 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLMo: Accelerating the Science of Language Models
Feb 07, 2024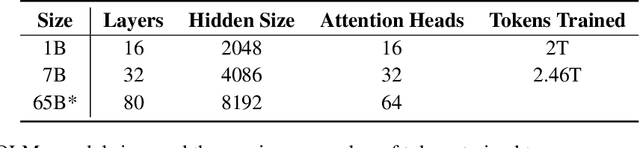
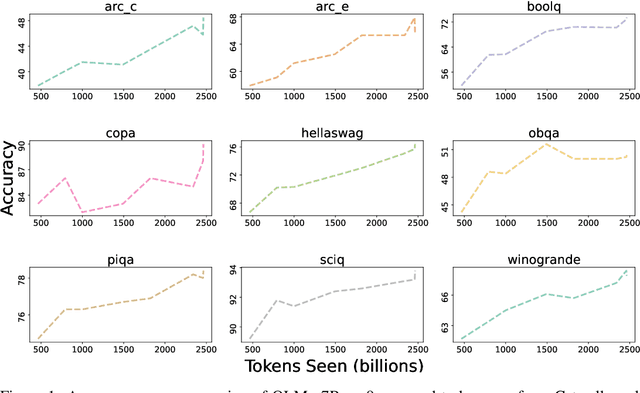
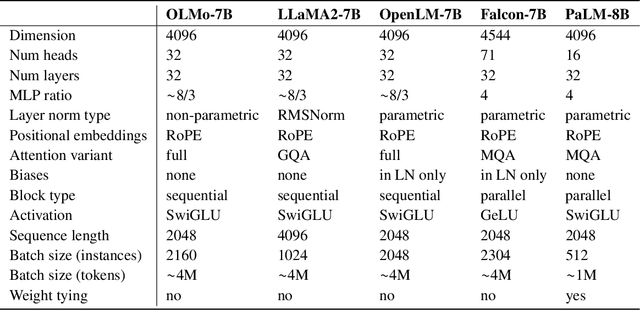
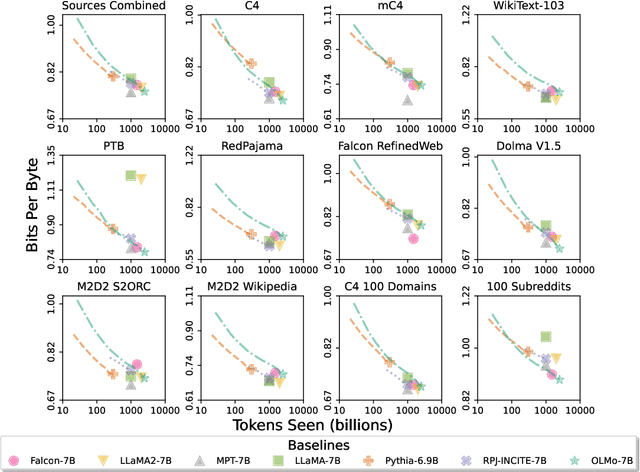
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.
Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
Jan 31, 2024



Language models have become a critical technology to tackling a wide range of natural language processing tasks, yet many details about how the best-performing language models were developed are not reported. In particular, information about their pretraining corpora is seldom discussed: commercial language models rarely provide any information about their data; even open models rarely release datasets they are trained on, or an exact recipe to reproduce them. As a result, it is challenging to conduct certain threads of language modeling research, such as understanding how training data impacts model capabilities and shapes their limitations. To facilitate open research on language model pretraining, we release Dolma, a three trillion tokens English corpus, built from a diverse mixture of web content, scientific papers, code, public-domain books, social media, and encyclopedic materials. In addition, we open source our data curation toolkit to enable further experimentation and reproduction of our work. In this report, we document Dolma, including its design principles, details about its construction, and a summary of its contents. We interleave this report with analyses and experimental results from training language models on intermediate states of Dolma to share what we have learned about important data curation practices, including the role of content or quality filters, deduplication, and multi-source mixing. Dolma has been used to train OLMo, a state-of-the-art, open language model and framework designed to build and study the science of language modeling.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
The Semantic Scholar Open Data Platform
Jan 24, 2023



The volume of scientific output is creating an urgent need for automated tools to help scientists keep up with developments in their field. Semantic Scholar (S2) is an open data platform and website aimed at accelerating science by helping scholars discover and understand scientific literature. We combine public and proprietary data sources using state-of-the-art techniques for scholarly PDF content extraction and automatic knowledge graph construction to build the Semantic Scholar Academic Graph, the largest open scientific literature graph to-date, with 200M+ papers, 80M+ authors, 550M+ paper-authorship edges, and 2.4B+ citation edges. The graph includes advanced semantic features such as structurally parsed text, natural language summaries, and vector embeddings. In this paper, we describe the components of the S2 data processing pipeline and the associated APIs offered by the platform. We will update this living document to reflect changes as we add new data offerings and improve existing services.