 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Far Can Camels Go? Exploring the State of Instruction Tuning on Open Resources
Jun 07, 2023In this work we explore recent advances in instruction-tuning language models on a range of open instruction-following datasets. Despite recent claims that open models can be on par with state-of-the-art proprietary models, these claims are often accompanied by limited evaluation, making it difficult to compare models across the board and determine the utility of various resources. We provide a large set of instruction-tuned models from 6.7B to 65B parameters in size, trained on 12 instruction datasets ranging from manually curated (e.g., OpenAssistant) to synthetic and distilled (e.g., Alpaca) and systematically evaluate them on their factual knowledge, reasoning, multilinguality, coding, and open-ended instruction following abilities through a collection of automatic, model-based, and human-based metrics. We further introduce T\"ulu, our best performing instruction-tuned model suite finetuned on a combination of high-quality open resources. Our experiments show that different instruction-tuning datasets can uncover or enhance specific skills, while no single dataset (or combination) provides the best performance across all evaluations. Interestingly, we find that model and human preference-based evaluations fail to reflect differences in model capabilities exposed by benchmark-based evaluations, suggesting the need for the type of systemic evaluation performed in this work. Our evaluations show that the best model in any given evaluation reaches on average 83% of ChatGPT performance, and 68% of GPT-4 performance, suggesting that further investment in building better base models and instruction-tuning data is required to close the gap. We release our instruction-tuned models, including a fully finetuned 65B T\"ulu, along with our code, data, and evaluation framework at https://github.com/allenai/open-instruct to facilitate future research.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
The Semantic Scholar Open Data Platform
Jan 24, 2023



The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.
Topic supervised non-negative matrix factorization
Jul 02, 2017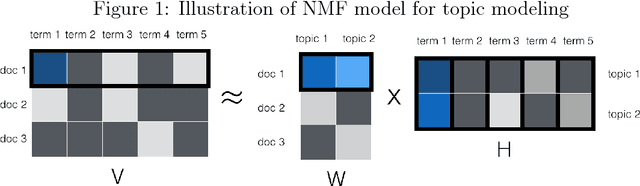
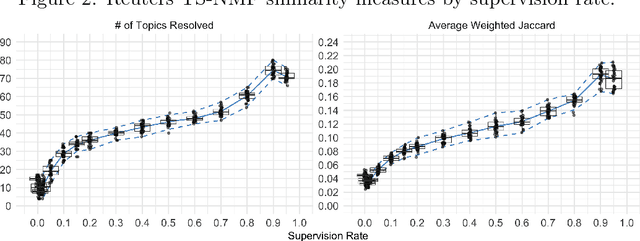
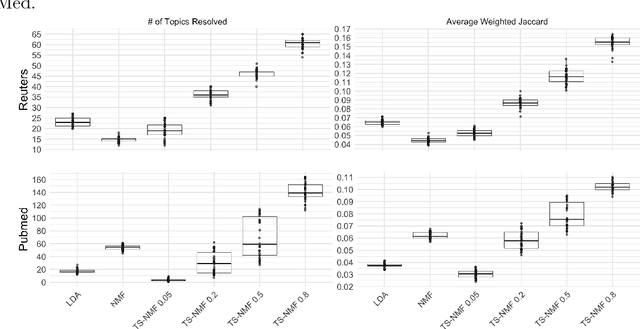
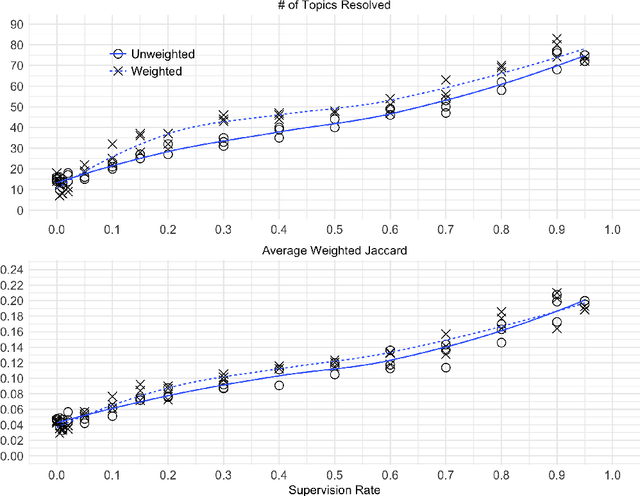
Topic models have been extensively used to organize and interpret the contents of large, unstructured corpora of text documents. Although topic models often perform well on traditional training vs. test set evaluations, it is often the case that the results of a topic model do not align with human interpretation. This interpretability fallacy is largely due to the unsupervised nature of topic models, which prohibits any user guidance on the results of a model. In this paper, we introduce a semi-supervised method called topic supervised non-negative matrix factorization (TS-NMF) that enables the user to provide labeled example documents to promote the discovery of more meaningful semantic structure of a corpus. In this way, the results of TS-NMF better match the intuition and desired labeling of the user. The core of TS-NMF relies on solving a non-convex optimization problem for which we derive an iterative algorithm that is shown to be monotonic and convergent to a local optimum. We demonstrate the practical utility of TS-NMF on the Reuters and PubMed corpora, and find that TS-NMF is especially useful for conceptual or broad topics, where topic key terms are not well understood. Although identifying an optimal latent structure for the data is not a primary objective of the proposed approach, we find that TS-NMF achieves higher weighted Jaccard similarity scores than the contemporary methods, (unsupervised) NMF and latent Dirichlet allocation, at supervision rates as low as 10% to 20%.