 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Predicting Traffic Accidents
Dec 09, 2022
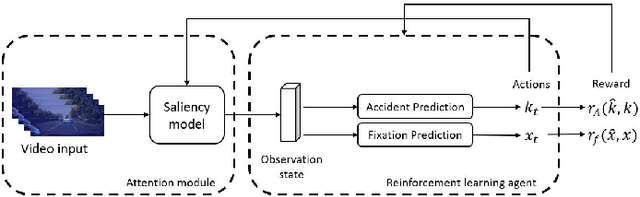


As the demand for autonomous driving increases, it is paramount to ensure safety. Early accident prediction using deep learning methods for driving safety has recently gained much attention. In this task, early accident prediction and a point prediction of where the drivers should look are determined, with the dashcam video as input. We propose to exploit the double actors and regularized critics (DARC) method, for the first time, on this accident forecasting platform. We derive inspiration from DARC since it is currently a state-of-the-art reinforcement learning (RL) model on continuous action space suitable for accident anticipation. Results show that by utilizing DARC, we can make predictions 5\% earlier on average while improving in multiple metrics of precision compared to existing methods. The results imply that using our RL-based problem formulation could significantly increase the safety of autonomous driving.
A Lightweight Domain Adaptive Absolute Pose Regressor Using Barlow Twins Objective
Nov 20, 2022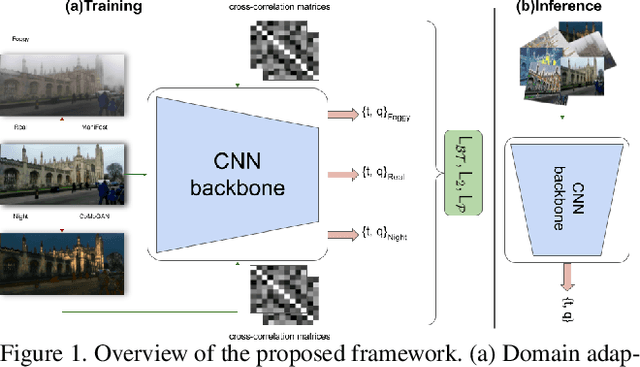
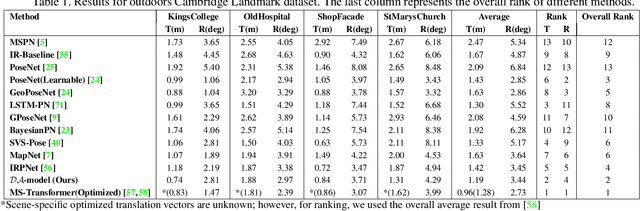
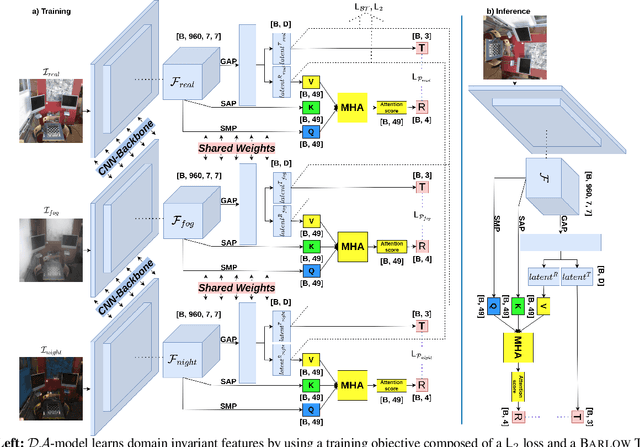
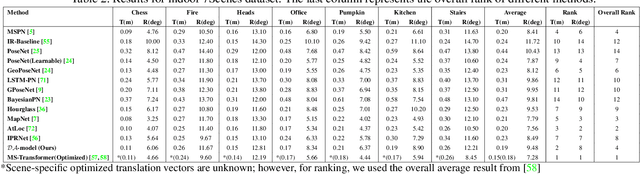
Identifying the camera pose for a given image is a challenging problem with applications in robotics, autonomous vehicles, and augmented/virtual reality. Lately, learning-based methods have shown to be effective for absolute camera pose estimation. However, these methods are not accurate when generalizing to different domains. In this paper, a domain adaptive training framework for absolute pose regression is introduced. In the proposed framework, the scene image is augmented for different domains by using generative methods to train parallel branches using Barlow Twins objective. The parallel branches leverage a lightweight CNN-based absolute pose regressor architecture. Further, the efficacy of incorporating spatial and channel-wise attention in the regression head for rotation prediction is investigated. Our method is evaluated with two datasets, Cambridge landmarks and 7Scenes. The results demonstrate that, even with using roughly 24 times fewer FLOPs, 12 times fewer activations, and 5 times fewer parameters than MS-Transformer, our approach outperforms all the CNN-based architectures and achieves performance comparable to transformer-based architectures. Our method ranks 2nd and 4th with the Cambridge Landmarks and 7Scenes datasets, respectively. In addition, for augmented domains not encountered during training, our approach significantly outperforms the MS-transformer. Furthermore, it is shown that our domain adaptive framework achieves better performance than the single branch model trained with the identical CNN backbone with all instances of the unseen distribution.
