 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRubrics as an Attack Surface: Stealthy Preference Drift in LLM Judges
Feb 14, 2026Evaluation and alignment pipelines for large language models increasingly rely on LLM-based judges, whose behavior is guided by natural-language rubrics and validated on benchmarks. We identify a previously under-recognized vulnerability in this workflow, which we term Rubric-Induced Preference Drift (RIPD). Even when rubric edits pass benchmark validation, they can still produce systematic and directional shifts in a judge's preferences on target domains. Because rubrics serve as a high-level decision interface, such drift can emerge from seemingly natural, criterion-preserving edits and remain difficult to detect through aggregate benchmark metrics or limited spot-checking. We further show this vulnerability can be exploited through rubric-based preference attacks, in which benchmark-compliant rubric edits steer judgments away from a fixed human or trusted reference on target domains, systematically inducing RIPD and reducing target-domain accuracy up to 9.5% (helpfulness) and 27.9% (harmlessness). When these judgments are used to generate preference labels for downstream post-training, the induced bias propagates through alignment pipelines and becomes internalized in trained policies. This leads to persistent and systematic drift in model behavior. Overall, our findings highlight evaluation rubrics as a sensitive and manipulable control interface, revealing a system-level alignment risk that extends beyond evaluator reliability alone. The code is available at: https://github.com/ZDCSlab/Rubrics-as-an-Attack-Surface. Warning: Certain sections may contain potentially harmful content that may not be appropriate for all readers.
EvalTree: Profiling Language Model Weaknesses via Hierarchical Capability Trees
Mar 11, 2025An ideal model evaluation should achieve two goals: identifying where the model fails and providing actionable improvement guidance. Toward these goals for Language Model (LM) evaluations, we formulate the problem of generating a weakness profile, a set of weaknesses expressed in natural language, given an LM's performance on every individual instance in a benchmark. We introduce a suite of quantitative assessments to compare different weakness profiling methods. We also propose a weakness profiling method EvalTree. It constructs a capability tree where each node represents a capability described in natural language and is linked to a subset of benchmark instances that specifically evaluate this capability; it then extracts nodes where the LM performs poorly to generate a weakness profile. On the MATH and WildChat benchmarks, we show that EvalTree outperforms baseline weakness profiling methods by identifying weaknesses more precisely and comprehensively. Weakness profiling further enables weakness-guided data collection, and training data collection guided by EvalTree-identified weaknesses improves LM performance more than other data collection strategies. We also show how EvalTree exposes flaws in Chatbot Arena's human-voter-based evaluation practice. To facilitate future work, we release our code and an interface that allows practitioners to interactively explore the capability trees built by EvalTree.
HREF: Human Response-Guided Evaluation of Instruction Following in Language Models
Dec 20, 2024Evaluating the capability of Large Language Models (LLMs) in following instructions has heavily relied on a powerful LLM as the judge, introducing unresolved biases that deviate the judgments from human judges. In this work, we reevaluate various choices for automatic evaluation on a wide range of instruction-following tasks. We experiment with methods that leverage human-written responses and observe that they enhance the reliability of automatic evaluations across a wide range of tasks, resulting in up to a 3.2% improvement in agreement with human judges. We also discovered that human-written responses offer an orthogonal perspective to model-generated responses in following instructions and should be used as an additional context when comparing model responses. Based on these observations, we develop a new evaluation benchmark, Human Response-Guided Evaluation of Instruction Following (HREF), comprising 4,258 samples across 11 task categories with a composite evaluation setup, employing a composite evaluation setup that selects the most reliable method for each category. In addition to providing reliable evaluation, HREF emphasizes individual task performance and is free from contamination. Finally, we study the impact of key design choices in HREF, including the size of the evaluation set, the judge model, the baseline model, and the prompt template. We host a live leaderboard that evaluates LLMs on the private evaluation set of HREF.
