 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Vision Transformers in Autonomous Driving: Current Trends and Future Directions
Mar 12, 2024


This survey explores the adaptation of visual transformer models in Autonomous Driving, a transition inspired by their success in Natural Language Processing. Surpassing traditional Recurrent Neural Networks in tasks like sequential image processing and outperforming Convolutional Neural Networks in global context capture, as evidenced in complex scene recognition, Transformers are gaining traction in computer vision. These capabilities are crucial in Autonomous Driving for real-time, dynamic visual scene processing. Our survey provides a comprehensive overview of Vision Transformer applications in Autonomous Driving, focusing on foundational concepts such as self-attention, multi-head attention, and encoder-decoder architecture. We cover applications in object detection, segmentation, pedestrian detection, lane detection, and more, comparing their architectural merits and limitations. The survey concludes with future research directions, highlighting the growing role of Vision Transformers in Autonomous Driving.
Virtual Action Actor-Critic Framework for Exploration (Student Abstract)
Nov 06, 2023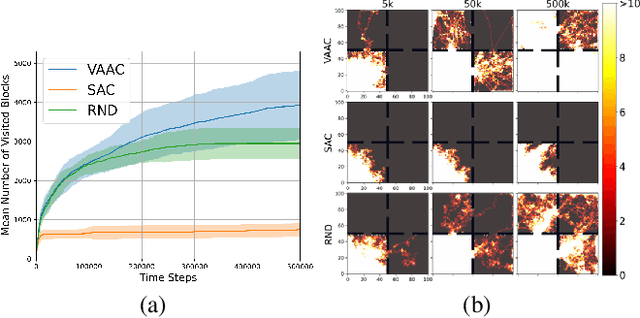
Efficient exploration for an agent is challenging in reinforcement learning (RL). In this paper, a novel actor-critic framework namely virtual action actor-critic (VAAC), is proposed to address the challenge of efficient exploration in RL. This work is inspired by humans' ability to imagine the potential outcomes of their actions without actually taking them. In order to emulate this ability, VAAC introduces a new actor called virtual actor (VA), alongside the conventional actor-critic framework. Unlike the conventional actor, the VA takes the virtual action to anticipate the next state without interacting with the environment. With the virtual policy following a Gaussian distribution, the VA is trained to maximize the anticipated novelty of the subsequent state resulting from a virtual action. If any next state resulting from available actions does not exhibit high anticipated novelty, training the VA leads to an increase in the virtual policy entropy. Hence, high virtual policy entropy represents that there is no room for exploration. The proposed VAAC aims to maximize a modified Q function, which combines cumulative rewards and the negative sum of virtual policy entropy. Experimental results show that the VAAC improves the exploration performance compared to existing algorithms.
Sensor Fusion by Spatial Encoding for Autonomous Driving
Aug 17, 2023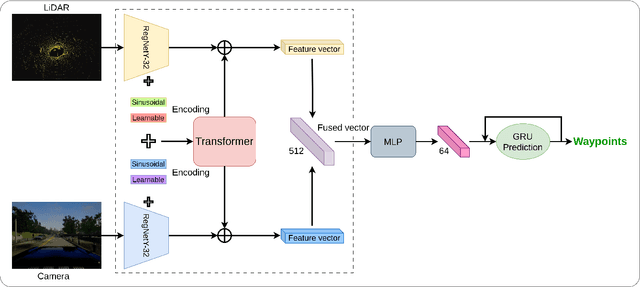

Sensor fusion is critical to perception systems for task domains such as autonomous driving and robotics. Recently, the Transformer integrated with CNN has demonstrated high performance in sensor fusion for various perception tasks. In this work, we introduce a method for fusing data from camera and LiDAR. By employing Transformer modules at multiple resolutions, proposed method effectively combines local and global contextual relationships. The performance of the proposed method is validated by extensive experiments with two adversarial benchmarks with lengthy routes and high-density traffics. The proposed method outperforms previous approaches with the most challenging benchmarks, achieving significantly higher driving and infraction scores. Compared with TransFuser, it achieves 8% and 19% improvement in driving scores for the Longest6 and Town05 Long benchmarks, respectively.
