 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Policy Backbone via Shared Network
Sep 26, 2025Reinforcement learning (RL) has achieved impressive results across domains, yet learning an optimal policy typically requires extensive interaction data, limiting practical deployment. A common remedy is to leverage priors, such as pre-collected datasets or reference policies, but their utility degrades under task mismatch between training and deployment. While prior work has sought to address this mismatch, it has largely been restricted to in-distribution settings. To address this challenge, we propose Adaptive Policy Backbone (APB), a meta-transfer RL method that inserts lightweight linear layers before and after a shared backbone, thereby enabling parameter-efficient fine-tuning (PEFT) while preserving prior knowledge during adaptation. Our results show that APB improves sample efficiency over standard RL and adapts to out-of-distribution (OOD) tasks where existing meta-RL baselines typically fail.
Virtual Action Actor-Critic Framework for Exploration (Student Abstract)
Nov 06, 2023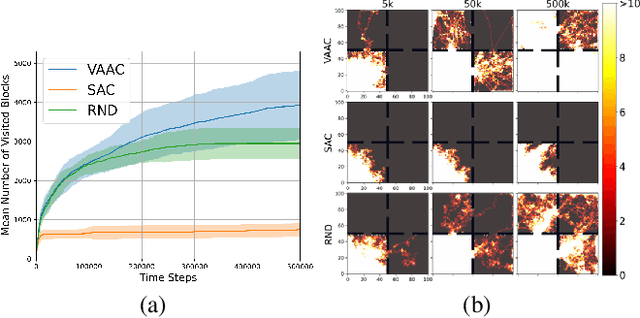
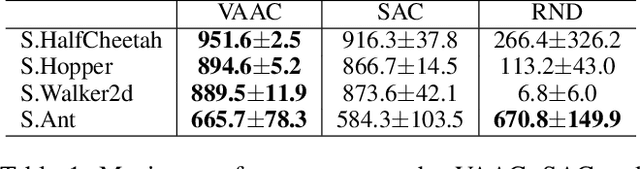
Efficient exploration for an agent is challenging in reinforcement learning (RL). In this paper, a novel actor-critic framework namely virtual action actor-critic (VAAC), is proposed to address the challenge of efficient exploration in RL. This work is inspired by humans' ability to imagine the potential outcomes of their actions without actually taking them. In order to emulate this ability, VAAC introduces a new actor called virtual actor (VA), alongside the conventional actor-critic framework. Unlike the conventional actor, the VA takes the virtual action to anticipate the next state without interacting with the environment. With the virtual policy following a Gaussian distribution, the VA is trained to maximize the anticipated novelty of the subsequent state resulting from a virtual action. If any next state resulting from available actions does not exhibit high anticipated novelty, training the VA leads to an increase in the virtual policy entropy. Hence, high virtual policy entropy represents that there is no room for exploration. The proposed VAAC aims to maximize a modified Q function, which combines cumulative rewards and the negative sum of virtual policy entropy. Experimental results show that the VAAC improves the exploration performance compared to existing algorithms.
Enhanced Transformer Architecture for Natural Language Processing
Oct 17, 2023



Transformer is a state-of-the-art model in the field of natural language processing (NLP). Current NLP models primarily increase the number of transformers to improve processing performance. However, this technique requires a lot of training resources such as computing capacity. In this paper, a novel structure of Transformer is proposed. It is featured by full layer normalization, weighted residual connection, positional encoding exploiting reinforcement learning, and zero masked self-attention. The proposed Transformer model, which is called Enhanced Transformer, is validated by the bilingual evaluation understudy (BLEU) score obtained with the Multi30k translation dataset. As a result, the Enhanced Transformer achieves 202.96% higher BLEU score as compared to the original transformer with the translation dataset.
Sensor Fusion by Spatial Encoding for Autonomous Driving
Aug 17, 2023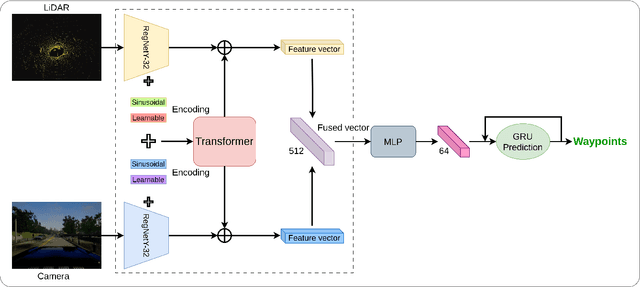

Sensor fusion is critical to perception systems for task domains such as autonomous driving and robotics. Recently, the Transformer integrated with CNN has demonstrated high performance in sensor fusion for various perception tasks. In this work, we introduce a method for fusing data from camera and LiDAR. By employing Transformer modules at multiple resolutions, proposed method effectively combines local and global contextual relationships. The performance of the proposed method is validated by extensive experiments with two adversarial benchmarks with lengthy routes and high-density traffics. The proposed method outperforms previous approaches with the most challenging benchmarks, achieving significantly higher driving and infraction scores. Compared with TransFuser, it achieves 8% and 19% improvement in driving scores for the Longest6 and Town05 Long benchmarks, respectively.
