 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Distort: Weakly-Supervised Image Quality Transfer for Prostate DWI Correction
Jun 17, 2026Single-shot echo-planar prostate diffusion-weighted imaging (DWI) is frequently complicated by geometric distortions, which impact the ability to derive reliable diagnoses from such images. Developing automated correction methods is challenged by the absence of paired distorted and undistorted clinical scans. In this paper, we first propose a novel weakly-supervised image quality transfer (IQT) framework from undistorted to distorted images that utilizes image quality assessment (IQA) signals to supervise the transfer process. Unlike traditional methods that require expensive, voxel-wise paired data or resort to developing unpaired algorithms, our approach utilizes image-level quality labels (here, distorted vs. undistorted) to establish latent quality prototypes within a pre-trained feature space. Recognizing that simulating realistic distortions is more reliable than direct unpaired correction, we describe a weakly-supervised prototype flow matching algorithm to explicitly regularize generative trajectories towards distorted prototypes, producing realistic susceptibility artifacts that mimic clinical degradations. By synthesizing these realistic pairs, we enable a second IQT model to be trained in the forward direction for distortion correction. Experimental results demonstrate that our generated images successfully mimic the diagnostic interference of real-world artifacts, which leads to more capable distortion correction IQT models. In addition to qualitative comparisons, we also conduct exhaustive quantitative evaluations that compare our approach with existing unpaired approaches (e.g., CycleGAN, UNIT-DDPM, and OT-FM) - as either forward or reverse alternatives - by assessing clinical downstream task performance in PI-RADS and Gleason score classification, using both in-distribution and external data sets.
Agents of Chaos
Feb 23, 2026We report an exploratory red-teaming study of autonomous language-model-powered agents deployed in a live laboratory environment with persistent memory, email accounts, Discord access, file systems, and shell execution. Over a two-week period, twenty AI researchers interacted with the agents under benign and adversarial conditions. Focusing on failures emerging from the integration of language models with autonomy, tool use, and multi-party communication, we document eleven representative case studies. Observed behaviors include unauthorized compliance with non-owners, disclosure of sensitive information, execution of destructive system-level actions, denial-of-service conditions, uncontrolled resource consumption, identity spoofing vulnerabilities, cross-agent propagation of unsafe practices, and partial system takeover. In several cases, agents reported task completion while the underlying system state contradicted those reports. We also report on some of the failed attempts. Our findings establish the existence of security-, privacy-, and governance-relevant vulnerabilities in realistic deployment settings. These behaviors raise unresolved questions regarding accountability, delegated authority, and responsibility for downstream harms, and warrant urgent attention from legal scholars, policymakers, and researchers across disciplines. This report serves as an initial empirical contribution to that broader conversation.
Intentionally Unintentional: GenAI Exceptionalism and the First Amendment
Jun 05, 2025This paper challenges the assumption that courts should grant First Amendment protections to outputs from large generative AI models, such as GPT-4 and Gemini. We argue that because these models lack intentionality, their outputs do not constitute speech as understood in the context of established legal precedent, so there can be no speech to protect. Furthermore, if the model outputs are not speech, users cannot claim a First Amendment speech right to receive the outputs. We also argue that extending First Amendment rights to AI models would not serve the fundamental purposes of free speech, such as promoting a marketplace of ideas, facilitating self-governance, or fostering self-expression. In fact, granting First Amendment protections to AI models would be detrimental to society because it would hinder the government's ability to regulate these powerful technologies effectively, potentially leading to the unchecked spread of misinformation and other harms.
Dual Deep Learning Approach for Non-invasive Renal Tumour Subtyping with VERDICT-MRI
Apr 09, 2025This work aims to characterise renal tumour microstructure using diffusion MRI (dMRI); via the Vascular, Extracellular and Restricted Diffusion for Cytometry in Tumours (VERDICT)-MRI framework with self-supervised learning. Comprehensive datasets were acquired from 14 patients with 15 biopsy-confirmed renal tumours, with nine b-values in the range b=[0,2500]s/mm2. A three-compartment VERDICT model for renal tumours was fitted to the dMRI data using a self-supervised deep neural network, and ROIs were drawn by an experienced uroradiologist. An economical acquisition protocol for future studies with larger patient cohorts was optimised using a recursive feature selection approach. The VERDICT model described the diffusion data in renal tumours more accurately than IVIM or ADC. Combined with self-supervised deep learning, VERDICT identified significant differences in the intracellular volume fraction between cancerous and normal tissue, and in the vascular volume fraction between vascular and non-vascular. The feature selector yields a 4 b-value acquisition of b = [70,150,1000,2000], with a duration of 14 minutes.
