 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Transformer Architecture for Natural Language Processing
Oct 17, 2023



Transformer is a state-of-the-art model in the field of natural language processing (NLP). Current NLP models primarily increase the number of transformers to improve processing performance. However, this technique requires a lot of training resources such as computing capacity. In this paper, a novel structure of Transformer is proposed. It is featured by full layer normalization, weighted residual connection, positional encoding exploiting reinforcement learning, and zero masked self-attention. The proposed Transformer model, which is called Enhanced Transformer, is validated by the bilingual evaluation understudy (BLEU) score obtained with the Multi30k translation dataset. As a result, the Enhanced Transformer achieves 202.96% higher BLEU score as compared to the original transformer with the translation dataset.
Off-Policy Reinforcement Learning with Loss Function Weighted by Temporal Difference Error
Dec 26, 2022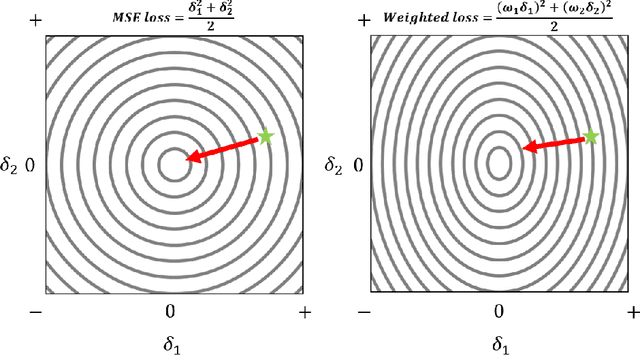
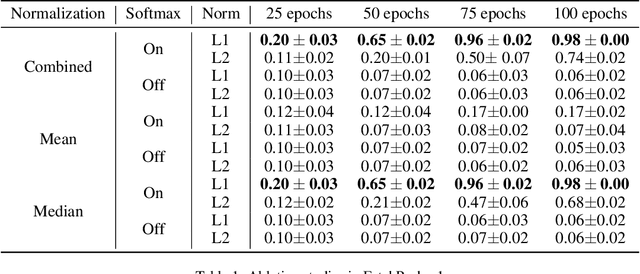
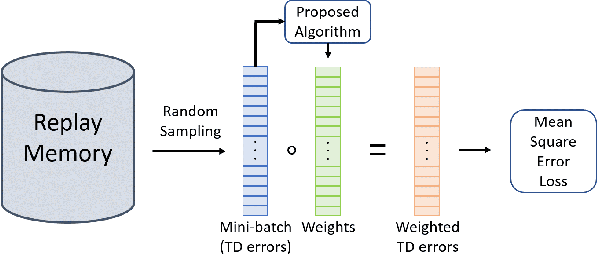
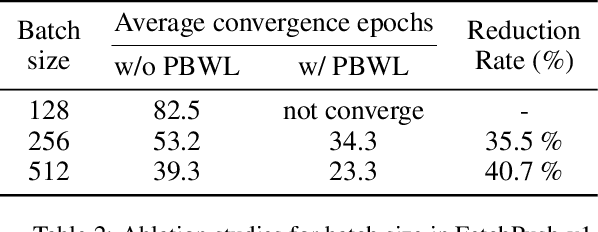
Training agents via off-policy deep reinforcement learning (RL) requires a large memory, named replay memory, that stores past experiences used for learning. These experiences are sampled, uniformly or non-uniformly, to create the batches used for training. When calculating the loss function, off-policy algorithms assume that all samples are of the same importance. In this paper, we hypothesize that training can be enhanced by assigning different importance for each experience based on their temporal-difference (TD) error directly in the training objective. We propose a novel method that introduces a weighting factor for each experience when calculating the loss function at the learning stage. In addition to improving convergence speed when used with uniform sampling, the method can be combined with prioritization methods for non-uniform sampling. Combining the proposed method with prioritization methods improves sampling efficiency while increasing the performance of TD-based off-policy RL algorithms. The effectiveness of the proposed method is demonstrated by experiments in six environments of the OpenAI Gym suite. The experimental results demonstrate that the proposed method achieves a 33%~76% reduction of convergence speed in three environments and an 11% increase in returns and a 3%~10% increase in success rate for other three environments.
