 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency Hopping Synchronization by Reinforcement Learning for Satellite Communication System
Mar 06, 2025



Satellite communication systems (SCSs) used for tactical purposes require robust security and anti-jamming capabilities, making frequency hopping (FH) a powerful option. However, the current FH systems face challenges due to significant interference from other devices and the considerable path loss inherent in satellite communication. This misalignment leads to inefficient synchronization, crucial for maintaining reliable communication. Traditional methods, such as those employing long short-term memory (LSTM) networks, have made improvements, but they still struggle in dynamic conditions of satellite environments. This paper presents a novel method for synchronizing FH signals in tactical SCSs by combining serial search and reinforcement learning to achieve coarse and fine acquisition, respectively. The mathematical analysis and simulation results demonstrate that the proposed method reduces the average number of hops required for synchronization by 58.17% and mean squared error (MSE) of the uplink hop timing estimation by 76.95%, as compared to the conventional serial search method. Comparing with the early late gate synchronization method based on serial search and use of LSTM network, the average number of hops for synchronization is reduced by 12.24% and the MSE by 18.5%.
Continuous Adversarial Text Representation Learning for Affective Recognition
Feb 28, 2025

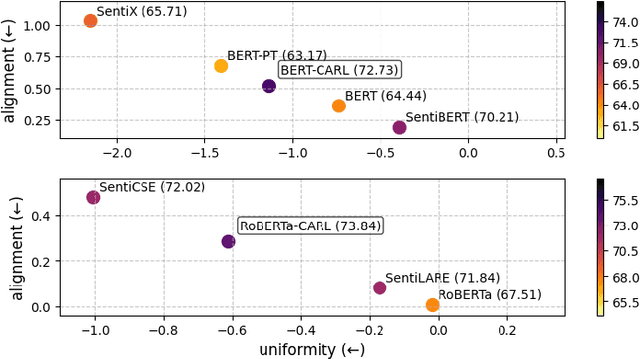

While pre-trained language models excel at semantic understanding, they often struggle to capture nuanced affective information critical for affective recognition tasks. To address these limitations, we propose a novel framework for enhancing emotion-aware embeddings in transformer-based models. Our approach introduces a continuous valence-arousal labeling system to guide contrastive learning, which captures subtle and multi-dimensional emotional nuances more effectively. Furthermore, we employ a dynamic token perturbation mechanism, using gradient-based saliency to focus on sentiment-relevant tokens, improving model sensitivity to emotional cues. The experimental results demonstrate that the proposed framework outperforms existing methods, achieving up to 15.5% improvement in the emotion classification benchmark, highlighting the importance of employing continuous labels. This improvement demonstrates that the proposed framework is effective in affective representation learning and enables precise and contextually relevant emotional understanding.
PoseViNet: Distracted Driver Action Recognition Framework Using Multi-View Pose Estimation and Vision Transformer
Dec 22, 2023Driver distraction is a principal cause of traffic accidents. In a study conducted by the National Highway Traffic Safety Administration, engaging in activities such as interacting with in-car menus, consuming food or beverages, or engaging in telephonic conversations while operating a vehicle can be significant sources of driver distraction. From this viewpoint, this paper introduces a novel method for detection of driver distraction using multi-view driver action images. The proposed method is a vision transformer-based framework with pose estimation and action inference, namely PoseViNet. The motivation for adding posture information is to enable the transformer to focus more on key features. As a result, the framework is more adept at identifying critical actions. The proposed framework is compared with various state-of-the-art models using SFD3 dataset representing 10 behaviors of drivers. It is found from the comparison that the PoseViNet outperforms these models. The proposed framework is also evaluated with the SynDD1 dataset representing 16 behaviors of driver. As a result, the PoseViNet achieves 97.55% validation accuracy and 90.92% testing accuracy with the challenging dataset.
Virtual Action Actor-Critic Framework for Exploration (Student Abstract)
Nov 06, 2023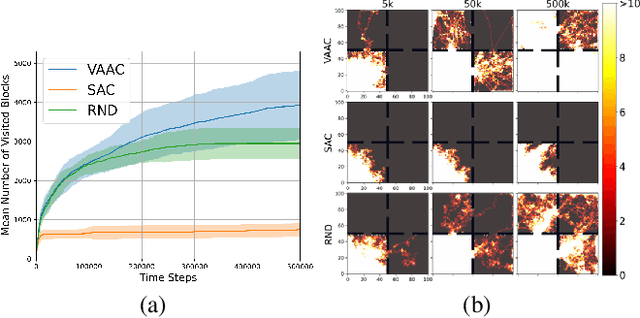
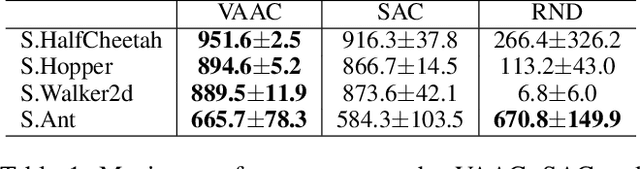
Efficient exploration for an agent is challenging in reinforcement learning (RL). In this paper, a novel actor-critic framework namely virtual action actor-critic (VAAC), is proposed to address the challenge of efficient exploration in RL. This work is inspired by humans' ability to imagine the potential outcomes of their actions without actually taking them. In order to emulate this ability, VAAC introduces a new actor called virtual actor (VA), alongside the conventional actor-critic framework. Unlike the conventional actor, the VA takes the virtual action to anticipate the next state without interacting with the environment. With the virtual policy following a Gaussian distribution, the VA is trained to maximize the anticipated novelty of the subsequent state resulting from a virtual action. If any next state resulting from available actions does not exhibit high anticipated novelty, training the VA leads to an increase in the virtual policy entropy. Hence, high virtual policy entropy represents that there is no room for exploration. The proposed VAAC aims to maximize a modified Q function, which combines cumulative rewards and the negative sum of virtual policy entropy. Experimental results show that the VAAC improves the exploration performance compared to existing algorithms.
Enhanced Transformer Architecture for Natural Language Processing
Oct 17, 2023



