 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Network Representation Learning with Principal Component Analysis
Jun 27, 2021
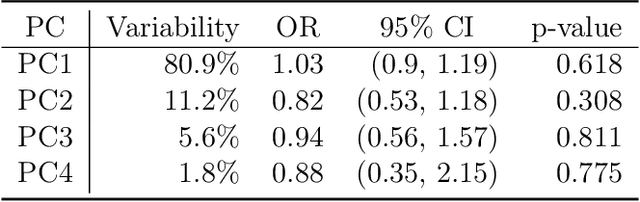

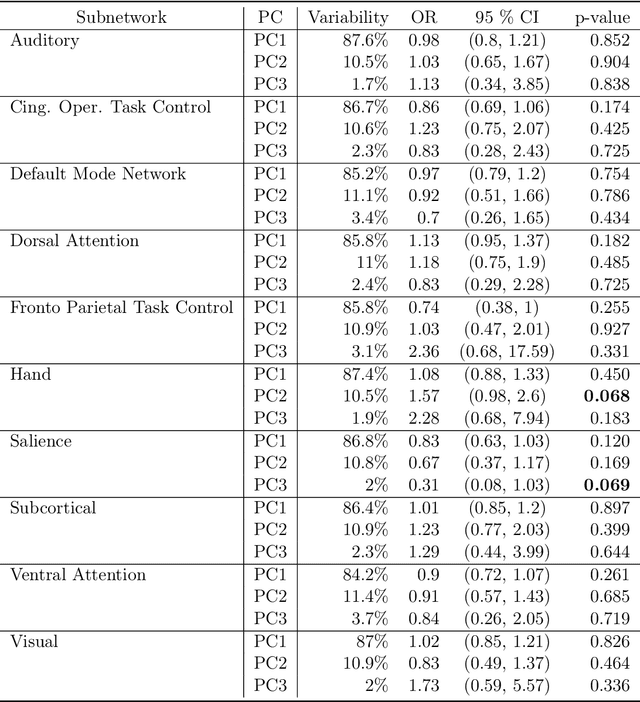
We consider the problem of interpretable network representation learning for samples of network-valued data. We propose the Principal Component Analysis for Networks (PCAN) algorithm to identify statistically meaningful low-dimensional representations of a network sample via subgraph count statistics. The PCAN procedure provides an interpretable framework for which one can readily visualize, explore, and formulate predictive models for network samples. We furthermore introduce a fast sampling-based algorithm, sPCAN, which is significantly more computationally efficient than its counterpart, but still enjoys advantages of interpretability. We investigate the relationship between these two methods and analyze their large-sample properties under the common regime where the sample of networks is a collection of kernel-based random graphs. We show that under this regime, the embeddings of the sPCAN method enjoy a central limit theorem and moreover that the population level embeddings of PCAN and sPCAN are equivalent. We assess PCAN's ability to visualize, cluster, and classify observations in network samples arising in nature, including functional connectivity network samples and dynamic networks describing the political co-voting habits of the U.S. Senate. Our analyses reveal that our proposed algorithm provides informative and discriminatory features describing the networks in each sample. The PCAN and sPCAN methods build on the current literature of network representation learning and set the stage for a new line of research in interpretable learning on network-valued data. Publicly available software for the PCAN and sPCAN methods are available at https://www.github.com/jihuilee/.
Nonparametric Feature Impact and Importance
Jun 08, 2020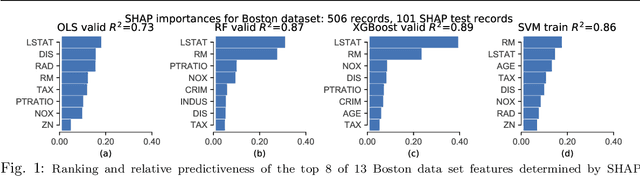

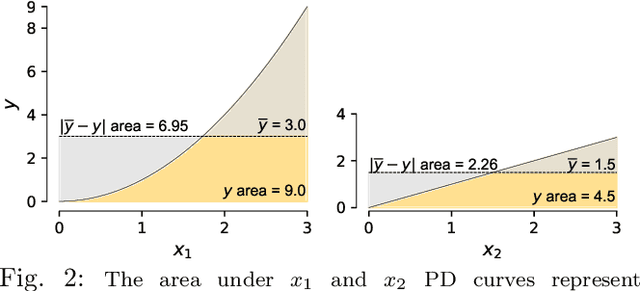
Practitioners use feature importance to rank and eliminate weak predictors during model development in an effort to simplify models and improve generality. Unfortunately, they also routinely conflate such feature importance measures with feature impact, the isolated effect of an explanatory variable on the response variable. This can lead to real-world consequences when importance is inappropriately interpreted as impact for business or medical insight purposes. The dominant approach for computing importances is through interrogation of a fitted model, which works well for feature selection, but gives distorted measures of feature impact. The same method applied to the same data set can yield different feature importances, depending on the model, leading us to conclude that impact should be computed directly from the data. While there are nonparametric feature selection algorithms, they typically provide feature rankings, rather than measures of impact or importance. They also typically focus on single-variable associations with the response. In this paper, we give mathematical definitions of feature impact and importance, derived from partial dependence curves, that operate directly on the data. To assess quality, we show that features ranked by these definitions are competitive with existing feature selection techniques using three real data sets for predictive tasks.
