 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFontAdapter: Instant Font Adaptation in Visual Text Generation
Jun 06, 2025

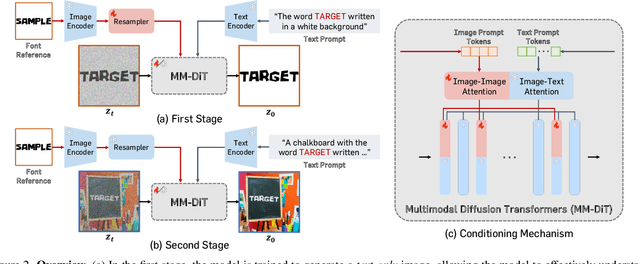
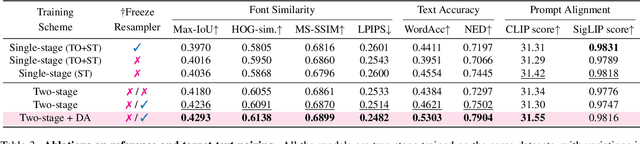
Text-to-image diffusion models have significantly improved the seamless integration of visual text into diverse image contexts. Recent approaches further improve control over font styles through fine-tuning with predefined font dictionaries. However, adapting unseen fonts outside the preset is computationally expensive, often requiring tens of minutes, making real-time customization impractical. In this paper, we present FontAdapter, a framework that enables visual text generation in unseen fonts within seconds, conditioned on a reference glyph image. To this end, we find that direct training on font datasets fails to capture nuanced font attributes, limiting generalization to new glyphs. To overcome this, we propose a two-stage curriculum learning approach: FontAdapter first learns to extract font attributes from isolated glyphs and then integrates these styles into diverse natural backgrounds. To support this two-stage training scheme, we construct synthetic datasets tailored to each stage, leveraging large-scale online fonts effectively. Experiments demonstrate that FontAdapter enables high-quality, robust font customization across unseen fonts without additional fine-tuning during inference. Furthermore, it supports visual text editing, font style blending, and cross-lingual font transfer, positioning FontAdapter as a versatile framework for font customization tasks.
Multi-View Node Pruning for Accurate Graph Representation
Mar 14, 2025Graph pooling, which compresses a whole graph into a smaller coarsened graph, is an essential component of graph representation learning. To efficiently compress a given graph, graph pooling methods often drop their nodes with attention-based scoring with the task loss. However, this often results in simply removing nodes with lower degrees without consideration of their feature-level relevance to the given task. To fix this problem, we propose a Multi-View Pruning(MVP), a graph pruning method based on a multi-view framework and reconstruction loss. Given a graph, MVP first constructs multiple graphs for different views either by utilizing the predefined modalities or by randomly partitioning the input features, to consider the importance of each node in diverse perspectives. Then, it learns the score for each node by considering both the reconstruction and the task loss. MVP can be incorporated with any hierarchical pooling framework to score the nodes. We validate MVP on multiple benchmark datasets by coupling it with two graph pooling methods, and show that it significantly improves the performance of the base graph pooling method, outperforming all baselines. Further analysis shows that both the encoding of multiple views and the consideration of reconstruction loss are the key to the success of MVP, and that it indeed identifies nodes that are less important according to domain knowledge.