Transformer is a state-of-the-art model in the field of natural language processing (NLP). Current NLP models primarily increase the number of transformers to improve processing performance. However, this technique requires a lot of training resources such as computing capacity. In this paper, a novel structure of Transformer is proposed. It is featured by full layer normalization, weighted residual connection, positional encoding exploiting reinforcement learning, and zero masked self-attention. The proposed Transformer model, which is called Enhanced Transformer, is validated by the bilingual evaluation understudy (BLEU) score obtained with the Multi30k translation dataset. As a result, the Enhanced Transformer achieves 202.96% higher BLEU score as compared to the original transformer with the translation dataset.
Sensor Fusion by Spatial Encoding for Autonomous Driving
Aug 17, 2023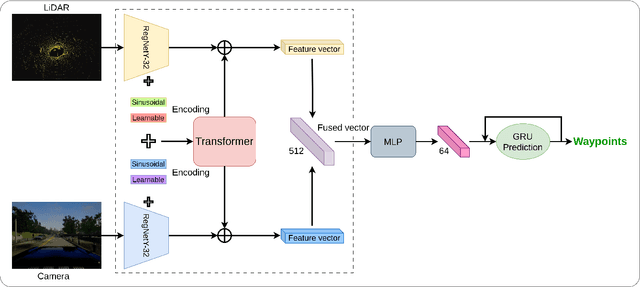

Sensor fusion is critical to perception systems for task domains such as autonomous driving and robotics. Recently, the Transformer integrated with CNN has demonstrated high performance in sensor fusion for various perception tasks. In this work, we introduce a method for fusing data from camera and LiDAR. By employing Transformer modules at multiple resolutions, proposed method effectively combines local and global contextual relationships. The performance of the proposed method is validated by extensive experiments with two adversarial benchmarks with lengthy routes and high-density traffics. The proposed method outperforms previous approaches with the most challenging benchmarks, achieving significantly higher driving and infraction scores. Compared with TransFuser, it achieves 8% and 19% improvement in driving scores for the Longest6 and Town05 Long benchmarks, respectively.
Road Redesign Technique Achieving Enhanced Road Safety by Inpainting with a Diffusion Model
Feb 15, 2023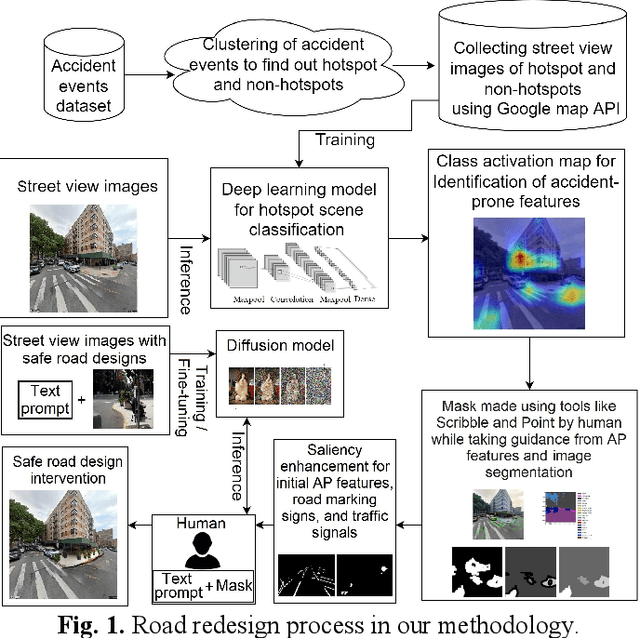
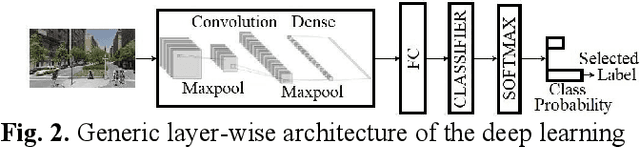