Off-Policy Reinforcement Learning with Loss Function Weighted by Temporal Difference Error
Dec 26, 2022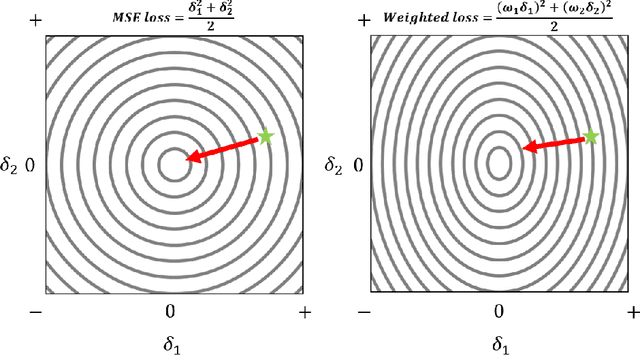
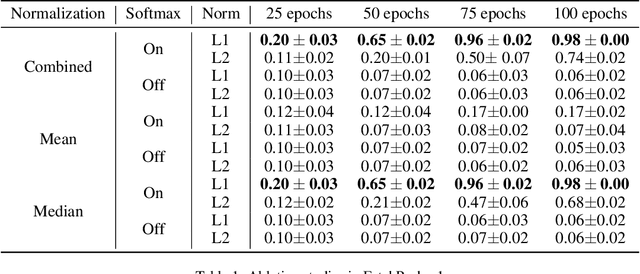
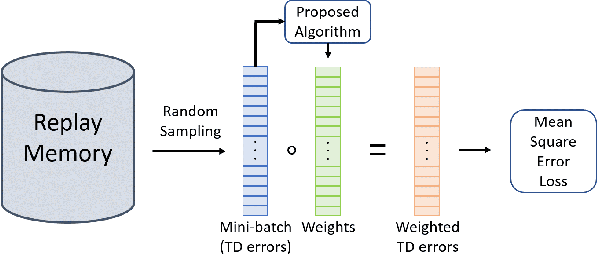
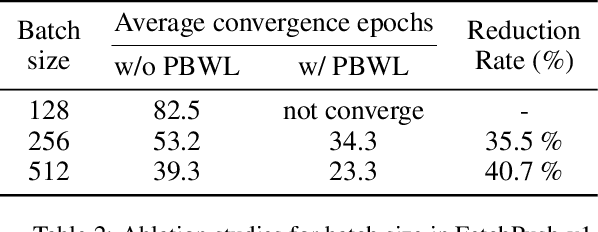
Training agents via off-policy deep reinforcement learning (RL) requires a large memory, named replay memory, that stores past experiences used for learning. These experiences are sampled, uniformly or non-uniformly, to create the batches used for training. When calculating the loss function, off-policy algorithms assume that all samples are of the same importance. In this paper, we hypothesize that training can be enhanced by assigning different importance for each experience based on their temporal-difference (TD) error directly in the training objective. We propose a novel method that introduces a weighting factor for each experience when calculating the loss function at the learning stage. In addition to improving convergence speed when used with uniform sampling, the method can be combined with prioritization methods for non-uniform sampling. Combining the proposed method with prioritization methods improves sampling efficiency while increasing the performance of TD-based off-policy RL algorithms. The effectiveness of the proposed method is demonstrated by experiments in six environments of the OpenAI Gym suite. The experimental results demonstrate that the proposed method achieves a 33%~76% reduction of convergence speed in three environments and an 11% increase in returns and a 3%~10% increase in success rate for other three environments.
Kick-motion Training with DQN in AI Soccer Environment
Dec 01, 2022



This paper presents a technique to train a robot to perform kick-motion in AI soccer by using reinforcement learning (RL). In RL, an agent interacts with an environment and learns to choose an action in a state at each step. When training RL algorithms, a problem called the curse of dimensionality (COD) can occur if the dimension of the state is high and the number of training data is low. The COD often causes degraded performance of RL models. In the situation of the robot kicking the ball, as the ball approaches the robot, the robot chooses the action based on the information obtained from the soccer field. In order not to suffer COD, the training data, which are experiences in the case of RL, should be collected evenly from all areas of the soccer field over (theoretically infinite) time. In this paper, we attempt to use the relative coordinate system (RCS) as the state for training kick-motion of robot agent, instead of using the absolute coordinate system (ACS). Using the RCS eliminates the necessity for the agent to know all the (state) information of entire soccer field and reduces the dimension of the state that the agent needs to know to perform kick-motion, and consequently alleviates COD. The training based on the RCS is performed with the widely used Deep Q-network (DQN) and tested in the AI Soccer environment implemented with Webots simulation software.
