 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropouts in Confidence: Moral Uncertainty in Human-LLM Alignment
Nov 17, 2025Humans display significant uncertainty when confronted with moral dilemmas, yet the extent of such uncertainty in machines and AI agents remains underexplored. Recent studies have confirmed the overly confident tendencies of machine-generated responses, particularly in large language models (LLMs). As these systems are increasingly embedded in ethical decision-making scenarios, it is important to understand their moral reasoning and the inherent uncertainties in building reliable AI systems. This work examines how uncertainty influences moral decisions in the classical trolley problem, analyzing responses from 32 open-source models and 9 distinct moral dimensions. We first find that variance in model confidence is greater across models than within moral dimensions, suggesting that moral uncertainty is predominantly shaped by model architecture and training method. To quantify uncertainty, we measure binary entropy as a linear combination of total entropy, conditional entropy, and mutual information. To examine its effects, we introduce stochasticity into models via "dropout" at inference time. Our findings show that our mechanism increases total entropy, mainly through a rise in mutual information, while conditional entropy remains largely unchanged. Moreover, this mechanism significantly improves human-LLM moral alignment, with correlations in mutual information and alignment score shifts. Our results highlight the potential to better align model-generated decisions and human preferences by deliberately modulating uncertainty and reducing LLMs' confidence in morally complex scenarios.
Exploring Persona-dependent LLM Alignment for the Moral Machine Experiment
Apr 15, 2025Deploying large language models (LLMs) with agency in real-world applications raises critical questions about how these models will behave. In particular, how will their decisions align with humans when faced with moral dilemmas? This study examines the alignment between LLM-driven decisions and human judgment in various contexts of the moral machine experiment, including personas reflecting different sociodemographics. We find that the moral decisions of LLMs vary substantially by persona, showing greater shifts in moral decisions for critical tasks than humans. Our data also indicate an interesting partisan sorting phenomenon, where political persona predominates the direction and degree of LLM decisions. We discuss the ethical implications and risks associated with deploying these models in applications that involve moral decisions.
Recent advances in interpretable machine learning using structure-based protein representations
Sep 26, 2024Recent advancements in machine learning (ML) are transforming the field of structural biology. For example, AlphaFold, a groundbreaking neural network for protein structure prediction, has been widely adopted by researchers. The availability of easy-to-use interfaces and interpretable outcomes from the neural network architecture, such as the confidence scores used to color the predicted structures, have made AlphaFold accessible even to non-ML experts. In this paper, we present various methods for representing protein 3D structures from low- to high-resolution, and show how interpretable ML methods can support tasks such as predicting protein structures, protein function, and protein-protein interactions. This survey also emphasizes the significance of interpreting and visualizing ML-based inference for structure-based protein representations that enhance interpretability and knowledge discovery. Developing such interpretable approaches promises to further accelerate fields including drug development and protein design.
Robust Optimization in Protein Fitness Landscapes Using Reinforcement Learning in Latent Space
May 29, 2024



Proteins are complex molecules responsible for different functions in nature. Enhancing the functionality of proteins and cellular fitness can significantly impact various industries. However, protein optimization using computational methods remains challenging, especially when starting from low-fitness sequences. We propose LatProtRL, an optimization method to efficiently traverse a latent space learned by an encoder-decoder leveraging a large protein language model. To escape local optima, our optimization is modeled as a Markov decision process using reinforcement learning acting directly in latent space. We evaluate our approach on two important fitness optimization tasks, demonstrating its ability to achieve comparable or superior fitness over baseline methods. Our findings and in vitro evaluation show that the generated sequences can reach high-fitness regions, suggesting a substantial potential of LatProtRL in lab-in-the-loop scenarios.