Evaluating Language Models as Synthetic Data Generators
Dec 04, 2024



Given the increasing use of synthetic data in language model (LM) post-training, an LM's ability to generate high-quality data has become nearly as crucial as its ability to solve problems directly. While prior works have focused on developing effective data generation methods, they lack systematic comparison of different LMs as data generators in a unified setting. To address this gap, we propose AgoraBench, a benchmark that provides standardized settings and metrics to evaluate LMs' data generation abilities. Through synthesizing 1.26 million training instances using 6 LMs and training 99 student models, we uncover key insights about LMs' data generation capabilities. First, we observe that LMs exhibit distinct strengths. For instance, GPT-4o excels at generating new problems, while Claude-3.5-Sonnet performs better at enhancing existing ones. Furthermore, our analysis reveals that an LM's data generation ability doesn't necessarily correlate with its problem-solving ability. Instead, multiple intrinsic features of data quality-including response quality, perplexity, and instruction difficulty-collectively serve as better indicators. Finally, we demonstrate that strategic choices in output format and cost-conscious model selection significantly impact data generation effectiveness.
TÜLU 3: Pushing Frontiers in Open Language Model Post-Training
Nov 22, 2024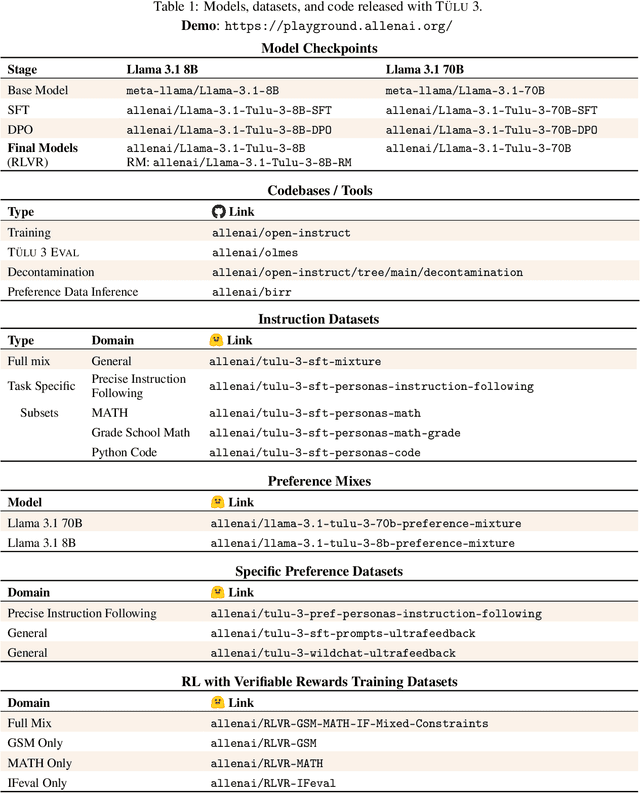



Language model post-training is applied to refine behaviors and unlock new skills across a wide range of recent language models, but open recipes for applying these techniques lag behind proprietary ones. The underlying training data and recipes for post-training are simultaneously the most important pieces of the puzzle and the portion with the least transparency. To bridge this gap, we introduce T\"ULU 3, a family of fully-open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques. T\"ULU 3, which builds on Llama 3.1 base models, achieves results surpassing the instruct versions of Llama 3.1, Qwen 2.5, Mistral, and even closed models such as GPT-4o-mini and Claude 3.5-Haiku. The training algorithms for our models include supervised finetuning (SFT), Direct Preference Optimization (DPO), and a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR). With T\"ULU 3, we introduce a multi-task evaluation scheme for post-training recipes with development and unseen evaluations, standard benchmark implementations, and substantial decontamination of existing open datasets on said benchmarks. We conclude with analysis and discussion of training methods that did not reliably improve performance. In addition to the T\"ULU 3 model weights and demo, we release the complete recipe -- including datasets for diverse core skills, a robust toolkit for data curation and evaluation, the training code and infrastructure, and, most importantly, a detailed report for reproducing and further adapting the T\"ULU 3 approach to more domains.