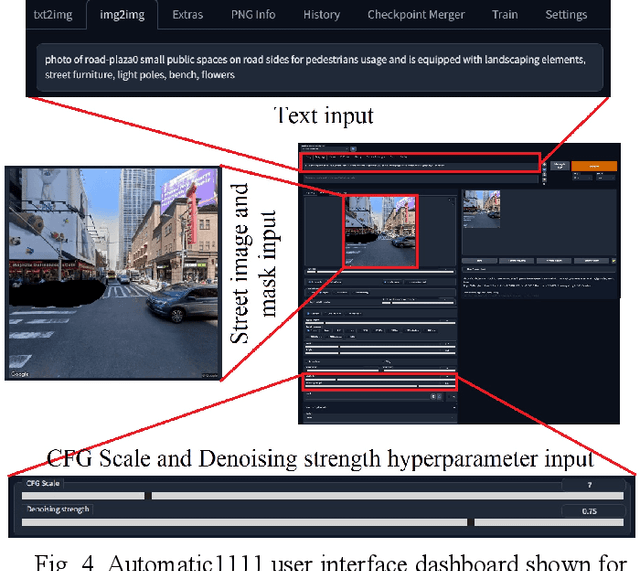
Road infrastructure can affect the occurrence of road accidents. Therefore, identifying roadway features with high accident probability is crucial. Here, we introduce image inpainting that can assist authorities in achieving safe roadway design with minimal intervention in the current roadway structure. Image inpainting is based on inpainting safe roadway elements in a roadway image, replacing accident-prone (AP) features by using a diffusion model. After object-level segmentation, the AP features identified by the properties of accident hotspots are masked by a human operator and safe roadway elements are inpainted. With only an average time of 2 min for image inpainting, the likelihood of an image being classified as an accident hotspot drops by an average of 11.85%. In addition, safe urban spaces can be designed considering human factors of commuters such as gaze saliency. Considering this, we introduce saliency enhancement that suggests chrominance alteration for a safe road view.
Off-Policy Reinforcement Learning with Loss Function Weighted by Temporal Difference Error
Dec 26, 2022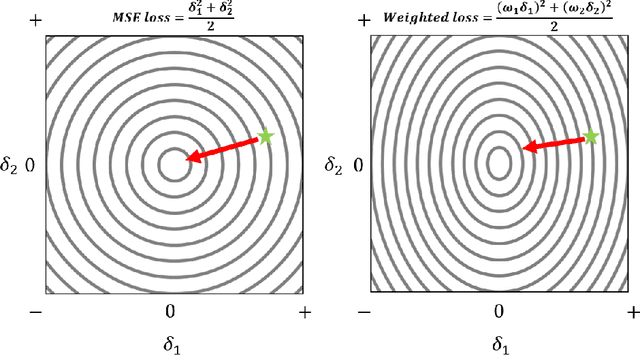
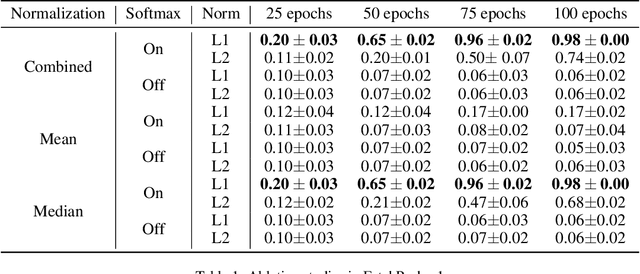
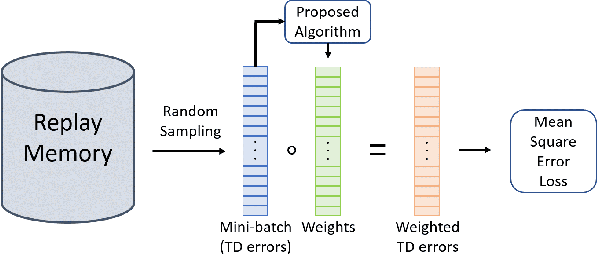
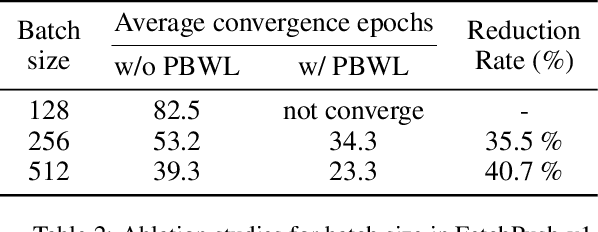
Training agents via off-policy deep reinforcement learning (RL) requires a large memory, named replay memory, that stores past experiences used for learning. These experiences are sampled, uniformly or non-uniformly, to create the batches used for training. When calculating the loss function, off-policy algorithms assume that all samples are of the same importance. In this paper, we hypothesize that training can be enhanced by assigning different importance for each experience based on their temporal-difference (TD) error directly in the training objective. We propose a novel method that introduces a weighting factor for each experience when calculating the loss function at the learning stage. In addition to improving convergence speed when used with uniform sampling, the method can be combined with prioritization methods for non-uniform sampling. Combining the proposed method with prioritization methods improves sampling efficiency while increasing the performance of TD-based off-policy RL algorithms. The effectiveness of the proposed method is demonstrated by experiments in six environments of the OpenAI Gym suite. The experimental results demonstrate that the proposed method achieves a 33%~76% reduction of convergence speed in three environments and an 11% increase in returns and a 3%~10% increase in success rate for other three environments.
Reinforcement Learning for Predicting Traffic Accidents
Dec 09, 2022
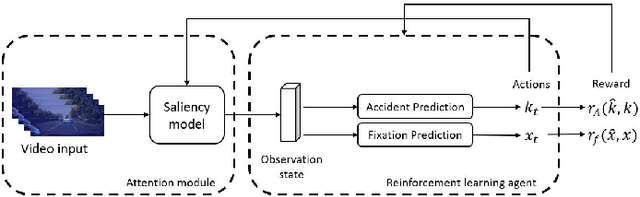