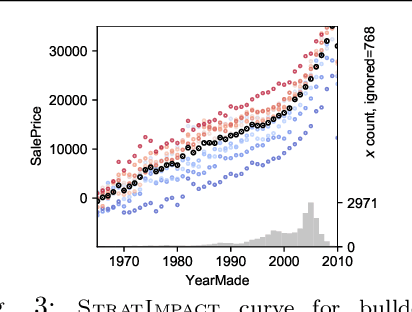
A Stratification Approach to Partial Dependence for Codependent Variables
Jul 15, 2019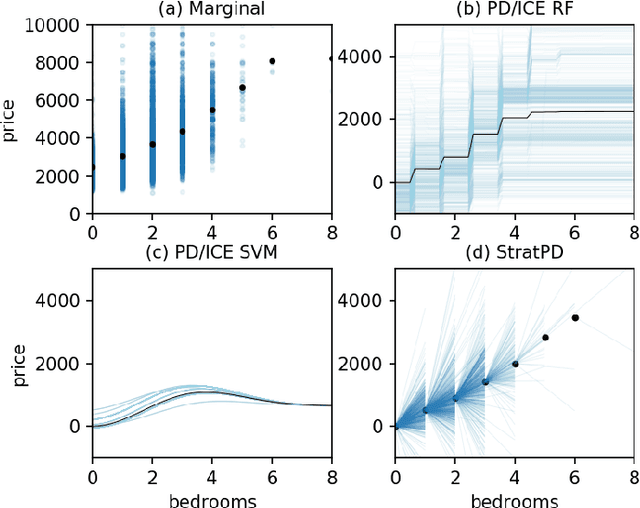

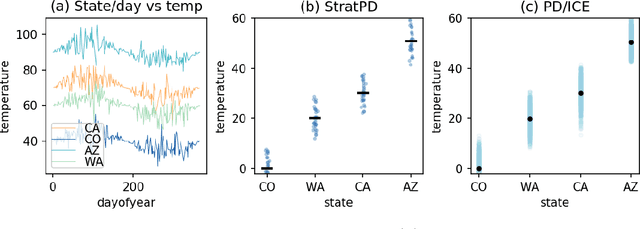
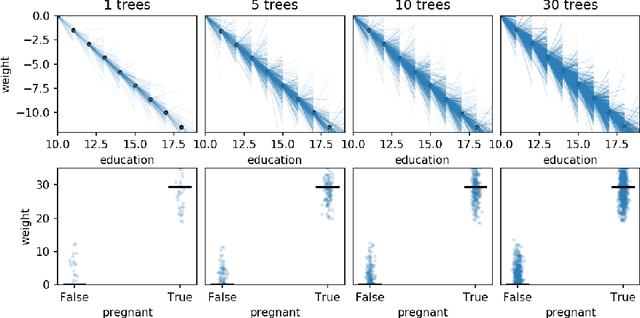
Model interpretability is important to machine learning practitioners, and a key component of interpretation is the characterization of partial dependence of the response variable on any subset of features used in the model. The two most common strategies for assessing partial dependence suffer from a number of critical weaknesses. In the first strategy, linear regression model coefficients describe how a unit change in an explanatory variable changes the response, while holding other variables constant. But, linear regression is inapplicable for high dimensional (p>n) data sets and is often insufficient to capture the relationship between explanatory variables and the response. In the second strategy, Partial Dependence (PD) plots and Individual Conditional Expectation (ICE) plots give biased results for the common situation of codependent variables and they rely on fitted models provided by the user. When the supplied model is a poor choice due to systematic bias or overfitting, PD/ICE plots provide little (if any) useful information. To address these issues, we introduce a new strategy, called StratPD, that does not depend on a user's fitted model, provides accurate results in the presence codependent variables, and is applicable to high dimensional settings. The strategy works by stratifying a data set into groups of observations that are similar, except in the variable of interest, through the use of a decision tree. Any fluctuations of the response variable within a group is likely due to the variable of interest. We apply StratPD to a collection of simulations and case studies to show that StratPD is a fast, reliable, and robust method for assessing partial dependence with clear advantages over state-of-the-art methods.