Off-Policy Reinforcement Learning with Loss Function Weighted by Temporal Difference Error
Dec 26, 2022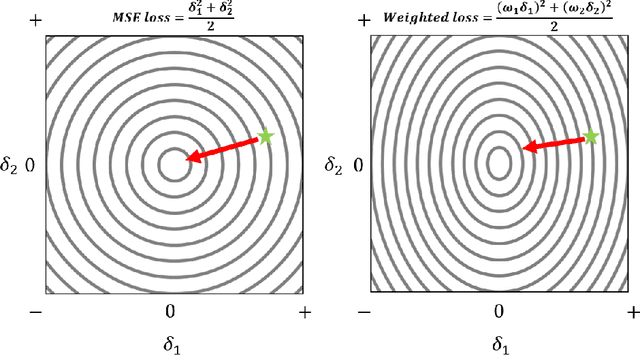
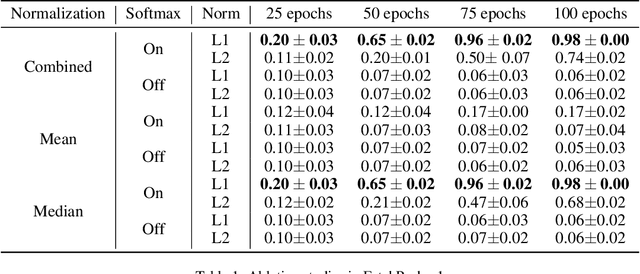
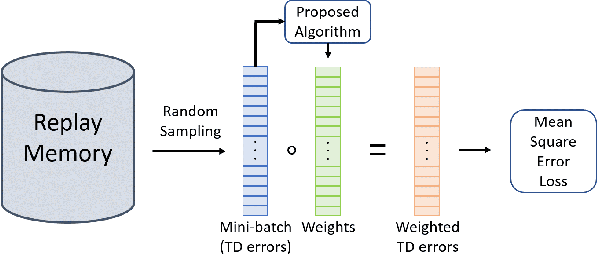
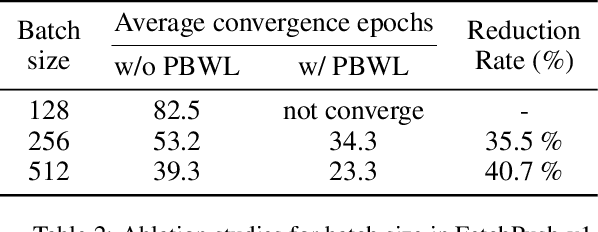
Training agents via off-policy deep reinforcement learning (RL) requires a large memory, named replay memory, that stores past experiences used for learning. These experiences are sampled, uniformly or non-uniformly, to create the batches used for training. When calculating the loss function, off-policy algorithms assume that all samples are of the same importance. In this paper, we hypothesize that training can be enhanced by assigning different importance for each experience based on their temporal-difference (TD) error directly in the training objective. We propose a novel method that introduces a weighting factor for each experience when calculating the loss function at the learning stage. In addition to improving convergence speed when used with uniform sampling, the method can be combined with prioritization methods for non-uniform sampling. Combining the proposed method with prioritization methods improves sampling efficiency while increasing the performance of TD-based off-policy RL algorithms. The effectiveness of the proposed method is demonstrated by experiments in six environments of the OpenAI Gym suite. The experimental results demonstrate that the proposed method achieves a 33%~76% reduction of convergence speed in three environments and an 11% increase in returns and a 3%~10% increase in success rate for other three environments.
A Lightweight Domain Adaptive Absolute Pose Regressor Using Barlow Twins Objective
Nov 20, 2022
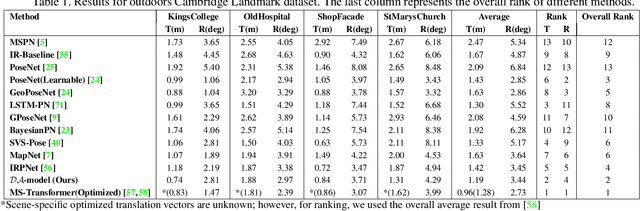
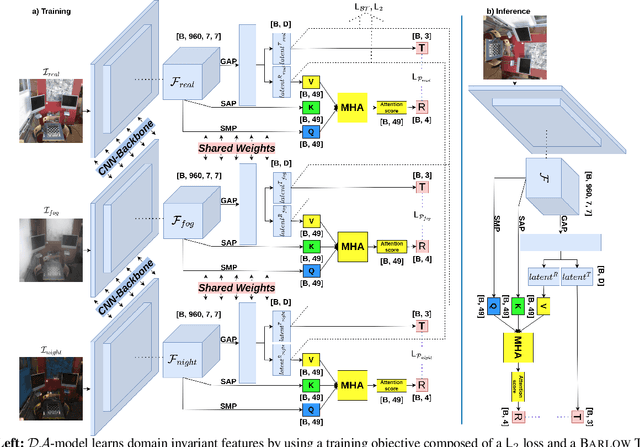
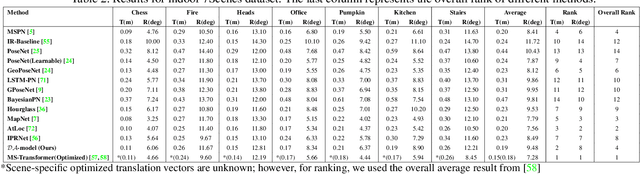
Identifying the camera pose for a given image is a challenging problem with applications in robotics, autonomous vehicles, and augmented/virtual reality. Lately, learning-based methods have shown to be effective for absolute camera pose estimation. However, these methods are not accurate when generalizing to different domains. In this paper, a domain adaptive training framework for absolute pose regression is introduced. In the proposed framework, the scene image is augmented for different domains by using generative methods to train parallel branches using Barlow Twins objective. The parallel branches leverage a