 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoop Corrections to the Training and Generalization Errors of Random Feature Models
Apr 14, 2026We investigate random feature models in which neural networks sampled from a prescribed initialization ensemble are frozen and used as random features, with only the readout weights optimized. Adopting a statistical-physics viewpoint, we study the training, test, and generalization errors beyond the mean-kernel approximation. Since the predictor is a nonlinear functional of the induced random kernel, the ensemble-averaged errors depend not only on the mean kernel but also on higher-order fluctuation statistics. Within an effective field-theoretic framework, these finite-width contributions naturally appear as loop corrections. We derive the loop corrections to the training, test, and generalization errors, obtain their scaling laws, and support the theory with experimental verification.
RoboAlign: Learning Test-Time Reasoning for Language-Action Alignment in Vision-Language-Action Models
Mar 22, 2026Improving embodied reasoning in multimodal-large-language models (MLLMs) is essential for building vision-language-action models (VLAs) on top of them to readily translate multimodal understanding into low-level actions. Accordingly, recent work has explored enhancing embodied reasoning in MLLMs through supervision of vision-question-answering type. However, these approaches have been reported to result in unstable VLA performance, often yielding only marginal or even negative gains. In this paper, we propose a more systematic MLLM training framework RoboAlign that reliably improves VLA performance. Our key idea is to sample action tokens via zero-shot natural language reasoning and refines this reasoning using reinforcement learning (RL) to improve action accuracy. As a result, RoboAlign bridges the modality gap between language and low-level actions in MLLMs, and facilitate knowledge transfer from MLLM to VLA. To validate the effectiveness of RoboAlign, we train VLAs by adding a diffusion-based action head on top of an MLLM backbone and evaluate them on major robotics benchmarks. Remarkably, by performing RL-based alignment after SFT using less than 1\% of the data, RoboAlign achieves performance improvements of 17.5\%, 18.9\%, and 106.6\% over SFT baselines on LIBERO, CALVIN, and real-world environments, respectively.
Contrastive Representation Regularization for Vision-Language-Action Models
Oct 02, 2025Vision-Language-Action (VLA) models have shown its capabilities in robot manipulation by leveraging rich representations from pre-trained Vision-Language Models (VLMs). However, their representations arguably remain suboptimal, lacking sensitivity to robotic signals such as control actions and proprioceptive states. To address the issue, we introduce Robot State-aware Contrastive Loss (RS-CL), a simple and effective representation regularization for VLA models, designed to bridge the gap between VLM representations and robotic signals. In particular, RS-CL aligns the representations more closely with the robot's proprioceptive states, by using relative distances between the states as soft supervision. Complementing the original action prediction objective, RS-CL effectively enhances control-relevant representation learning, while being lightweight and fully compatible with standard VLA training pipeline. Our empirical results demonstrate that RS-CL substantially improves the manipulation performance of state-of-the-art VLA models; it pushes the prior art from 30.8% to 41.5% on pick-and-place tasks in RoboCasa-Kitchen, through more accurate positioning during grasping and placing, and boosts success rates from 45.0% to 58.3% on challenging real-robot manipulation tasks.
HAMLET: Switch your Vision-Language-Action Model into a History-Aware Policy
Oct 02, 2025Inherently, robotic manipulation tasks are history-dependent: leveraging past context could be beneficial. However, most existing Vision-Language-Action models (VLAs) have been designed without considering this aspect, i.e., they rely solely on the current observation, ignoring preceding context. In this paper, we propose HAMLET, a scalable framework to adapt VLAs to attend to the historical context during action prediction. Specifically, we introduce moment tokens that compactly encode perceptual information at each timestep. Their representations are initialized with time-contrastive learning, allowing them to better capture temporally distinctive aspects. Next, we employ a lightweight memory module that integrates the moment tokens across past timesteps into memory features, which are then leveraged for action prediction. Through empirical evaluation, we show that HAMLET successfully transforms a state-of-the-art VLA into a history-aware policy, especially demonstrating significant improvements on long-horizon tasks that require historical context. In particular, on top of GR00T N1.5, HAMLET achieves an average success rate of 76.4% on history-dependent real-world tasks, surpassing the baseline performance by 47.2%. Furthermore, HAMLET pushes prior art performance from 64.1% to 66.4% on RoboCasa Kitchen (100-demo setup) and from 95.6% to 97.7% on LIBERO, highlighting its effectiveness even under generic robot-manipulation benchmarks.
