 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARS: Modular Agent with Reflective Search for Automated AI Research
Feb 02, 2026Automating AI research differs from general software engineering due to computationally expensive evaluation (e.g., model training) and opaque performance attribution. Current LLM-based agents struggle here, often generating monolithic scripts that ignore execution costs and causal factors. We introduce MARS (Modular Agent with Reflective Search), a framework optimized for autonomous AI research. MARS relies on three pillars: (1) Budget-Aware Planning via cost-constrained Monte Carlo Tree Search (MCTS) to explicitly balance performance with execution expense; (2) Modular Construction, employing a "Design-Decompose-Implement" pipeline to manage complex research repositories; and (3) Comparative Reflective Memory, which addresses credit assignment by analyzing solution differences to distill high-signal insights. MARS achieves state-of-the-art performance among open-source frameworks on MLE-Bench under comparable settings, maintaining competitiveness with the global leaderboard's top methods. Furthermore, the system exhibits qualitative "Aha!" moments, where 63% of all utilized lessons originate from cross-branch transfer, demonstrating that the agent effectively generalizes insights across search paths.
FontAdapter: Instant Font Adaptation in Visual Text Generation
Jun 06, 2025

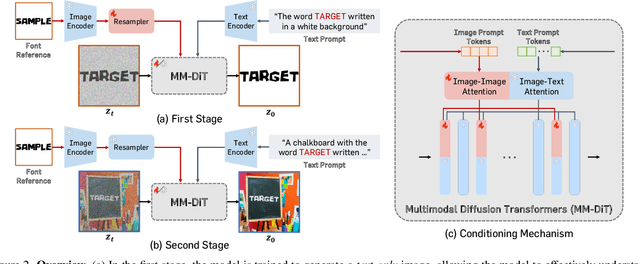
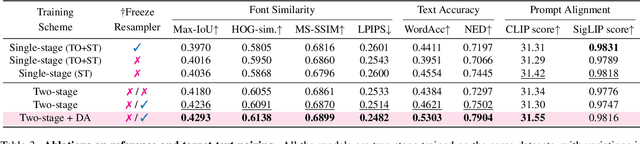
Text-to-image diffusion models have significantly improved the seamless integration of visual text into diverse image contexts. Recent approaches further improve control over font styles through fine-tuning with predefined font dictionaries. However, adapting unseen fonts outside the preset is computationally expensive, often requiring tens of minutes, making real-time customization impractical. In this paper, we present FontAdapter, a framework that enables visual text generation in unseen fonts within seconds, conditioned on a reference glyph image. To this end, we find that direct training on font datasets fails to capture nuanced font attributes, limiting generalization to new glyphs. To overcome this, we propose a two-stage curriculum learning approach: FontAdapter first learns to extract font attributes from isolated glyphs and then integrates these styles into diverse natural backgrounds. To support this two-stage training scheme, we construct synthetic datasets tailored to each stage, leveraging large-scale online fonts effectively. Experiments demonstrate that FontAdapter enables high-quality, robust font customization across unseen fonts without additional fine-tuning during inference. Furthermore, it supports visual text editing, font style blending, and cross-lingual font transfer, positioning FontAdapter as a versatile framework for font customization tasks.
Tabular Transfer Learning via Prompting LLMs
Aug 09, 2024Learning with a limited number of labeled data is a central problem in real-world applications of machine learning, as it is often expensive to obtain annotations. To deal with the scarcity of labeled data, transfer learning is a conventional approach; it suggests to learn a transferable knowledge by training a neural network from multiple other sources. In this paper, we investigate transfer learning of tabular tasks, which has been less studied and successful in the literature, compared to other domains, e.g., vision and language. This is because tables are inherently heterogeneous, i.e., they contain different columns and feature spaces, making transfer learning difficult. On the other hand, recent advances in natural language processing suggest that the label scarcity issue can be mitigated by utilizing in-context learning capability of large language models (LLMs). Inspired by this and the fact that LLMs can also process tables within a unified language space, we ask whether LLMs can be effective for tabular transfer learning, in particular, under the scenarios where the source and target datasets are of different format. As a positive answer, we propose a novel tabular transfer learning framework, coined Prompt to Transfer (P2T), that utilizes unlabeled (or heterogeneous) source data with LLMs. Specifically, P2T identifies a column feature in a source dataset that is strongly correlated with a target task feature to create examples relevant to the target task, thus creating pseudo-demonstrations for prompts. Experimental results demonstrate that P2T outperforms previous methods on various tabular learning benchmarks, showing good promise for the important, yet underexplored tabular transfer learning problem. Code is available at https://github.com/jaehyun513/P2T.