Confidence-aware Denoised Fine-tuning of Off-the-shelf Models for Certified Robustness
Nov 13, 2024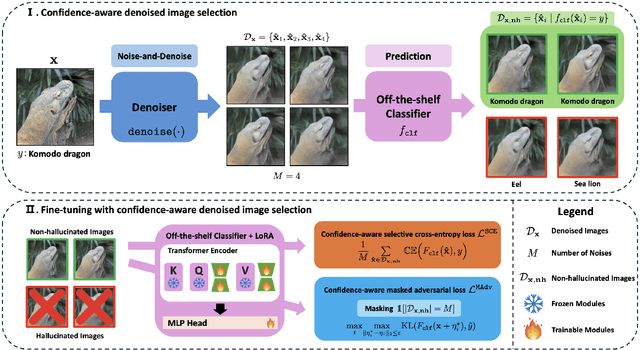
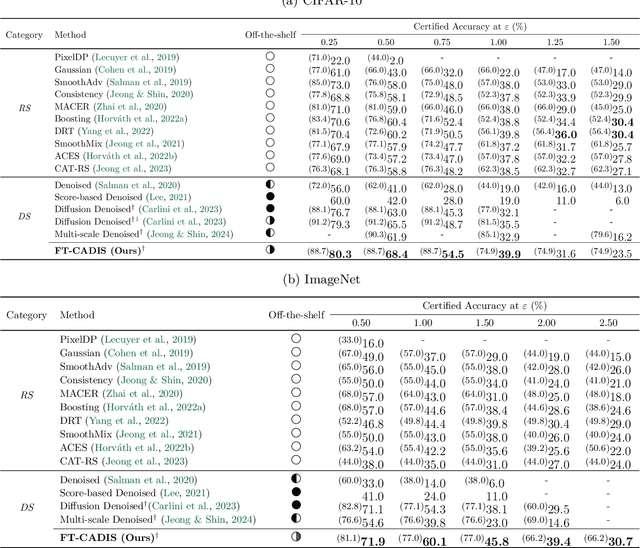
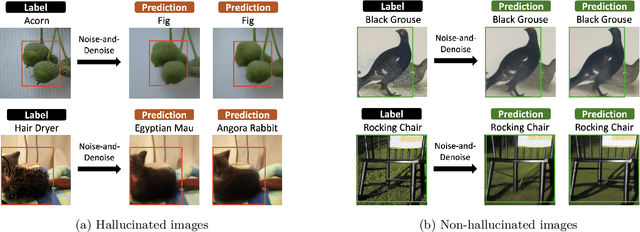

The remarkable advances in deep learning have led to the emergence of many off-the-shelf classifiers, e.g., large pre-trained models. However, since they are typically trained on clean data, they remain vulnerable to adversarial attacks. Despite this vulnerability, their superior performance and transferability make off-the-shelf classifiers still valuable in practice, demanding further work to provide adversarial robustness for them in a post-hoc manner. A recently proposed method, denoised smoothing, leverages a denoiser model in front of the classifier to obtain provable robustness without additional training. However, the denoiser often creates hallucination, i.e., images that have lost the semantics of their originally assigned class, leading to a drop in robustness. Furthermore, its noise-and-denoise procedure introduces a significant distribution shift from the original distribution, causing the denoised smoothing framework to achieve sub-optimal robustness. In this paper, we introduce Fine-Tuning with Confidence-Aware Denoised Image Selection (FT-CADIS), a novel fine-tuning scheme to enhance the certified robustness of off-the-shelf classifiers. FT-CADIS is inspired by the observation that the confidence of off-the-shelf classifiers can effectively identify hallucinated images during denoised smoothing. Based on this, we develop a confidence-aware training objective to handle such hallucinated images and improve the stability of fine-tuning from denoised images. In this way, the classifier can be fine-tuned using only images that are beneficial for adversarial robustness. We also find that such a fine-tuning can be done by updating a small fraction of parameters of the classifier. Extensive experiments demonstrate that FT-CADIS has established the state-of-the-art certified robustness among denoised smoothing methods across all $\ell_2$-adversary radius in various benchmarks.
Addressing Prediction Delays in Time Series Forecasting: A Continuous GRU Approach with Derivative Regularization
Jun 29, 2024Time series forecasting has been an essential field in many different application areas, including economic analysis, meteorology, and so forth. The majority of time series forecasting models are trained using the mean squared error (MSE). However, this training based on MSE causes a limitation known as prediction delay. The prediction delay, which implies the ground-truth precedes the prediction, can cause serious problems in a variety of fields, e.g., finance and weather forecasting -- as a matter of fact, predictions succeeding ground-truth observations are not practically meaningful although their MSEs can be low. This paper proposes a new perspective on traditional time series forecasting tasks and introduces a new solution to mitigate the prediction delay. We introduce a continuous-time gated recurrent unit (GRU) based on the neural ordinary differential equation (NODE) which can supervise explicit time-derivatives. We generalize the GRU architecture in a continuous-time manner and minimize the prediction delay through our time-derivative regularization. Our method outperforms in metrics such as MSE, Dynamic Time Warping (DTW) and Time Distortion Index (TDI). In addition, we demonstrate the low prediction delay of our method in a variety of datasets.