Analysis of Fourier Neural Operators via Effective Field Theory
Jul 29, 2025Fourier Neural Operators (FNOs) have emerged as leading surrogates for high-dimensional partial-differential equations, yet their stability, generalization and frequency behavior lack a principled explanation. We present the first systematic effective-field-theory analysis of FNOs in an infinite-dimensional function space, deriving closed recursion relations for the layer kernel and four-point vertex and then examining three practically important settings-analytic activations, scale-invariant cases and architectures with residual connections. The theory shows that nonlinear activations inevitably couple frequency inputs to high-frequency modes that are otherwise discarded by spectral truncation, and experiments confirm this frequency transfer. For wide networks we obtain explicit criticality conditions on the weight-initialization ensemble that keep small input perturbations to have uniform scale across depth, and empirical tests validate these predictions. Taken together, our results quantify how nonlinearity enables neural operators to capture non-trivial features, supply criteria for hyper-parameter selection via criticality analysis, and explain why scale-invariant activations and residual connections enhance feature learning in FNOs.
Fourier Neural Operators for Non-Markovian Processes:Approximation Theorems and Experiments
Jul 23, 2025This paper introduces an operator-based neural network, the mirror-padded Fourier neural operator (MFNO), designed to learn the dynamics of stochastic systems. MFNO extends the standard Fourier neural operator (FNO) by incorporating mirror padding, enabling it to handle non-periodic inputs. We rigorously prove that MFNOs can approximate solutions of path-dependent stochastic differential equations and Lipschitz transformations of fractional Brownian motions to an arbitrary degree of accuracy. Our theoretical analysis builds on Wong--Zakai type theorems and various approximation techniques. Empirically, the MFNO exhibits strong resolution generalization--a property rarely seen in standard architectures such as LSTMs, TCNs, and DeepONet. Furthermore, our model achieves performance that is comparable or superior to these baselines while offering significantly faster sample path generation than classical numerical schemes.
Mixed-Session Conversation with Egocentric Memory
Oct 03, 2024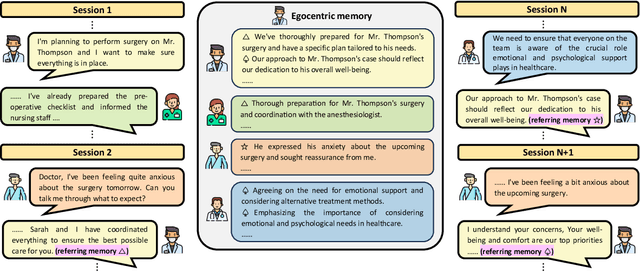


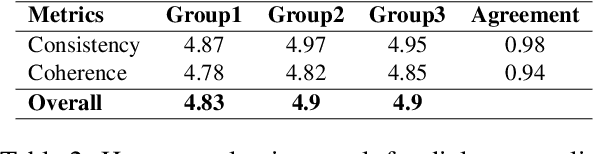
Recently introduced dialogue systems have demonstrated high usability. However, they still fall short of reflecting real-world conversation scenarios. Current dialogue systems exhibit an inability to replicate the dynamic, continuous, long-term interactions involving multiple partners. This shortfall arises because there have been limited efforts to account for both aspects of real-world dialogues: deeply layered interactions over the long-term dialogue and widely expanded conversation networks involving multiple participants. As the effort to incorporate these aspects combined, we introduce Mixed-Session Conversation, a dialogue system designed to construct conversations with various partners in a multi-session dialogue setup. We propose a new dataset called MiSC to implement this system. The dialogue episodes of MiSC consist of 6 consecutive sessions, with four speakers (one main speaker and three partners) appearing in each episode. Also, we propose a new dialogue model with a novel memory management mechanism, called Egocentric Memory Enhanced Mixed-Session Conversation Agent (EMMA). EMMA collects and retains memories from the main speaker's perspective during conversations with partners, enabling seamless continuity in subsequent interactions. Extensive human evaluations validate that the dialogues in MiSC demonstrate a seamless conversational flow, even when conversation partners change in each session. EMMA trained with MiSC is also evaluated to maintain high memorability without contradiction throughout the entire conversation.