Hybrid Preferences: Learning to Route Instances for Human vs. AI Feedback
Oct 24, 2024



Learning from human feedback has enabled the alignment of language models (LMs) with human preferences. However, directly collecting human preferences can be expensive, time-consuming, and can have high variance. An appealing alternative is to distill preferences from LMs as a source of synthetic annotations as they are more consistent, cheaper, and scale better than human annotation; however, they are also prone to biases and errors. In this work, we introduce a routing framework that combines inputs from humans and LMs to achieve better annotation quality, while reducing the total cost of human annotation. The crux of our approach is to identify preference instances that will benefit from human annotations. We formulate this as an optimization problem: given a preference dataset and an evaluation metric, we train a performance prediction model to predict a reward model's performance on an arbitrary combination of human and LM annotations and employ a routing strategy that selects a combination that maximizes predicted performance. We train the performance prediction model on MultiPref, a new preference dataset with 10K instances paired with human and LM labels. We show that the selected hybrid mixture of LM and direct human preferences using our routing framework achieves better reward model performance compared to using either one exclusively. We simulate selective human preference collection on three other datasets and show that our method generalizes well to all three. We analyze features from the routing model to identify characteristics of instances that can benefit from human feedback, e.g., prompts with a moderate safety concern or moderate intent complexity. We release the dataset, annotation platform, and source code used in this study to foster more efficient and accurate preference collection in the future.
Unpacking DPO and PPO: Disentangling Best Practices for Learning from Preference Feedback
Jun 13, 2024Learning from preference feedback has emerged as an essential step for improving the generation quality and performance of modern language models (LMs). Despite its widespread use, the way preference-based learning is applied varies wildly, with differing data, learning algorithms, and evaluations used, making disentangling the impact of each aspect difficult. In this work, we identify four core aspects of preference-based learning: preference data, learning algorithm, reward model, and policy training prompts, systematically investigate the impact of these components on downstream model performance, and suggest a recipe for strong learning for preference feedback. Our findings indicate that all aspects are important for performance, with better preference data leading to the largest improvements, followed by the choice of learning algorithm, the use of improved reward models, and finally the use of additional unlabeled prompts for policy training. Notably, PPO outperforms DPO by up to 2.5% in math and 1.2% in general domains. High-quality preference data leads to improvements of up to 8% in instruction following and truthfulness. Despite significant gains of up to 5% in mathematical evaluation when scaling up reward models, we surprisingly observe marginal improvements in other categories. We publicly release the code used for training (https://github.com/hamishivi/EasyLM) and evaluating (https://github.com/allenai/open-instruct) our models, along with the models and datasets themselves (https://huggingface.co/collections/allenai/tulu-v25-suite-66676520fd578080e126f618).
Long Context Alignment with Short Instructions and Synthesized Positions
May 07, 2024



Effectively handling instructions with extremely long context remains a challenge for Large Language Models (LLMs), typically necessitating high-quality long data and substantial computational resources. This paper introduces Step-Skipping Alignment (SkipAlign), a new technique designed to enhance the long-context capabilities of LLMs in the phase of alignment without the need for additional efforts beyond training with original data length. SkipAlign is developed on the premise that long-range dependencies are fundamental to enhancing an LLM's capacity of long context. Departing from merely expanding the length of input samples, SkipAlign synthesizes long-range dependencies from the aspect of positions indices. This is achieved by the strategic insertion of skipped positions within instruction-following samples, which utilizes the semantic structure of the data to effectively expand the context. Through extensive experiments on base models with a variety of context window sizes, SkipAlign demonstrates its effectiveness across a spectrum of long-context tasks. Particularly noteworthy is that with a careful selection of the base model and alignment datasets, SkipAlign with only 6B parameters achieves it's best performance and comparable with strong baselines like GPT-3.5-Turbo-16K on LongBench.