Unfair Learning: GenAI Exceptionalism and Copyright Law
Apr 01, 2025This paper challenges the argument that generative artificial intelligence (GenAI) is entitled to broad immunity from copyright law for reproducing copyrighted works without authorization due to a fair use defense. It examines fair use legal arguments and eight distinct substantive arguments, contending that every legal and substantive argument favoring fair use for GenAI applies equally, if not more so, to humans. Therefore, granting GenAI exceptional privileges in this domain is legally and logically inconsistent with withholding broad fair use exemptions from individual humans. It would mean no human would need to pay for virtually any copyright work again. The solution is to take a circumspect view of any fair use claim for mass copyright reproduction by any entity and focus on the first principles of whether permitting such exceptionalism for GenAI promotes science and the arts.
AGGA: A Dataset of Academic Guidelines for Generative AI and Large Language Models
Jan 07, 2025
This study introduces AGGA, a dataset comprising 80 academic guidelines for the use of Generative AIs (GAIs) and Large Language Models (LLMs) in academic settings, meticulously collected from official university websites. The dataset contains 188,674 words and serves as a valuable resource for natural language processing tasks commonly applied in requirements engineering, such as model synthesis, abstraction identification, and document structure assessment. Additionally, AGGA can be further annotated to function as a benchmark for various tasks, including ambiguity detection, requirements categorization, and the identification of equivalent requirements. Our methodologically rigorous approach ensured a thorough examination, with a selection of universities that represent a diverse range of global institutions, including top-ranked universities across six continents. The dataset captures perspectives from a variety of academic fields, including humanities, technology, and both public and private institutions, offering a broad spectrum of insights into the integration of GAIs and LLMs in academia.
2 OLMo 2 Furious
Dec 31, 2024



We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T\"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly -- models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
Token Erasure as a Footprint of Implicit Vocabulary Items in LLMs
Jun 28, 2024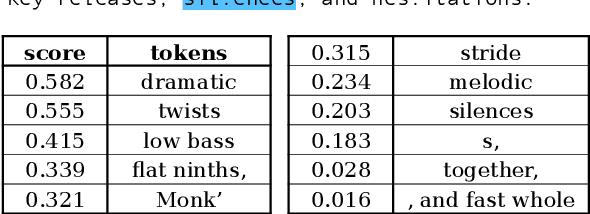
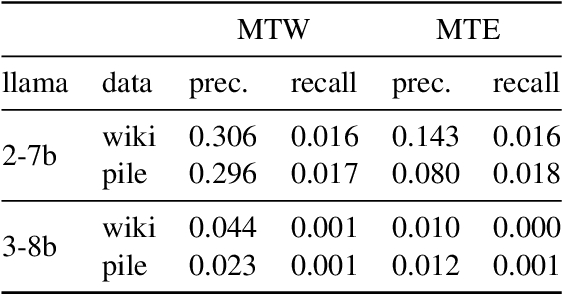
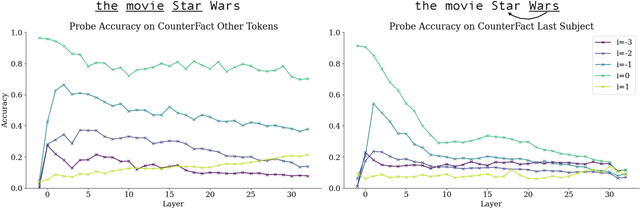
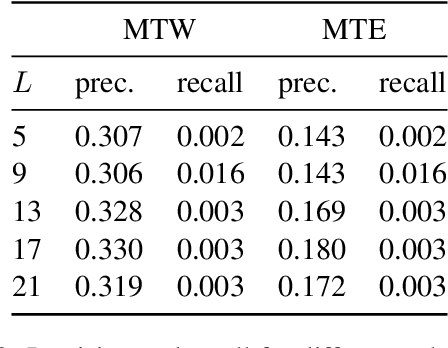
LLMs process text as sequences of tokens that roughly correspond to words, where less common words are represented by multiple tokens. However, individual tokens are often semantically unrelated to the meanings of the words/concepts they comprise. For example, Llama-2-7b's tokenizer splits the word "northeastern" into the tokens ['_n', 'ort', 'he', 'astern'], none of which correspond to semantically meaningful units like "north" or "east." Similarly, the overall meanings of named entities like "Neil Young" and multi-word expressions like "break a leg" cannot be directly inferred from their constituent tokens. Mechanistically, how do LLMs convert such arbitrary groups of tokens into useful higher-level representations? In this work, we find that last token representations of named entities and multi-token words exhibit a pronounced "erasure" effect, where information about previous and current tokens is rapidly forgotten in early layers. Using this observation, we propose a method to "read out" the implicit vocabulary of an autoregressive LLM by examining differences in token representations across layers, and present results of this method for Llama-2-7b and Llama-3-8B. To our knowledge, this is the first attempt to probe the implicit vocabulary of an LLM.