Why Rectified Power Unit Networks Fail and How to Improve It: An Effective Theory Perspective
Aug 04, 2024
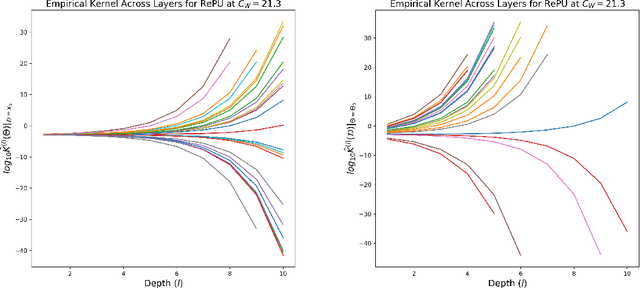
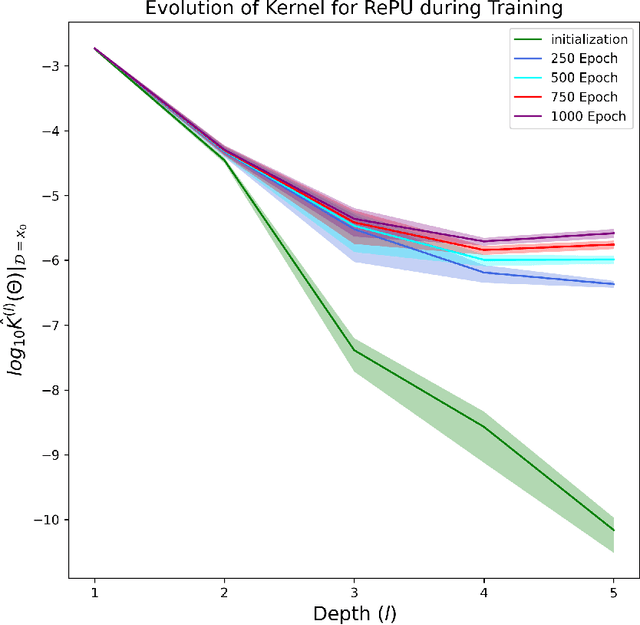
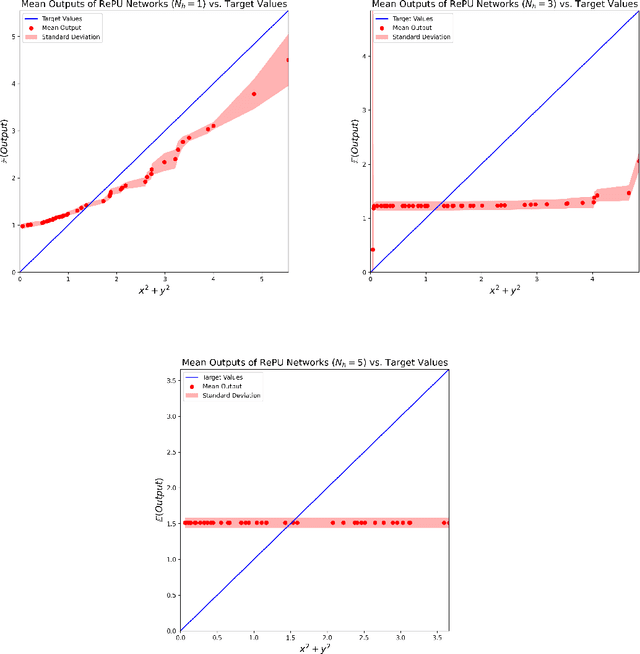
The Rectified Power Unit (RePU) activation functions, unlike the Rectified Linear Unit (ReLU), have the advantage of being a differentiable function when constructing neural networks. However, it can be experimentally observed when deep layers are stacked, neural networks constructed with RePU encounter critical issues. These issues include the values exploding or vanishing and failure of training. And these happen regardless of the hyperparameter initialization. From the perspective of effective theory, we aim to identify the causes of this phenomenon and propose a new activation function that retains the advantages of RePU while overcoming its drawbacks.