Retrieval Head Mechanistically Explains Long-Context Factuality
Apr 24, 2024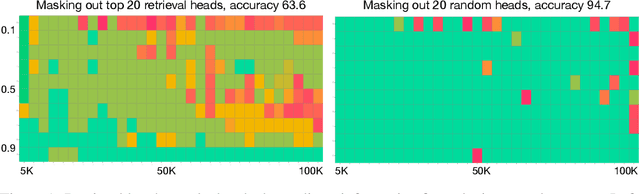
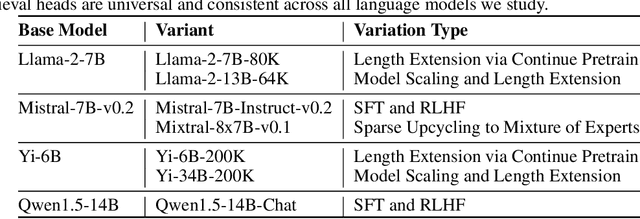

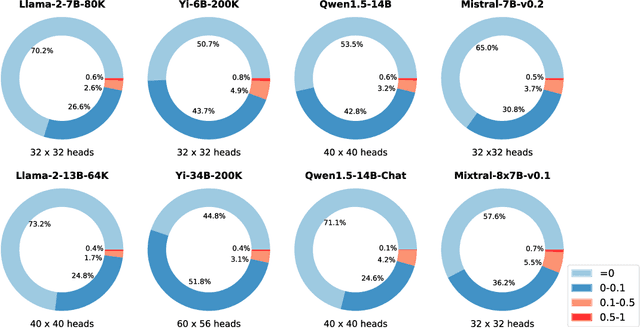
Despite the recent progress in long-context language models, it remains elusive how transformer-based models exhibit the capability to retrieve relevant information from arbitrary locations within the long context. This paper aims to address this question. Our systematic investigation across a wide spectrum of models reveals that a special type of attention heads are largely responsible for retrieving information, which we dub retrieval heads. We identify intriguing properties of retrieval heads:(1) universal: all the explored models with long-context capability have a set of retrieval heads; (2) sparse: only a small portion (less than 5\%) of the attention heads are retrieval. (3) intrinsic: retrieval heads already exist in models pretrained with short context. When extending the context length by continual pretraining, it is still the same set of heads that perform information retrieval. (4) dynamically activated: take Llama-2 7B for example, 12 retrieval heads always attend to the required information no matter how the context is changed. The rest of the retrieval heads are activated in different contexts. (5) causal: completely pruning retrieval heads leads to failure in retrieving relevant information and results in hallucination, while pruning random non-retrieval heads does not affect the model's retrieval ability. We further show that retrieval heads strongly influence chain-of-thought (CoT) reasoning, where the model needs to frequently refer back the question and previously-generated context. Conversely, tasks where the model directly generates the answer using its intrinsic knowledge are less impacted by masking out retrieval heads. These observations collectively explain which internal part of the model seeks information from the input tokens. We believe our insights will foster future research on reducing hallucination, improving reasoning, and compressing the KV cache.
Tur[k]ingBench: A Challenge Benchmark for Web Agents
Mar 21, 2024Recent chatbots have demonstrated impressive ability to understand and communicate in raw-text form. However, there is more to the world than raw text. For example, humans spend long hours of their time on web pages, where text is intertwined with other modalities and tasks are accomplished in the form of various complex interactions. Can state-of-the-art multi-modal models generalize to such complex domains? To address this question, we introduce TurkingBench, a benchmark of tasks formulated as web pages containing textual instructions with multi-modal context. Unlike existing work which employs artificially synthesized web pages, here we use natural HTML pages that were originally designed for crowdsourcing workers for various annotation purposes. The HTML instructions of each task are also instantiated with various values (obtained from the crowdsourcing tasks) to form new instances of the task. This benchmark contains 32.2K instances distributed across 158 tasks. Additionally, to facilitate the evaluation on TurkingBench, we develop an evaluation framework that connects the responses of chatbots to modifications on web pages (modifying a text box, checking a radio, etc.). We evaluate the performance of state-of-the-art models, including language-only, vision-only, and layout-only models, and their combinations, on this benchmark. Our findings reveal that these models perform significantly better than random chance, yet considerable room exists for improvement. We hope this benchmark will help facilitate the evaluation and development of web-based agents.