 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExComm: Exploration-Stage Communication for Error-Resilient Agentic Test-Time Scaling
May 21, 2026A common failure mode in long-horizon agentic test-time scaling is error propagation, where factual errors or invalid deductions introduced at intermediate steps persist in the agent's belief state and contaminate later reasoning. Existing test-time scaling methods provide limited control over this process, as they often rely on agents to detect their own mistakes, select among flawed trajectories, or refine solutions only after errors have already shaped the reasoning path. We propose ExComm, a communication protocol for exploration-stage agentic test-time scaling. ExComm is motivated by the empirical observation that the majority of intermediate errors in parallel agentic reasoning produce detectable cross-agent factual conflicts. Leveraging the iterative structure of agentic workflows, ExComm periodically audits agent belief states to detect such conflicts, resolves them through a dedicated tool-based verification loop, and returns concise, targeted feedback to the involved agents. Corrections are incorporated through soft belief updates, which append verified feedback rather than overwriting existing beliefs. Furthermore, to prevent collapsing trajectory diversity due to communication, ExComm further introduces a trajectory diversification module that redirects redundant trajectories toward orthogonal strategies. Experiments on AIME 2024, AIME 2025, and GAIA with Gemini-2.5-Flash-Lite and Qwen3.5-4B show that ExComm consistently outperforms strong test-time scaling baselines, achieving average performance gains of 5.7% and 5.0% over the best-performing baselines, respectively. Further analyses demonstrate improved error recovery, favorable scaling behavior, stronger diversity than adapted communication baselines, and the best performance-cost trade-off among the evaluated methods.
IdleSpec: Exploiting Idle Time via Speculative Planning for LLM Agents
May 21, 2026Large language model (LLM)-based agents solve complex tasks by leveraging multi-step reasoning with iterative tool calls and environment interactions, which incur idle time while waiting for observations. Despite the prevalence of idle time in most agentic scenarios, existing works treat it as an unavoidable overhead or propose restricted solutions that overlook varying computational budgets across different tool calls and future observation uncertainty, thereby leading to suboptimal utilization of idle time. In this paper, we introduce IdleSpec, a scalable and generic inference approach that leverages idle-time computation to improve agent performance while minimizing latency overhead. Specifically, IdleSpec iteratively generates plan candidates during idle periods and, once observations become available, aggregates them to guide the next reasoning step. For effective plan generation under observation uncertainty, IdleSpec samples between complementary drafting strategies (i.e., progressive and recovery) from a learned distribution that is updated via posterior feedback. Our experiments demonstrate that IdleSpec significantly improves agent performance in various agentic scenarios by effectively utilizing idle time. In particular, on the GAIA and FRAMES, IdleSpec achieves 55.6% average accuracy with Gemini-2.5-Flash, surpassing the vanilla baseline without idle-time usage by 5.1%. Furthermore, for MLE-Bench, which involves substantial delay from code executions, IdleSpec achieves performance gains of up to 9.1% on the Any Medal rate, highlighting its generalizability to long-horizon tasks.
RoboAlign: Learning Test-Time Reasoning for Language-Action Alignment in Vision-Language-Action Models
Mar 22, 2026Improving embodied reasoning in multimodal-large-language models (MLLMs) is essential for building vision-language-action models (VLAs) on top of them to readily translate multimodal understanding into low-level actions. Accordingly, recent work has explored enhancing embodied reasoning in MLLMs through supervision of vision-question-answering type. However, these approaches have been reported to result in unstable VLA performance, often yielding only marginal or even negative gains. In this paper, we propose a more systematic MLLM training framework RoboAlign that reliably improves VLA performance. Our key idea is to sample action tokens via zero-shot natural language reasoning and refines this reasoning using reinforcement learning (RL) to improve action accuracy. As a result, RoboAlign bridges the modality gap between language and low-level actions in MLLMs, and facilitate knowledge transfer from MLLM to VLA. To validate the effectiveness of RoboAlign, we train VLAs by adding a diffusion-based action head on top of an MLLM backbone and evaluate them on major robotics benchmarks. Remarkably, by performing RL-based alignment after SFT using less than 1\% of the data, RoboAlign achieves performance improvements of 17.5\%, 18.9\%, and 106.6\% over SFT baselines on LIBERO, CALVIN, and real-world environments, respectively.
Accelerated Test-Time Scaling with Model-Free Speculative Sampling
Jun 05, 2025Language models have demonstrated remarkable capabilities in reasoning tasks through test-time scaling techniques like best-of-N sampling and tree search. However, these approaches often demand substantial computational resources, creating a critical trade-off between performance and efficiency. We introduce STAND (STochastic Adaptive N-gram Drafting), a novel model-free speculative decoding approach that leverages the inherent redundancy in reasoning trajectories to achieve significant acceleration without compromising accuracy. Our analysis reveals that reasoning paths frequently reuse similar reasoning patterns, enabling efficient model-free token prediction without requiring separate draft models. By introducing stochastic drafting and preserving probabilistic information through a memory-efficient logit-based N-gram module, combined with optimized Gumbel-Top-K sampling and data-driven tree construction, STAND significantly improves token acceptance rates. Extensive evaluations across multiple models and reasoning tasks (AIME-2024, GPQA-Diamond, and LiveCodeBench) demonstrate that STAND reduces inference latency by 60-65% compared to standard autoregressive decoding while maintaining accuracy. Furthermore, STAND outperforms state-of-the-art speculative decoding methods by 14-28% in throughput and shows strong performance even in single-trajectory scenarios, reducing inference latency by 48-58%. As a model-free approach, STAND can be applied to any existing language model without additional training, being a powerful plug-and-play solution for accelerating language model reasoning.