Neural Operators Learn the Local Physics of Magnetohydrodynamics
Apr 24, 2024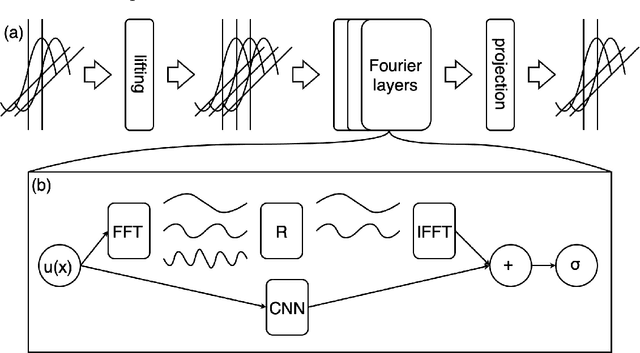
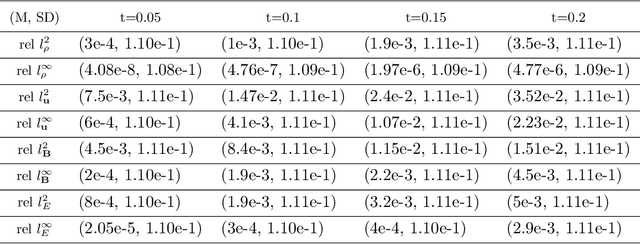
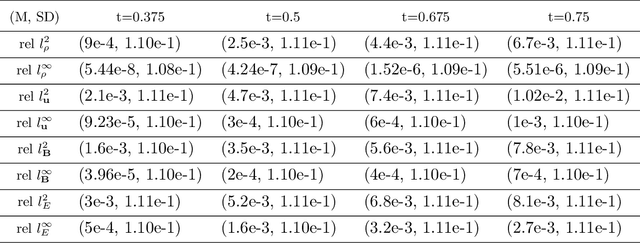
Magnetohydrodynamics (MHD) plays a pivotal role in describing the dynamics of plasma and conductive fluids, essential for understanding phenomena such as the structure and evolution of stars and galaxies, and in nuclear fusion for plasma motion through ideal MHD equations. Solving these hyperbolic PDEs requires sophisticated numerical methods, presenting computational challenges due to complex structures and high costs. Recent advances introduce neural operators like the Fourier Neural Operator (FNO) as surrogate models for traditional numerical analyses. This study explores a modified Flux Fourier neural operator model to approximate the numerical flux of ideal MHD, offering a novel approach that outperforms existing neural operator models by enabling continuous inference, generalization outside sampled distributions, and faster computation compared to classical numerical schemes.