lightweight CNN-based absolute pose regressor architecture. Further, the efficacy of incorporating spatial and channel-wise attention in the regression head for rotation prediction is investigated. Our method is evaluated with two datasets, Cambridge landmarks and 7Scenes. The results demonstrate that, even with using roughly 24 times fewer FLOPs, 12 times fewer activations, and 5 times fewer parameters than MS-Transformer, our approach outperforms all the CNN-based architectures and achieves performance comparable to transformer-based architectures. Our method ranks 2nd and 4th with the Cambridge Landmarks and 7Scenes datasets, respectively. In addition, for augmented domains not encountered during training, our approach significantly outperforms the MS-transformer. Furthermore, it is shown that our domain adaptive framework achieves better performance than the single branch model trained with the identical CNN backbone with all instances of the unseen distribution.
RELMOBNET: A Robust Two-Stage End-To-End Training Approach For MOBILENETV3 Based Relative Camera Pose Estimation
Feb 25, 2022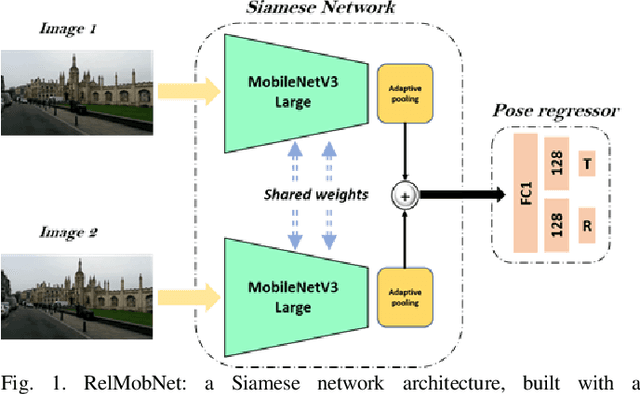
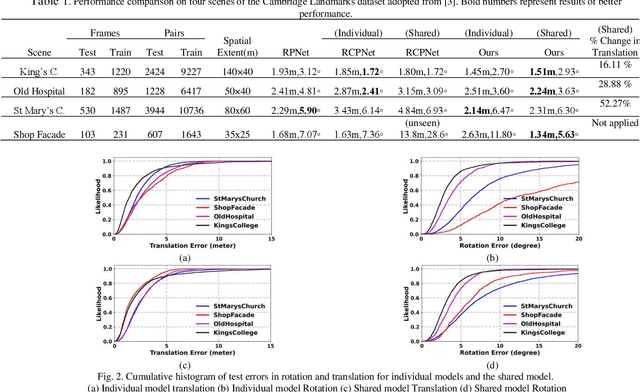
Relative camera pose estimation plays a pivotal role in dealing with 3D reconstruction and visual localization. To address this, we propose a Siamese network based on MobileNetV3-Large for an end-to-end relative camera pose regression independent of camera parameters. The proposed network uses pair of images taken at different locations in the same scene to estimate the 3D translation vector and rotation vector in unit quaternion. To increase the generality of the model, rather than training it for a single scene, data for four scenes are combined to train a single universal model to estimate the relative pose. Further for independency of hyperparameter weighing between translation and rotation loss is not used. Instead we use the novel two-stage training procedure to learn the balance implicitly with faster convergence. We compare the results obtained with the Cambridge Landmarks dataset, comprising of different scenes, with existing CNN-based regression methods as baselines, e.g., RPNet and RCPNet. The findings indicate that, when compared to RCPNet, proposed model improves the estimation of the translation vector by a percentage change of 16.11%, 28.88%, 52.27% on the Kings College, Old Hospital, St Marys Church scenes from Cambridge Landmarks dataset, respectively.