Sparsified State-Space Models are Efficient Highway Networks
May 27, 2025State-space models (SSMs) offer a promising architecture for sequence modeling, providing an alternative to Transformers by replacing expensive self-attention with linear recurrences. In this paper, we propose a simple yet effective trick to enhance SSMs within given computational budgets by sparsifying them. Our intuition is that tokens in SSMs are highly redundant due to gradual recurrent updates, and dense recurrence operations block the delivery of past information. In particular, we observe that upper layers of SSMs tend to be more redundant as they encode global information, while lower layers encode local information. Motivated by this, we introduce Simba, a hierarchical sparsification method for SSMs based on token pruning. Simba sparsifies upper layers more than lower layers, encouraging the upper layers to behave like highways. To achieve this, we propose a novel token pruning criterion for SSMs, measuring the global impact of tokens on the final output by accumulating local recurrences. We demonstrate that Simba outperforms the baseline model, Mamba, with the same FLOPS in various natural language tasks. Moreover, we illustrate the effect of highways, showing that Simba not only enhances efficiency but also improves the information flow across long sequences. Code is available at https://github.com/woominsong/Simba.
Tabular Transfer Learning via Prompting LLMs
Aug 09, 2024Learning with a limited number of labeled data is a central problem in real-world applications of machine learning, as it is often expensive to obtain annotations. To deal with the scarcity of labeled data, transfer learning is a conventional approach; it suggests to learn a transferable knowledge by training a neural network from multiple other sources. In this paper, we investigate transfer learning of tabular tasks, which has been less studied and successful in the literature, compared to other domains, e.g., vision and language. This is because tables are inherently heterogeneous, i.e., they contain different columns and feature spaces, making transfer learning difficult. On the other hand, recent advances in natural language processing suggest that the label scarcity issue can be mitigated by utilizing in-context learning capability of large language models (LLMs). Inspired by this and the fact that LLMs can also process tables within a unified language space, we ask whether LLMs can be effective for tabular transfer learning, in particular, under the scenarios where the source and target datasets are of different format. As a positive answer, we propose a novel tabular transfer learning framework, coined Prompt to Transfer (P2T), that utilizes unlabeled (or heterogeneous) source data with LLMs. Specifically, P2T identifies a column feature in a source dataset that is strongly correlated with a target task feature to create examples relevant to the target task, thus creating pseudo-demonstrations for prompts. Experimental results demonstrate that P2T outperforms previous methods on various tabular learning benchmarks, showing good promise for the important, yet underexplored tabular transfer learning problem. Code is available at https://github.com/jaehyun513/P2T.
Hierarchical Context Merging: Better Long Context Understanding for Pre-trained LLMs
Apr 16, 2024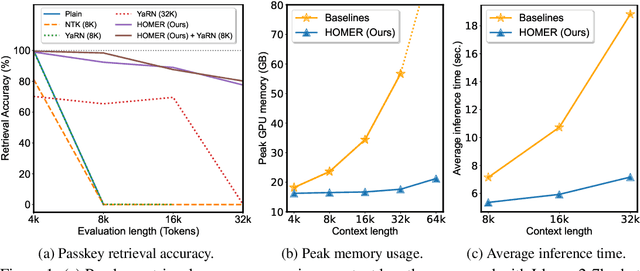
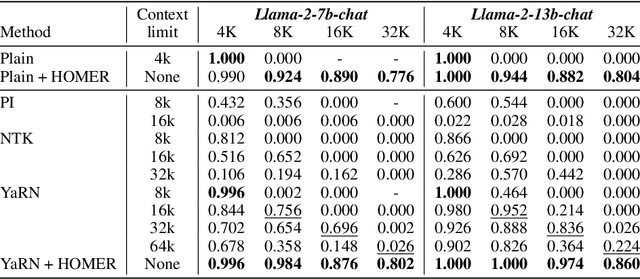
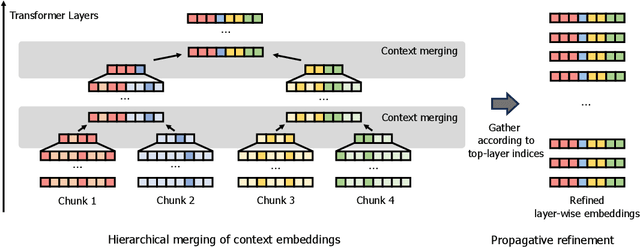
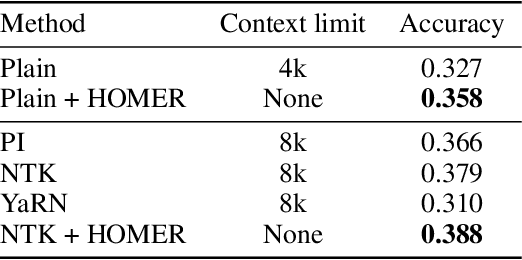
Large language models (LLMs) have shown remarkable performance in various natural language processing tasks. However, a primary constraint they face is the context limit, i.e., the maximum number of tokens they can process. Previous works have explored architectural changes and modifications in positional encoding to relax the constraint, but they often require expensive training or do not address the computational demands of self-attention. In this paper, we present Hierarchical cOntext MERging (HOMER), a new training-free scheme designed to overcome the limitations. HOMER uses a divide-and-conquer algorithm, dividing long inputs into manageable chunks. Each chunk is then processed collectively, employing a hierarchical strategy that merges adjacent chunks at progressive transformer layers. A token reduction technique precedes each merging, ensuring memory usage efficiency. We also propose an optimized computational order reducing the memory requirement to logarithmically scale with respect to input length, making it especially favorable for environments with tight memory restrictions. Our experiments demonstrate the proposed method's superior performance and memory efficiency, enabling the broader use of LLMs in contexts requiring extended context. Code is available at https://github.com/alinlab/HOMER.