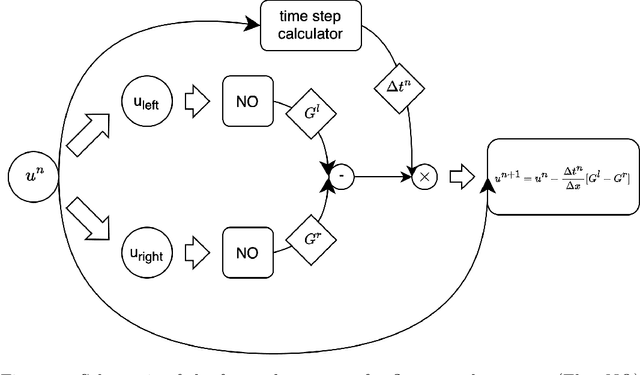
Approximating Numerical Fluxes Using Fourier Neural Operators for Hyperbolic Conservation Laws
Jan 17, 2024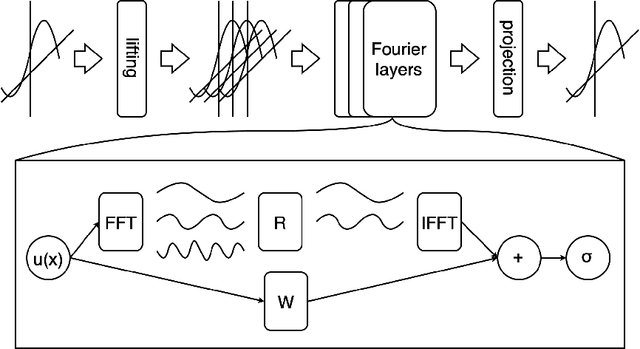
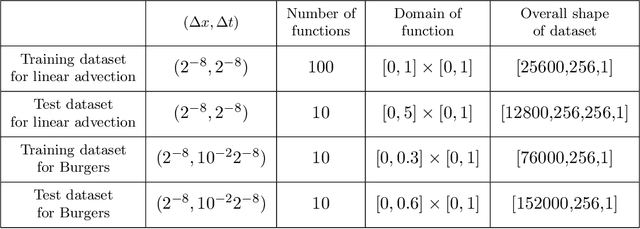
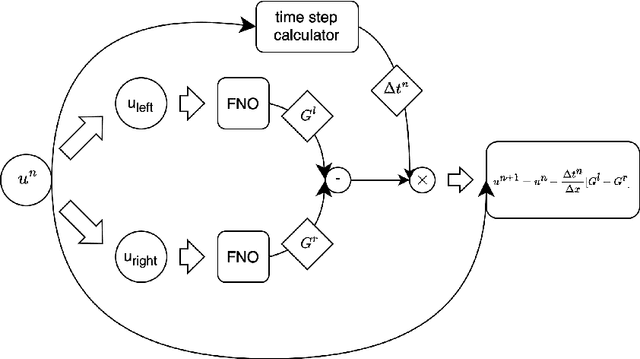
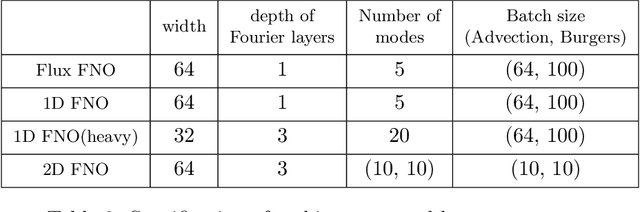
Traditionally, classical numerical schemes have been employed to solve partial differential equations (PDEs) using computational methods. Recently, neural network-based methods have emerged. Despite these advancements, neural network-based methods, such as physics-informed neural networks (PINNs) and neural operators, exhibit deficiencies in robustness and generalization. To address these issues, numerous studies have integrated classical numerical frameworks with machine learning techniques, incorporating neural networks into parts of traditional numerical methods. In this study, we focus on hyperbolic conservation laws by replacing traditional numerical fluxes with neural operators. To this end, we developed loss functions inspired by established numerical schemes related to conservation laws and approximated numerical fluxes using Fourier neural operators (FNOs). Our experiments demonstrated that our approach combines the strengths of both traditional numerical schemes and FNOs, outperforming standard FNO methods in several respects. For instance, we demonstrate that our method is robust, has resolution invariance, and is feasible as a data-driven method. In particular, our method can make continuous predictions over time and exhibits superior generalization capabilities with out-of-distribution (OOD) samples, which are challenges that existing neural operator methods encounter.