 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseViNet: Distracted Driver Action Recognition Framework Using Multi-View Pose Estimation and Vision Transformer
Dec 22, 2023Driver distraction is a principal cause of traffic accidents. In a study conducted by the National Highway Traffic Safety Administration, engaging in activities such as interacting with in-car menus, consuming food or beverages, or engaging in telephonic conversations while operating a vehicle can be significant sources of driver distraction. From this viewpoint, this paper introduces a novel method for detection of driver distraction using multi-view driver action images. The proposed method is a vision transformer-based framework with pose estimation and action inference, namely PoseViNet. The motivation for adding posture information is to enable the transformer to focus more on key features. As a result, the framework is more adept at identifying critical actions. The proposed framework is compared with various state-of-the-art models using SFD3 dataset representing 10 behaviors of drivers. It is found from the comparison that the PoseViNet outperforms these models. The proposed framework is also evaluated with the SynDD1 dataset representing 16 behaviors of driver. As a result, the PoseViNet achieves 97.55% validation accuracy and 90.92% testing accuracy with the challenging dataset.
Sensor Fusion by Spatial Encoding for Autonomous Driving
Aug 17, 2023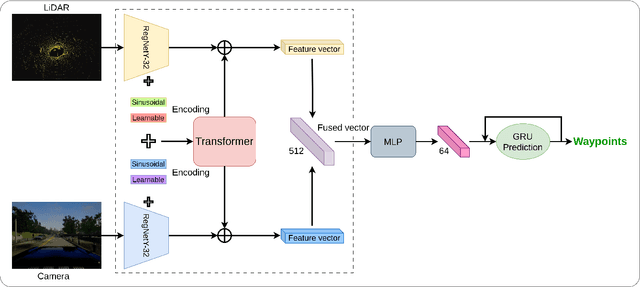

Sensor fusion is critical to perception systems for task domains such as autonomous driving and robotics. Recently, the Transformer integrated with CNN has demonstrated high performance in sensor fusion for various perception tasks. In this work, we introduce a method for fusing data from camera and LiDAR. By employing Transformer modules at multiple resolutions, proposed method effectively combines local and global contextual relationships. The performance of the proposed method is validated by extensive experiments with two adversarial benchmarks with lengthy routes and high-density traffics. The proposed method outperforms previous approaches with the most challenging benchmarks, achieving significantly higher driving and infraction scores. Compared with TransFuser, it achieves 8% and 19% improvement in driving scores for the Longest6 and Town05 Long benchmarks, respectively.
Kick-motion Training with DQN in AI Soccer Environment
Dec 01, 2022



This paper presents a technique to train a robot to perform kick-motion in AI soccer by using reinforcement learning (RL). In RL, an agent interacts with an environment and learns to choose an action in a state at each step. When training RL algorithms, a problem called the curse of dimensionality (COD) can occur if the dimension of the state is high and the number of training data is low. The COD often causes degraded performance of RL models. In the situation of the robot kicking the ball, as the ball approaches the robot, the robot chooses the action based on the information obtained from the soccer field. In order not to suffer COD, the training data, which are experiences in the case of RL, should be collected evenly from all areas of the soccer field over (theoretically infinite) time. In this paper, we attempt to use the relative coordinate system (RCS) as the state for training kick-motion of robot agent, instead of using the absolute coordinate system (ACS). Using the RCS eliminates the necessity for the agent to know all the (state) information of entire soccer field and reduces the dimension of the state that the agent needs to know to perform kick-motion, and consequently alleviates COD. The training based on the RCS is performed with the widely used Deep Q-network (DQN) and tested in the AI Soccer environment implemented with Webots simulation software.
Interpretable Network Representation Learning with Principal Component Analysis
Jun 27, 2021
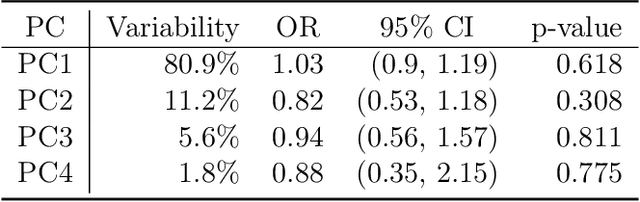

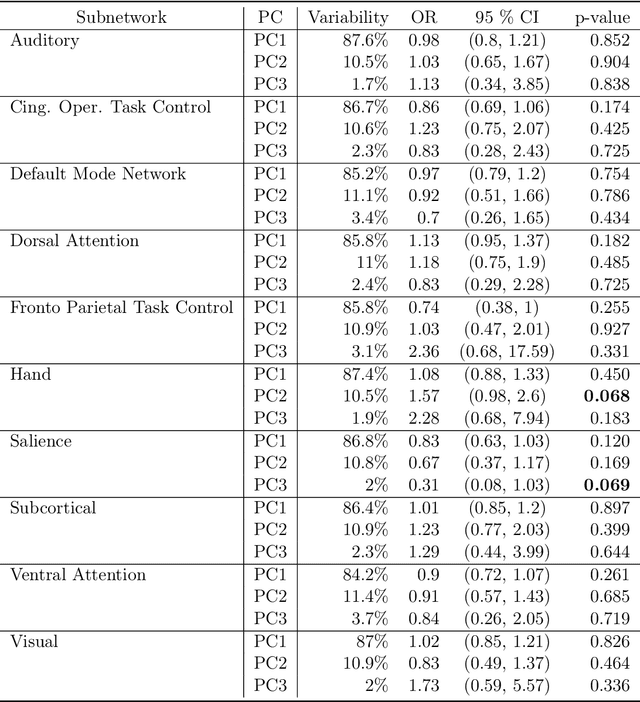
We consider the problem of interpretable network representation learning for samples of network-valued data. We propose the Principal Component Analysis for Networks (PCAN) algorithm to identify statistically meaningful low-dimensional representations of a network sample via subgraph count statistics. The PCAN procedure provides an interpretable framework for which one can readily visualize, explore, and formulate predictive models for network samples. We furthermore introduce a fast sampling-based algorithm, sPCAN, which is significantly more computationally efficient than its counterpart, but still enjoys advantages of interpretability. We investigate the relationship between these two methods and analyze their large-sample properties under the common regime where the sample of networks is a collection of kernel-based random graphs. We show that under this regime, the embeddings of the sPCAN method enjoy a central limit theorem and moreover that the population level embeddings of PCAN and sPCAN are equivalent. We assess PCAN's ability to visualize, cluster, and classify observations in network samples arising in nature, including functional connectivity network samples and dynamic networks describing the political co-voting habits of the U.S. Senate. Our analyses reveal that our proposed algorithm provides informative and discriminatory features describing the networks in each sample. The PCAN and sPCAN methods build on the current literature of network representation learning and set the stage for a new line of research in interpretable learning on network-valued data. Publicly available software for the PCAN and sPCAN methods are available at https://www.github.com/jihuilee/.