Data-Efficient Molecular Generation with Hierarchical Textual Inversion
May 05, 2024Developing an effective molecular generation framework even with a limited number of molecules is often important for its practical deployment, e.g., drug discovery, since acquiring task-related molecular data requires expensive and time-consuming experimental costs. To tackle this issue, we introduce Hierarchical textual Inversion for Molecular generation (HI-Mol), a novel data-efficient molecular generation method. HI-Mol is inspired by the importance of hierarchical information, e.g., both coarse- and fine-grained features, in understanding the molecule distribution. We propose to use multi-level embeddings to reflect such hierarchical features based on the adoption of the recent textual inversion technique in the visual domain, which achieves data-efficient image generation. Compared to the conventional textual inversion method in the image domain using a single-level token embedding, our multi-level token embeddings allow the model to effectively learn the underlying low-shot molecule distribution. We then generate molecules based on the interpolation of the multi-level token embeddings. Extensive experiments demonstrate the superiority of HI-Mol with notable data-efficiency. For instance, on QM9, HI-Mol outperforms the prior state-of-the-art method with 50x less training data. We also show the effectiveness of molecules generated by HI-Mol in low-shot molecular property prediction.
Evaluating the Efficacy of Interactive Language Therapy Based on LLM for High-Functioning Autistic Adolescent Psychological Counseling
Nov 12, 2023
This study investigates the efficacy of Large Language Models (LLMs) in interactive language therapy for high-functioning autistic adolescents. With the rapid advancement of artificial intelligence, particularly in natural language processing, LLMs present a novel opportunity to augment traditional psychological counseling methods. This research primarily focuses on evaluating the LLM's ability to engage in empathetic, adaptable, and contextually appropriate interactions within a therapeutic setting. A comprehensive evaluation was conducted by a panel of clinical psychologists and psychiatrists using a specially developed scorecard. The assessment covered various aspects of the LLM's performance, including empathy, communication skills, adaptability, engagement, and the ability to establish a therapeutic alliance. The study avoided direct testing with patients, prioritizing privacy and ethical considerations, and instead relied on simulated scenarios to gauge the LLM's effectiveness. The results indicate that LLMs hold significant promise as supportive tools in therapy, demonstrating strengths in empathetic engagement and adaptability in conversation. However, challenges in achieving the depth of personalization and emotional understanding characteristic of human therapists were noted. The study also highlights the importance of ethical considerations in the application of AI in therapeutic contexts. This research provides valuable insights into the potential and limitations of using LLMs in psychological counseling for autistic adolescents. It lays the groundwork for future explorations into AI's role in mental health care, emphasizing the need for ongoing development to enhance the capabilities of these models in therapeutic settings.
Long-term Time Series Forecasting based on Decomposition and Neural Ordinary Differential Equations
Nov 10, 2023



Long-term time series forecasting (LTSF) is a challenging task that has been investigated in various domains such as finance investment, health care, traffic, and weather forecasting. In recent years, Linear-based LTSF models showed better performance, pointing out the problem of Transformer-based approaches causing temporal information loss. However, Linear-based approach has also limitations that the model is too simple to comprehensively exploit the characteristics of the dataset. To solve these limitations, we propose LTSF-DNODE, which applies a model based on linear ordinary differential equations (ODEs) and a time series decomposition method according to data statistical characteristics. We show that LTSF-DNODE outperforms the baselines on various real-world datasets. In addition, for each dataset, we explore the impacts of regularization in the neural ordinary differential equation (NODE) framework.
Confidence-aware Training of Smoothed Classifiers for Certified Robustness
Dec 20, 2022Any classifier can be "smoothed out" under Gaussian noise to build a new classifier that is provably robust to $\ell_2$-adversarial perturbations, viz., by averaging its predictions over the noise via randomized smoothing. Under the smoothed classifiers, the fundamental trade-off between accuracy and (adversarial) robustness has been well evidenced in the literature: i.e., increasing the robustness of a classifier for an input can be at the expense of decreased accuracy for some other inputs. In this paper, we propose a simple training method leveraging this trade-off to obtain robust smoothed classifiers, in particular, through a sample-wise control of robustness over the training samples. We make this control feasible by using "accuracy under Gaussian noise" as an easy-to-compute proxy of adversarial robustness for an input. Specifically, we differentiate the training objective depending on this proxy to filter out samples that are unlikely to benefit from the worst-case (adversarial) objective. Our experiments show that the proposed method, despite its simplicity, consistently exhibits improved certified robustness upon state-of-the-art training methods. Somewhat surprisingly, we find these improvements persist even for other notions of robustness, e.g., to various types of common corruptions.