 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirtual Action Actor-Critic Framework for Exploration (Student Abstract)
Paper and Code
Nov 06, 2023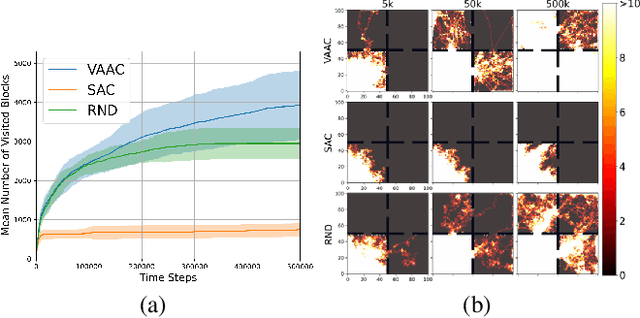
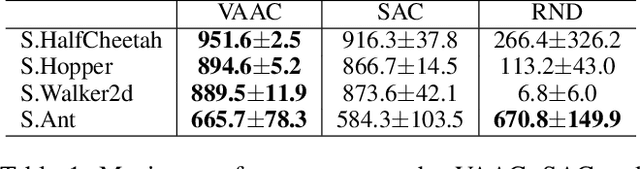
Efficient exploration for an agent is challenging in reinforcement learning (RL). In this paper, a novel actor-critic framework namely virtual action actor-critic (VAAC), is proposed to address the challenge of efficient exploration in RL. This work is inspired by humans' ability to imagine the potential outcomes of their actions without actually taking them. In order to emulate this ability, VAAC introduces a new actor called virtual actor (VA), alongside the conventional actor-critic framework. Unlike the conventional actor, the VA takes the virtual action to anticipate the next state without interacting with the environment. With the virtual policy following a Gaussian distribution, the VA is trained to maximize the anticipated novelty of the subsequent state resulting from a virtual action. If any next state resulting from available actions does not exhibit high anticipated novelty, training the VA leads to an increase in the virtual policy entropy. Hence, high virtual policy entropy represents that there is no room for exploration. The proposed VAAC aims to maximize a modified Q function, which combines cumulative rewards and the negative sum of virtual policy entropy. Experimental results show that the VAAC improves the exploration performance compared to existing algorithms.