RELMOBNET: A Robust Two-Stage End-To-End Training Approach For MOBILENETV3 Based Relative Camera Pose Estimation
Feb 25, 2022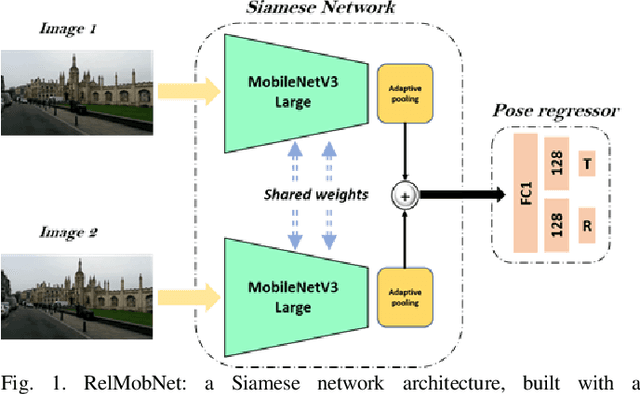
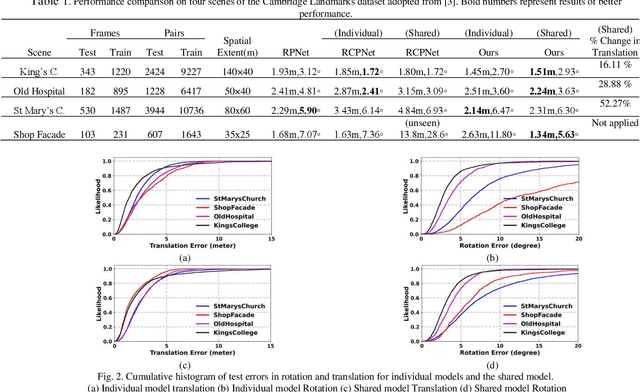
Relative camera pose estimation plays a pivotal role in dealing with 3D reconstruction and visual localization. To address this, we propose a Siamese network based on MobileNetV3-Large for an end-to-end relative camera pose regression independent of camera parameters. The proposed network uses pair of images taken at different locations in the same scene to estimate the 3D translation vector and rotation vector in unit quaternion. To increase the generality of the model, rather than training it for a single scene, data for four scenes are combined to train a single universal model to estimate the relative pose. Further for independency of hyperparameter weighing between translation and rotation loss is not used. Instead we use the novel two-stage training procedure to learn the balance implicitly with faster convergence. We compare the results obtained with the Cambridge Landmarks dataset, comprising of different scenes, with existing CNN-based regression methods as baselines, e.g., RPNet and RCPNet. The findings indicate that, when compared to RCPNet, proposed model improves the estimation of the translation vector by a percentage change of 16.11%, 28.88%, 52.27% on the Kings College, Old Hospital, St Marys Church scenes from Cambridge Landmarks dataset, respectively.
Sensing accident-prone features in urban scenes for proactive driving and accident prevention
Feb 25, 2022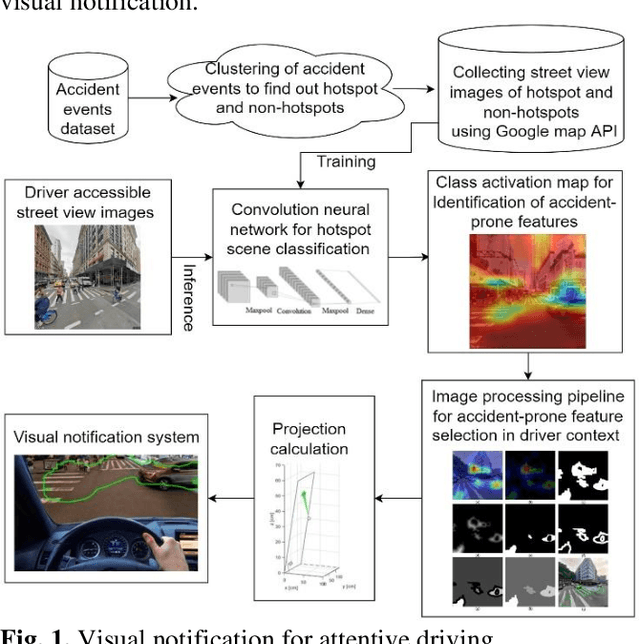
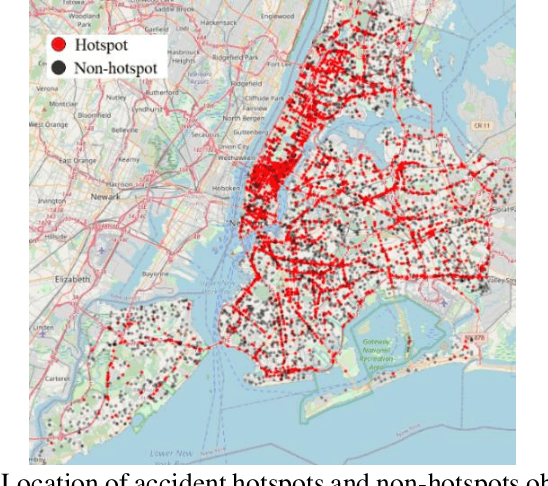
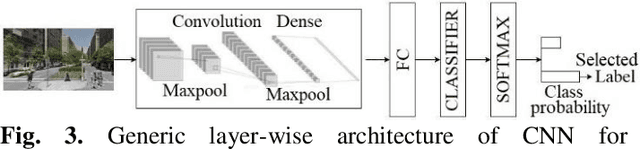

In urban cities, visual information along and on roadways is likely to distract drivers and leads to missing traffic signs and other accident-prone features. As a solution to avoid accidents due to missing these visual cues, this paper proposes a visual notification of accident-prone features to drivers, based on real-time images obtained via dashcam. For this purpose, Google Street View images around accident hotspots (areas of dense accident occurrence) identified by accident dataset are used to train a family of deep convolutional neural networks (CNNs). Trained CNNs are able to detect accident-prone features and classify a given urban scene into an accident hotspot and a non-hotspot (area of sparse accident occurrence). For given accident hotspot, the trained CNNs can classify it into an accident hotspot with the accuracy up to 90%. The capability of detecting accident-prone