Topic supervised non-negative matrix factorization
Jul 02, 2017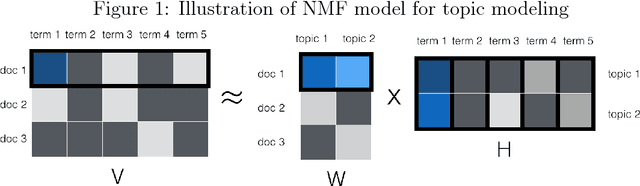
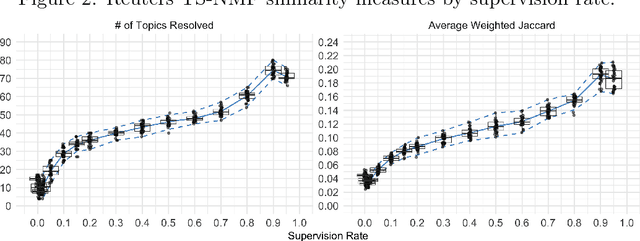
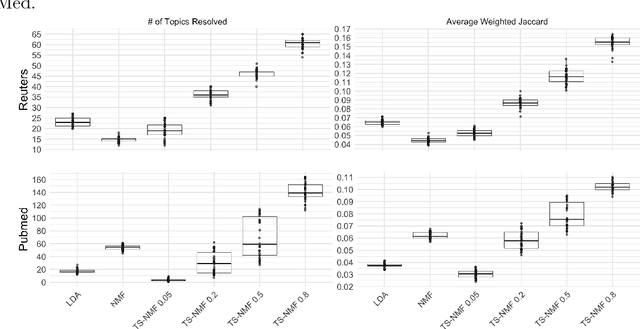
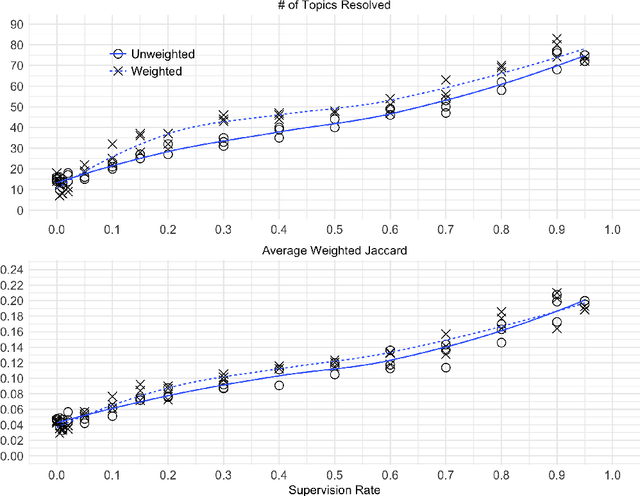
Topic models have been extensively used to organize and interpret the contents of large, unstructured corpora of text documents. Although topic models often perform well on traditional training vs. test set evaluations, it is often the case that the results of a topic model do not align with human interpretation. This interpretability fallacy is largely due to the unsupervised nature of topic models, which prohibits any user guidance on the results of a model. In this paper, we introduce a semi-supervised method called topic supervised non-negative matrix factorization (TS-NMF) that enables the user to provide labeled example documents to promote the discovery of more meaningful semantic structure of a corpus. In this way, the results of TS-NMF better match the intuition and desired labeling of the user. The core of TS-NMF relies on solving a non-convex optimization problem for which we derive an iterative algorithm that is shown to be monotonic and convergent to a local optimum. We demonstrate the practical utility of TS-NMF on the Reuters and PubMed corpora, and find that TS-NMF is especially useful for conceptual or broad topics, where topic key terms are not well understood. Although identifying an optimal latent structure for the data is not a primary objective of the proposed approach, we find that TS-NMF achieves higher weighted Jaccard similarity scores than the contemporary methods, (unsupervised) NMF and latent Dirichlet allocation, at supervision rates as low as 10% to 20%.