 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopic supervised non-negative matrix factorization
Paper and Code
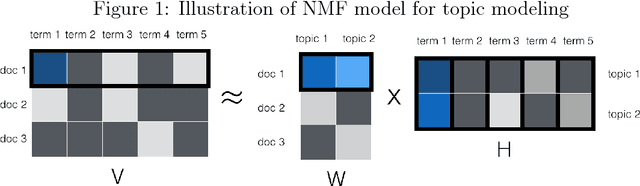
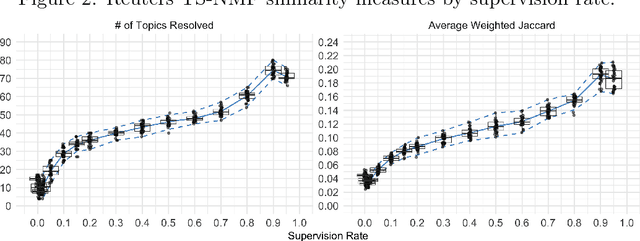
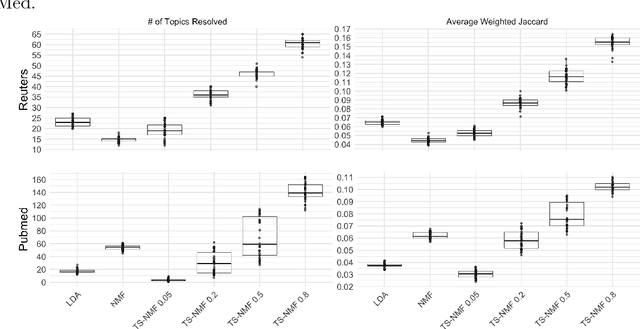
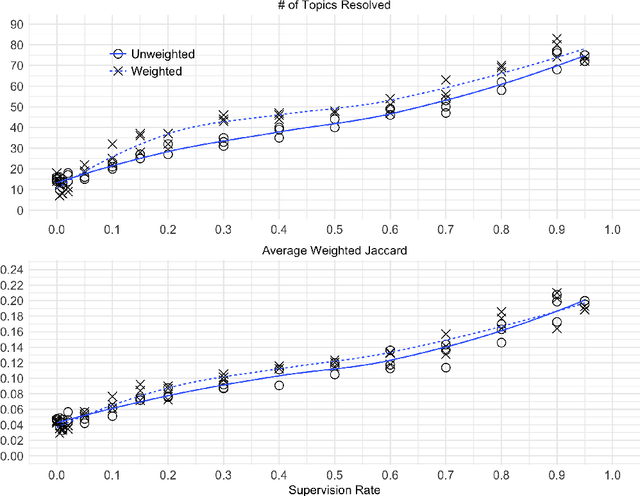
Topic models have been extensively used to organize and interpret the contents of large, unstructured corpora of text documents. Although topic models often perform well on traditional training vs. test set evaluations, it is often the case that the results of a topic model do not align with human interpretation. This interpretability fallacy is largely due to the unsupervised nature of topic models, which prohibits any user guidance on the results of a model. In this paper, we introduce a semi-supervised method called topic supervised non-negative matrix factorization (TS-NMF) that enables the user to provide labeled example documents to promote the discovery of more meaningful semantic structure of a corpus. In this way, the results of TS-NMF better match the intuition and desired labeling of the user. The core of TS-NMF relies on solving a non-convex optimization problem for which we derive an iterative algorithm that is shown to be monotonic and convergent to a local optimum. We demonstrate the practical utility of TS-NMF on the Reuters and PubMed corpora, and find that TS-NMF is especially useful for conceptual or broad topics, where topic key terms are not well understood. Although identifying an optimal latent structure for the data is not a primary objective of the proposed approach, we find that TS-NMF achieves higher weighted Jaccard similarity scores than the contemporary methods, (unsupervised) NMF and latent Dirichlet allocation, at supervision rates as low as 10% to 20%.