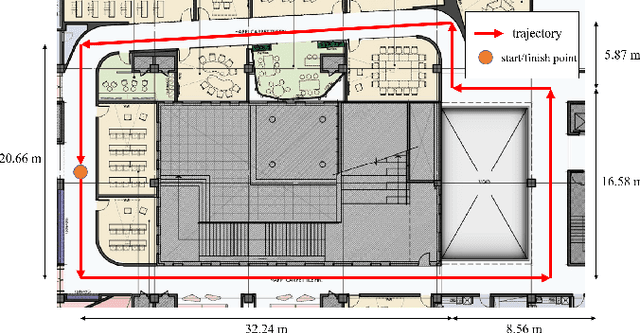
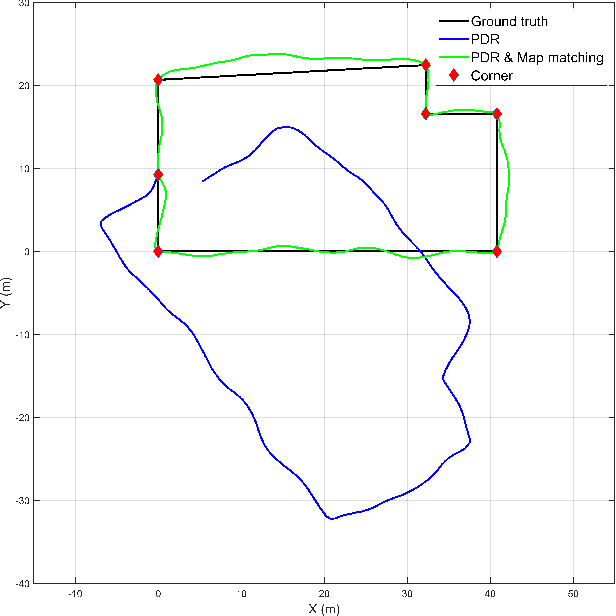
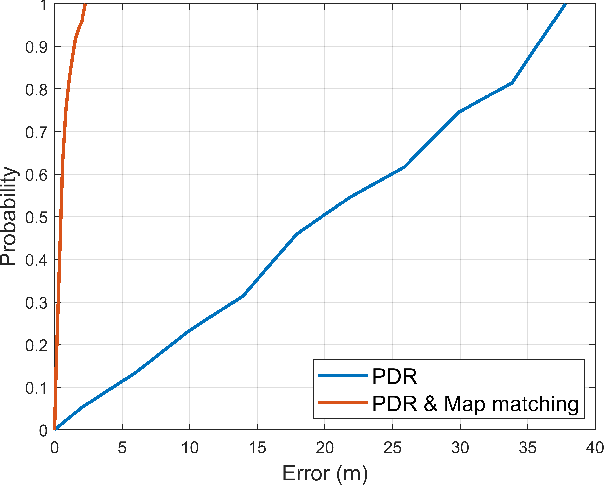

We propose an indoor navigation algorithm based on pedestrian dead reckoning (PDR) using an inertial measurement unit in a smartphone and map matching. The proposed indoor navigation system is user-friendly and convenient because it requires no additional device except a smartphone and works with a pedestrian in a casual posture who is walking with a smartphone in their hand. Because the performance of the PDR decreases over time, we greatly reduced the position error of the trajectory estimated by PDR using a map matching method with a known indoor map. To verify the proposed indoor navigation algorithm, we conducted an experiment in a real indoor environment using a commercial Android smartphone. The performance of our algorithm was demonstrated through the results of the experiment.