features by the family of CNNs is analyzed by a comparative study of four different class activation map (CAM) methods, which are used to inspect specific accident-prone features causing the decision of CNNs, and pixel-level object class classification. The outputs of CAM methods are processed by an image processing pipeline to extract only the accident-prone features that are explainable to drivers with the help of visual notification system. To prove the efficacy of accident-prone features, an ablation study is conducted. Ablation of accident-prone features taking 7.7%, on average, of total area in each image sample causes up to 13.7% more chance of given area to be classified as a non-hotspot.
Socially acceptable route planning and trajectory behavior analysis of personal mobility device for mobility management with improved sensing
Dec 07, 2021
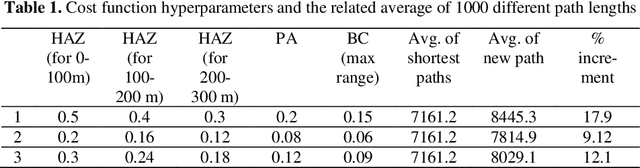
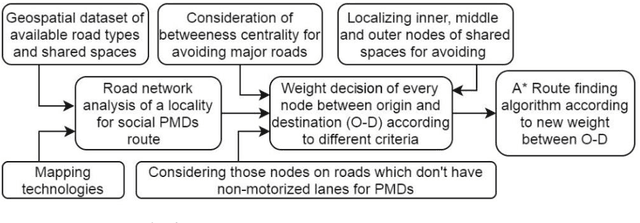
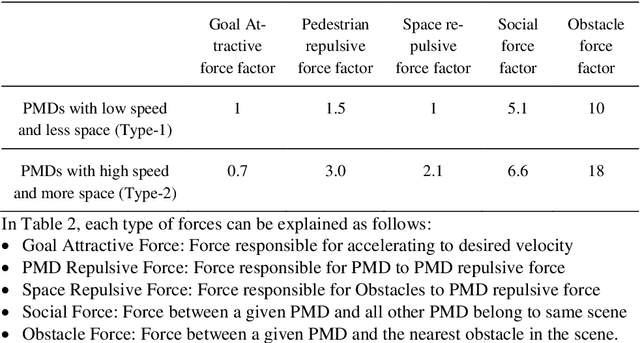
In urban cities, with increasing acceptability of shared spaces used by pedestrians and personal mobility devices (PMDs), there is need for pragmatic socially ac-ceptable path planning and navigation management policies. Hence, we propose a socially acceptable global route planner and assess the legibility of the resulting global route. Our approach proposed for choosing global route avoids streets penetrating shared spaces and main routes with high probability of dense usage. The experimental study shows that socially acceptable routes can be effectively found with an average of 10 % increment of route length with optimal hyperpa-rameters. This helps PMDs to reach the goal while taking a socially acceptable and safe route with minimal interaction of different PMDs and pedestrians. When PMDs interact with pedestrians and other types of PMDs in shared spaces, mi-cro-mobility simulations are of prime usage for acceptable and safe navigation policy. Social force models being state of the art for pedestrian simulation are cal-ibrated for capturing random movements of pedestrian behavior. Social force model with calibration can imitate the required behavior of PMDs in a pedestrian mix navigation scheme. Based on calibrated models, simulations on shared space links and gate structures are performed to assist policies related to deciding wait-ing and stopping time. Also, based on simulated PMDs interaction with pedestri-ans, location data with finer resolution can be obtained if the resolution of GPS sensor is 0.2 m or less. This will help in formalizing better modelling and hence better micro-mobility policies.