A Lightweight Domain Adaptive Absolute Pose Regressor Using Barlow Twins Objective
Nov 20, 2022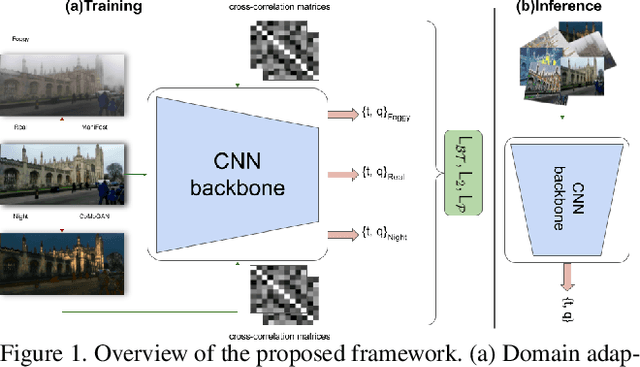
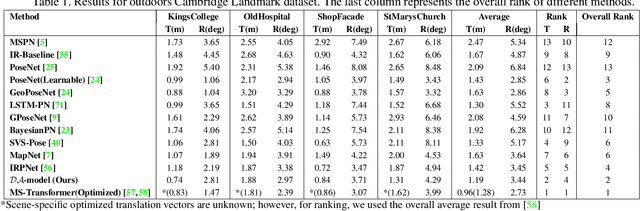
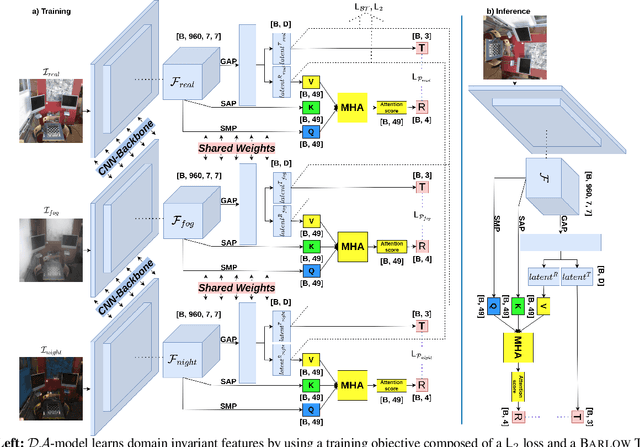
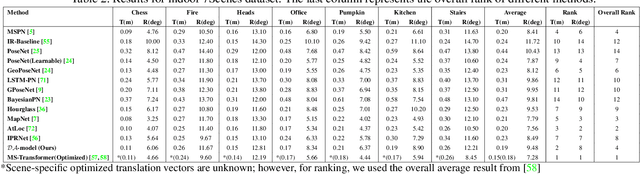
Identifying the camera pose for a given image is a challenging problem with applications in robotics, autonomous vehicles, and augmented/virtual reality. Lately, learning-based methods have shown to be effective for absolute camera pose estimation. However, these methods are not accurate when generalizing to different domains. In this paper, a domain adaptive training framework for absolute pose regression is introduced. In the proposed framework, the scene image is augmented for different domains by using generative methods to train parallel branches using Barlow Twins objective. The parallel branches leverage a lightweight CNN-based absolute pose regressor architecture. Further, the efficacy of incorporating spatial and channel-wise attention in the regression head for rotation prediction is investigated. Our method is evaluated with two datasets, Cambridge landmarks and 7Scenes. The results demonstrate that, even with using roughly 24 times fewer FLOPs, 12 times fewer activations, and 5 times fewer parameters than MS-Transformer, our approach outperforms all the CNN-based architectures and achieves performance comparable to transformer-based architectures. Our method ranks 2nd and 4th with the Cambridge Landmarks and 7Scenes datasets, respectively. In addition, for augmented domains not encountered during training, our approach significantly outperforms the MS-transformer. Furthermore, it is shown that our domain adaptive framework achieves better performance than the single branch model trained with the identical CNN backbone with all instances of the unseen distribution.