Path Planning of Cleaning Robot with Reinforcement Learning
Aug 17, 2022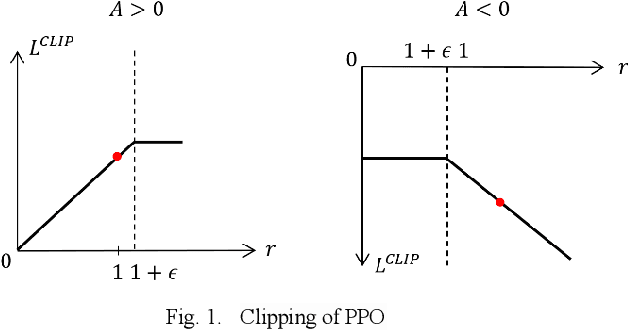
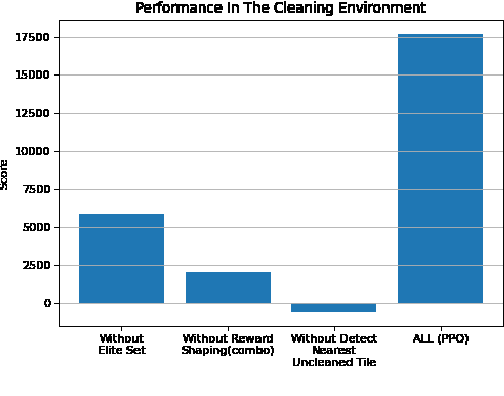
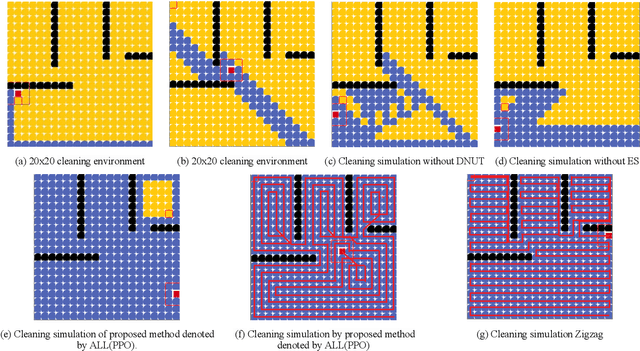
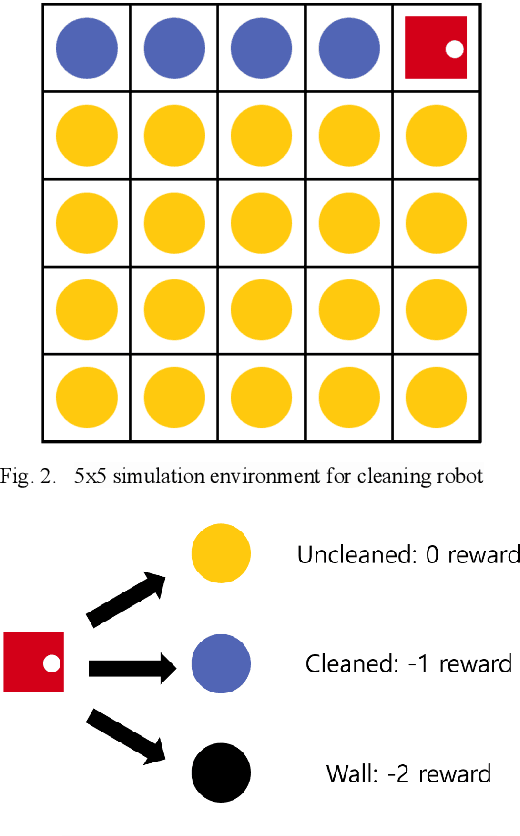
Recently, as the demand for cleaning robots has steadily increased, therefore household electricity consumption is also increasing. To solve this electricity consumption issue, the problem of efficient path planning for cleaning robot has become important and many studies have been conducted. However, most of them are about moving along a simple path segment, not about the whole path to clean all places. As the emerging deep learning technique, reinforcement learning (RL) has been adopted for cleaning robot. However, the models for RL operate only in a specific cleaning environment, not the various cleaning environment. The problem is that the models have to retrain whenever the cleaning environment changes. To solve this problem, the proximal policy optimization (PPO) algorithm is combined with an efficient path planning that operates in various cleaning environments, using transfer learning (TL), detection nearest cleaned tile, reward shaping, and making elite set methods. The proposed method is validated with an ablation study and comparison with conventional methods such as random and zigzag. The experimental results demonstrate that the proposed method achieves improved training performance and increased convergence speed over the original PPO. And it also demonstrates that this proposed method is better performance than conventional methods (random, zigzag).