Sensing accident-prone features in urban scenes for proactive driving and accident prevention
Feb 25, 2022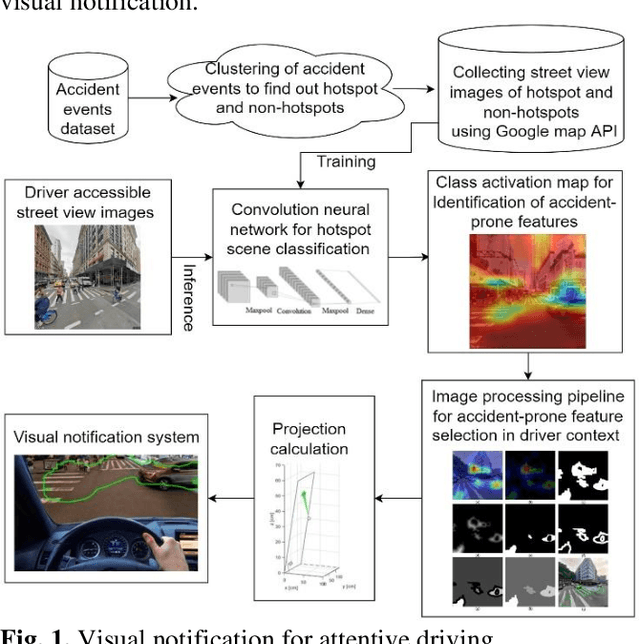
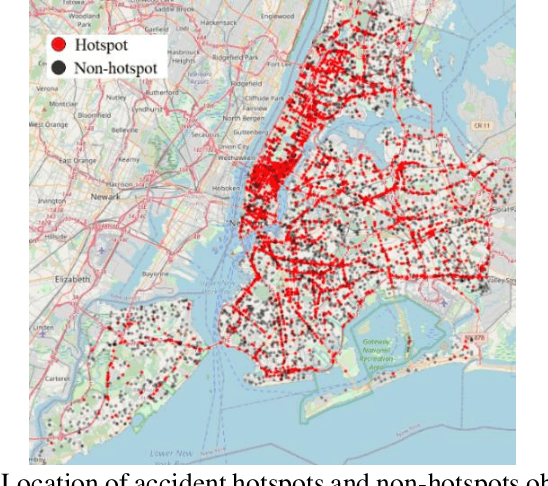
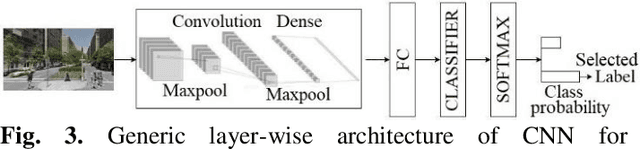

In urban cities, visual information along and on roadways is likely to distract drivers and leads to missing traffic signs and other accident-prone features. As a solution to avoid accidents due to missing these visual cues, this paper proposes a visual notification of accident-prone features to drivers, based on real-time images obtained via dashcam. For this purpose, Google Street View images around accident hotspots (areas of dense accident occurrence) identified by accident dataset are used to train a family of deep convolutional neural networks (CNNs). Trained CNNs are able to detect accident-prone features and classify a given urban scene into an accident hotspot and a non-hotspot (area of sparse accident occurrence). For given accident hotspot, the trained CNNs can classify it into an accident hotspot with the accuracy up to 90%. The capability of detecting accident-prone features by the family of CNNs is analyzed by a comparative study of four different class activation map (CAM) methods, which are used to inspect specific accident-prone features causing the decision of CNNs, and pixel-level object class classification. The outputs of CAM methods are processed by an image processing pipeline to extract only the accident-prone features that are explainable to drivers with the help of visual notification system. To prove the efficacy of accident-prone features, an ablation study is conducted. Ablation of accident-prone features taking 7.7%, on average, of total area in each image sample causes up to 13.7% more chance of given area to be classified as a non-hotspot.