Optimized Feature Generation for Tabular Data via LLMs with Decision Tree Reasoning
Jun 12, 2024Learning effective representations from raw data is crucial for the success of deep learning methods. However, in the tabular domain, practitioners often prefer augmenting raw column features over using learned representations, as conventional tree-based algorithms frequently outperform competing approaches. As a result, feature engineering methods that automatically generate candidate features have been widely used. While these approaches are often effective, there remains ambiguity in defining the space over which to search for candidate features. Moreover, they often rely solely on validation scores to select good features, neglecting valuable feedback from past experiments that could inform the planning of future experiments. To address the shortcomings, we propose a new tabular learning framework based on large language models (LLMs), coined Optimizing Column feature generator with decision Tree reasoning (OCTree). Our key idea is to leverage LLMs' reasoning capabilities to find good feature generation rules without manually specifying the search space and provide language-based reasoning information highlighting past experiments as feedback for iterative rule improvements. Here, we choose a decision tree as reasoning as it can be interpreted in natural language, effectively conveying knowledge of past experiments (i.e., the prediction models trained with the generated features) to the LLM. Our empirical results demonstrate that this simple framework consistently enhances the performance of various prediction models across diverse tabular benchmarks, outperforming competing automatic feature engineering methods.
Data-Efficient Molecular Generation with Hierarchical Textual Inversion
May 05, 2024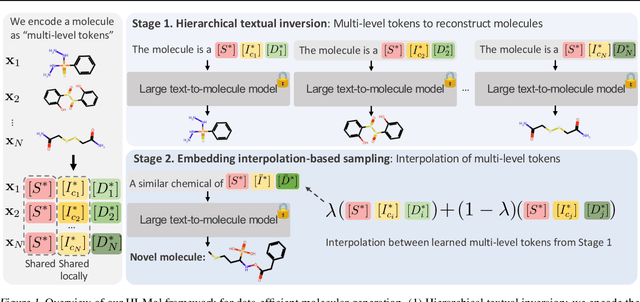



Developing an effective molecular generation framework even with a limited number of molecules is often important for its practical deployment, e.g., drug discovery, since acquiring task-related molecular data requires expensive and time-consuming experimental costs. To tackle this issue, we introduce Hierarchical textual Inversion for Molecular generation (HI-Mol), a novel data-efficient molecular generation method. HI-Mol is inspired by the importance of hierarchical information, e.g., both coarse- and fine-grained features, in understanding the molecule distribution. We propose to use multi-level embeddings to reflect such hierarchical features based on the adoption of the recent textual inversion technique in the visual domain, which achieves data-efficient image generation. Compared to the conventional textual inversion method in the image domain using a single-level token embedding, our multi-level token embeddings allow the model to effectively learn the underlying low-shot molecule distribution. We then generate molecules based on the interpolation of the multi-level token embeddings. Extensive experiments demonstrate the superiority of HI-Mol with notable data-efficiency. For instance, on QM9, HI-Mol outperforms the prior state-of-the-art method with 50x less training data. We also show the effectiveness of molecules generated by HI-Mol in low-shot molecular property prediction.