Path Planning of Cleaning Robot with Reinforcement Learning
Aug 17, 2022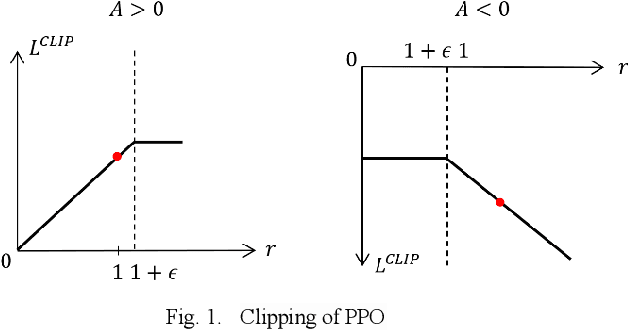
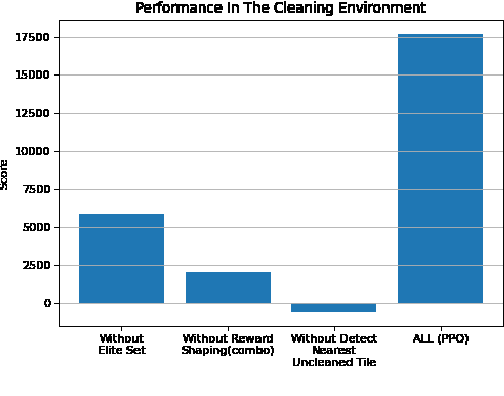
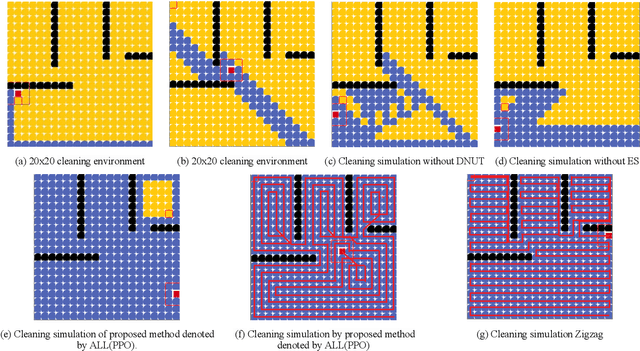
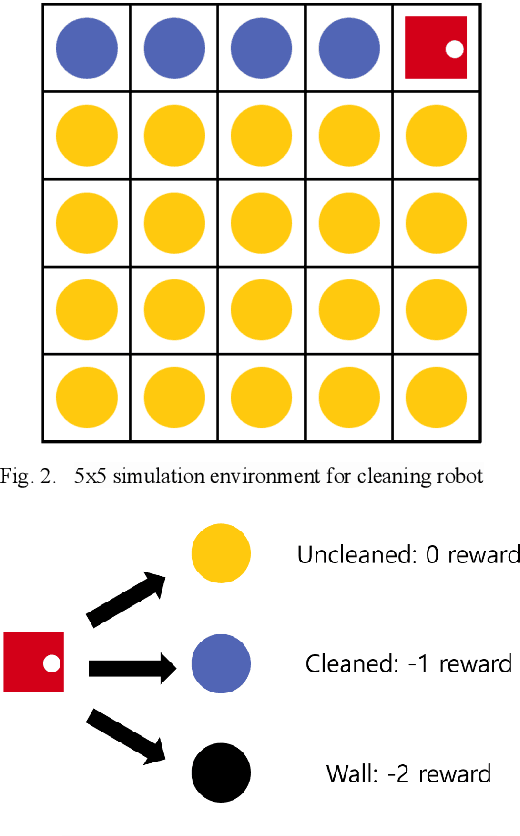
Recently, as the demand for cleaning robots has steadily increased, therefore household electricity consumption is also increasing. To solve this electricity consumption issue, the problem of efficient path planning for cleaning robot has become important and many studies have been conducted. However, most of them are about moving along a simple path segment, not about the whole path to clean all places. As the emerging deep learning technique, reinforcement learning (RL) has been adopted for cleaning robot. However, the models for RL operate only in a specific cleaning environment, not the various cleaning environment. The problem is that the models have to retrain whenever the cleaning environment changes. To solve this problem, the proximal policy optimization (PPO) algorithm is combined with an efficient path planning that operates in various cleaning environments, using transfer learning (TL), detection nearest cleaned tile, reward shaping, and making elite set methods. The proposed method is validated with an ablation study and comparison with conventional methods such as random and zigzag. The experimental results demonstrate that the proposed method achieves improved training performance and increased convergence speed over the original PPO. And it also demonstrates that this proposed method is better performance than conventional methods (random, zigzag).