As the demand for autonomous driving increases, it is paramount to ensure safety. Early accident prediction using deep learning methods for driving safety has recently gained much attention. In this task, early accident prediction and a point prediction of where the drivers should look are determined, with the dashcam video as input. We propose to exploit the double actors and regularized critics (DARC) method, for the first time, on this accident forecasting platform. We derive inspiration from DARC since it is currently a state-of-the-art reinforcement learning (RL) model on continuous action space suitable for accident anticipation. Results show that by utilizing DARC, we can make predictions 5\% earlier on average while improving in multiple metrics of precision compared to existing methods. The results imply that using our RL-based problem formulation could significantly increase the safety of autonomous driving.
Kick-motion Training with DQN in AI Soccer Environment
Dec 01, 2022



This paper presents a technique to train a robot to perform kick-motion in AI soccer by using reinforcement learning (RL). In RL, an agent interacts with an environment and learns to choose an action in a state at each step. When training RL algorithms, a problem called the curse of dimensionality (COD) can occur if the dimension of the state is high and the number of training data is low. The COD often causes degraded performance of RL models. In the situation of the robot kicking the ball, as the ball approaches the robot, the robot chooses the action based on the information obtained from the soccer field. In order not to suffer COD, the training data, which are experiences in the case of RL, should be collected evenly from all areas of the soccer field over (theoretically infinite) time. In this paper, we attempt to use the relative coordinate system (RCS) as the state for training kick-motion of robot agent, instead of using the absolute coordinate system (ACS). Using the RCS eliminates the necessity for the agent to know all the (state) information of entire soccer field and reduces the dimension of the state that the agent needs to know to perform kick-motion, and consequently alleviates COD. The training based on the RCS is performed with the widely used Deep Q-network (DQN) and tested in the AI Soccer environment implemented with Webots simulation software.