Indoor Path Planning for an Unmanned Aerial Vehicle via Curriculum Learning
Aug 23, 2021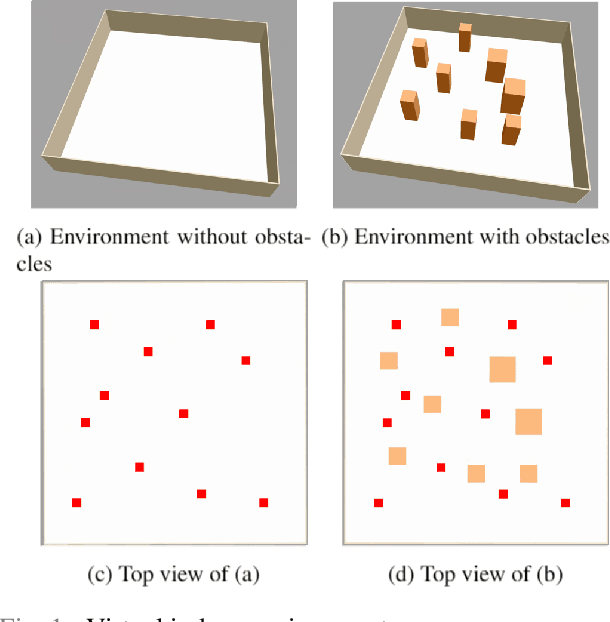
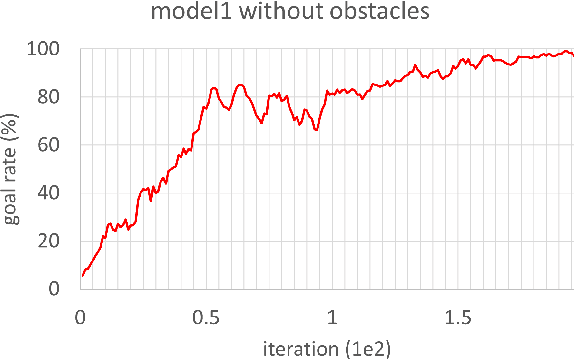
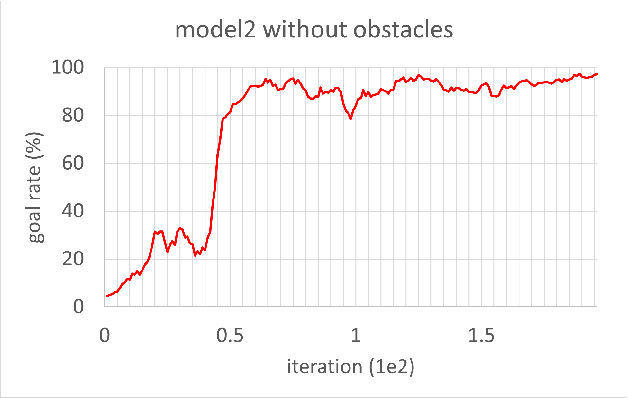
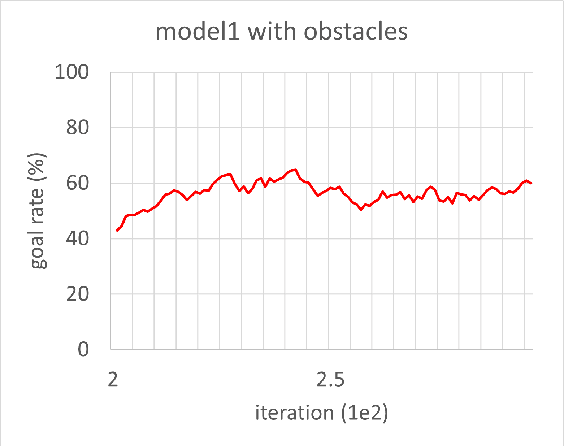
In this study, reinforcement learning was applied to learning two-dimensional path planning including obstacle avoidance by unmanned aerial vehicle (UAV) in an indoor environment. The task assigned to the UAV was to reach the goal position in the shortest amount of time without colliding with any obstacles. Reinforcement learning was performed in a virtual environment created using Gazebo, a virtual environment simulator, to reduce the learning time and cost. Curriculum learning, which consists of two stages was performed for more efficient learning. As a result of learning with two reward models, the maximum goal rates achieved were 71.2% and 88.0%.