SuRe: Summarizing Retrievals using Answer Candidates for Open-domain QA of LLMs
Apr 17, 2024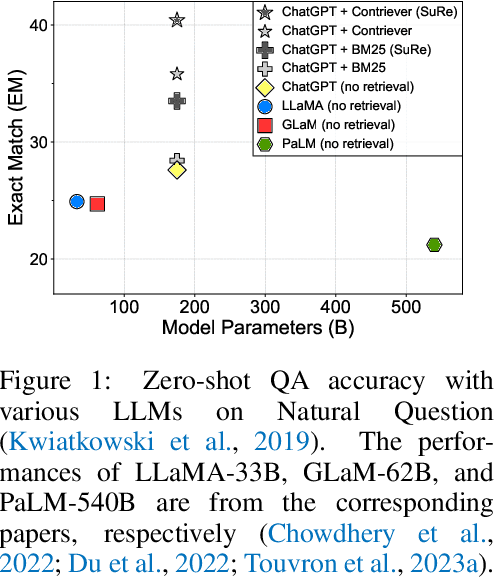
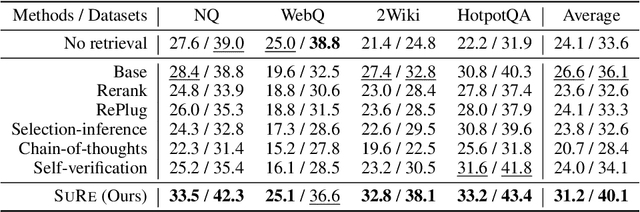

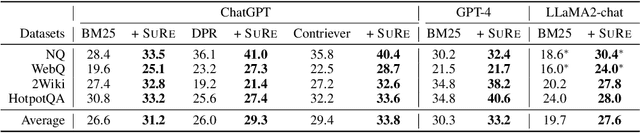
Large language models (LLMs) have made significant advancements in various natural language processing tasks, including question answering (QA) tasks. While incorporating new information with the retrieval of relevant passages is a promising way to improve QA with LLMs, the existing methods often require additional fine-tuning which becomes infeasible with recent LLMs. Augmenting retrieved passages via prompting has the potential to address this limitation, but this direction has been limitedly explored. To this end, we design a simple yet effective framework to enhance open-domain QA (ODQA) with LLMs, based on the summarized retrieval (SuRe). SuRe helps LLMs predict more accurate answers for a given question, which are well-supported by the summarized retrieval that could be viewed as an explicit rationale extracted from the retrieved passages. Specifically, SuRe first constructs summaries of the retrieved passages for each of the multiple answer candidates. Then, SuRe confirms the most plausible answer from the candidate set by evaluating the validity and ranking of the generated summaries. Experimental results on diverse ODQA benchmarks demonstrate the superiority of SuRe, with improvements of up to 4.6% in exact match (EM) and 4.0% in F1 score over standard prompting approaches. SuRe also can be integrated with a broad range of retrieval methods and LLMs. Finally, the generated summaries from SuRe show additional advantages to measure the importance of retrieved passages and serve as more preferred rationales by models and humans.
STUNT: Few-shot Tabular Learning with Self-generated Tasks from Unlabeled Tables
Mar 02, 2023Learning with few labeled tabular samples is often an essential requirement for industrial machine learning applications as varieties of tabular data suffer from high annotation costs or have difficulties in collecting new samples for novel tasks. Despite the utter importance, such a problem is quite under-explored in the field of tabular learning, and existing few-shot learning schemes from other domains are not straightforward to apply, mainly due to the heterogeneous characteristics of tabular data. In this paper, we propose a simple yet effective framework for few-shot semi-supervised tabular learning, coined Self-generated Tasks from UNlabeled Tables (STUNT). Our key idea is to self-generate diverse few-shot tasks by treating randomly chosen columns as a target label. We then employ a meta-learning scheme to learn generalizable knowledge with the constructed tasks. Moreover, we introduce an unsupervised validation scheme for hyperparameter search (and early stopping) by generating a pseudo-validation set using STUNT from unlabeled data. Our experimental results demonstrate that our simple framework brings significant performance gain under various tabular few-shot learning benchmarks, compared to prior semi- and self-supervised baselines. Code is available at https://github.com/jaehyun513/STUNT.