Two-stage training algorithm for AI robot soccer
Apr 13, 2021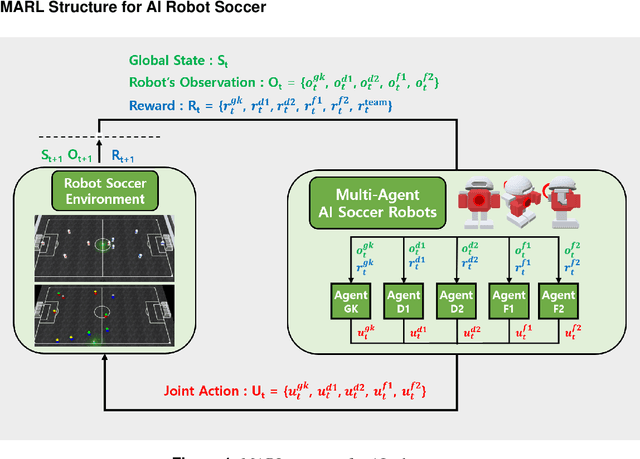
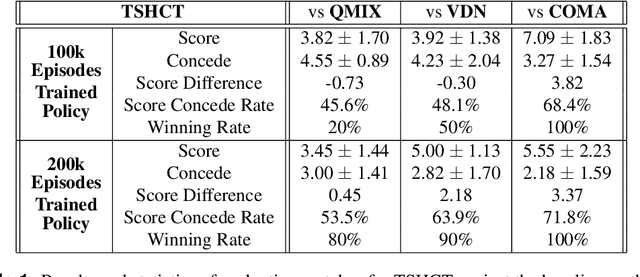
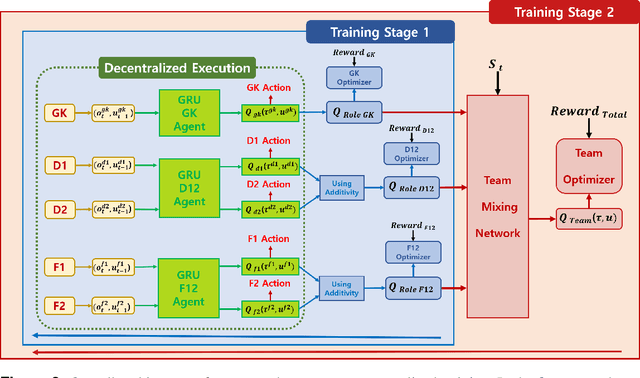
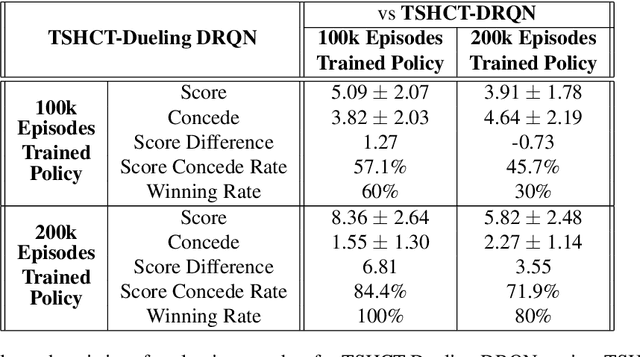
In multi-agent reinforcement learning, the cooperative learning behavior of agents is very important. In the field of heterogeneous multi-agent reinforcement learning, cooperative behavior among different types of agents in a group is pursued. Learning a joint-action set during centralized training is an attractive way to obtain such cooperative behavior, however, this method brings limited learning performance with heterogeneous agents. To improve the learning performance of heterogeneous agents during centralized training, two-stage heterogeneous centralized training which allows the training of multiple roles of heterogeneous agents is proposed. During training, two training processes are conducted in a series. One of the two stages is to attempt training each agent according to its role, aiming at the maximization of individual role rewards. The other is for training the agents as a whole to make them learn cooperative behaviors while attempting to maximize shared collective rewards, e.g., team rewards. Because these two training processes are conducted in a series in every timestep, agents can learn how to maximize role rewards and team rewards simultaneously. The proposed method is applied to 5 versus 5 AI robot soccer for validation. Simulation results show that the proposed method can train the robots of the robot soccer team effectively, achieving higher role rewards and higher team rewards as compared to other approaches that can be used to solve problems of training cooperative multi-agent.