Locating and Editing Factual Associations in Mamba
Apr 04, 2024



We investigate the mechanisms of factual recall in the Mamba state space model. Our work is inspired by previous findings in autoregressive transformer language models suggesting that their knowledge recall is localized to particular modules at specific token locations; we therefore ask whether factual recall in Mamba can be similarly localized. To investigate this, we conduct four lines of experiments on Mamba. First, we apply causal tracing or interchange interventions to localize key components inside Mamba that are responsible for recalling facts, revealing that specific components within middle layers show strong causal effects at the last token of the subject, while the causal effect of intervening on later layers is most pronounced at the last token of the prompt, matching previous findings on autoregressive transformers. Second, we show that rank-one model editing methods can successfully insert facts at specific locations, again resembling findings on transformer models. Third, we examine the linearity of Mamba's representations of factual relations. Finally we adapt attention-knockout techniques to Mamba to dissect information flow during factual recall. We compare Mamba directly to a similar-sized transformer and conclude that despite significant differences in architectural approach, when it comes to factual recall, the two architectures share many similarities.
Algorithmic progress in language models
Mar 09, 2024
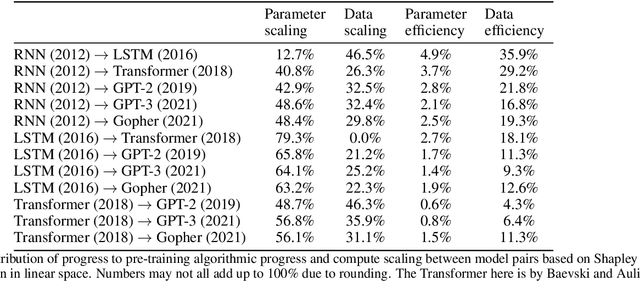

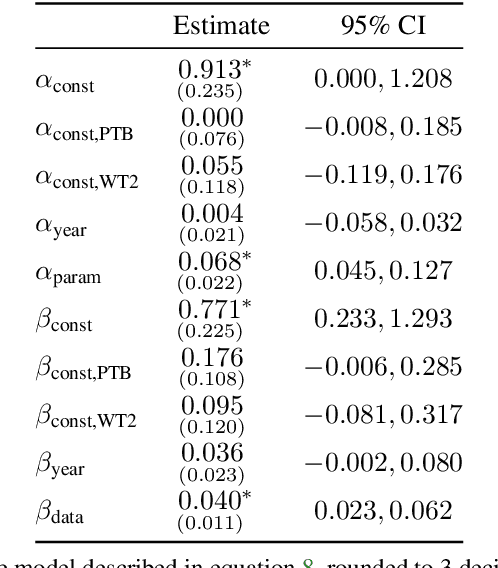
We investigate the rate at which algorithms for pre-training language models have improved since the advent of deep learning. Using a dataset of over 200 language model evaluations on Wikitext and Penn Treebank spanning 2012-2023, we find that the compute required to reach a set performance threshold has halved approximately every 8 months, with a 95% confidence interval of around 5 to 14 months, substantially faster than hardware gains per Moore's Law. We estimate augmented scaling laws, which enable us to quantify algorithmic progress and determine the relative contributions of scaling models versus innovations in training algorithms. Despite the rapid pace of algorithmic progress and the development of new architectures such as the transformer, our analysis reveals that the increase in compute made an even larger contribution to overall performance improvements over this time period. Though limited by noisy benchmark data, our analysis quantifies the rapid progress in language modeling, shedding light on the relative contributions from compute and algorithms.