 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Past Is Not Past: Memory-Enhanced Dynamic Reward Shaping
Apr 13, 2026Despite the success of reinforcement learning for large language models, a common failure mode is reduced sampling diversity, where the policy repeatedly generates similar erroneous behaviors. Classical entropy regularization encourages randomness under the current policy, but does not explicitly discourage recurrent failure patterns across rollouts. We propose MEDS, a Memory-Enhanced Dynamic reward Shaping framework that incorporates historical behavioral signals into reward design. By storing and leveraging intermediate model representations, we capture features of past rollouts and use density-based clustering to identify frequently recurring error patterns. Rollouts assigned to more prevalent error clusters are penalized more heavily, encouraging broader exploration while reducing repeated mistakes. Across five datasets and three base models, MEDS consistently improves average performance over existing baselines, achieving gains of up to 4.13 pass@1 points and 4.37 pass@128 points. Additional analyses using both LLM-based annotations and quantitative diversity metrics show that MEDS increases behavioral diversity during sampling.
FutureX-Pro: Extending Future Prediction to High-Value Vertical Domains
Jan 18, 2026Building upon FutureX, which established a live benchmark for general-purpose future prediction, this report introduces FutureX-Pro, including FutureX-Finance, FutureX-Retail, FutureX-PublicHealth, FutureX-NaturalDisaster, and FutureX-Search. These together form a specialized framework extending agentic future prediction to high-value vertical domains. While generalist agents demonstrate proficiency in open-domain search, their reliability in capital-intensive and safety-critical sectors remains under-explored. FutureX-Pro targets four economically and socially pivotal verticals: Finance, Retail, Public Health, and Natural Disaster. We benchmark agentic Large Language Models (LLMs) on entry-level yet foundational prediction tasks -- ranging from forecasting market indicators and supply chain demands to tracking epidemic trends and natural disasters. By adapting the contamination-free, live-evaluation pipeline of FutureX, we assess whether current State-of-the-Art (SOTA) agentic LLMs possess the domain grounding necessary for industrial deployment. Our findings reveal the performance gap between generalist reasoning and the precision required for high-value vertical applications.
Dynamic Large Concept Models: Latent Reasoning in an Adaptive Semantic Space
Dec 31, 2025Large Language Models (LLMs) apply uniform computation to all tokens, despite language exhibiting highly non-uniform information density. This token-uniform regime wastes capacity on locally predictable spans while under-allocating computation to semantically critical transitions. We propose $\textbf{Dynamic Large Concept Models (DLCM)}$, a hierarchical language modeling framework that learns semantic boundaries from latent representations and shifts computation from tokens to a compressed concept space where reasoning is more efficient. DLCM discovers variable-length concepts end-to-end without relying on predefined linguistic units. Hierarchical compression fundamentally changes scaling behavior. We introduce the first $\textbf{compression-aware scaling law}$, which disentangles token-level capacity, concept-level reasoning capacity, and compression ratio, enabling principled compute allocation under fixed FLOPs. To stably train this heterogeneous architecture, we further develop a $\textbf{decoupled $μ$P parametrization}$ that supports zero-shot hyperparameter transfer across widths and compression regimes. At a practical setting ($R=4$, corresponding to an average of four tokens per concept), DLCM reallocates roughly one-third of inference compute into a higher-capacity reasoning backbone, achieving a $\textbf{+2.69$\%$ average improvement}$ across 12 zero-shot benchmarks under matched inference FLOPs.
Mitigating LLM Hallucination via Behaviorally Calibrated Reinforcement Learning
Dec 22, 2025LLM deployment in critical domains is currently impeded by persistent hallucinations--generating plausible but factually incorrect assertions. While scaling laws drove significant improvements in general capabilities, theoretical frameworks suggest hallucination is not merely stochastic error but a predictable statistical consequence of training objectives prioritizing mimicking data distribution over epistemic honesty. Standard RLVR paradigms, utilizing binary reward signals, inadvertently incentivize models as good test-takers rather than honest communicators, encouraging guessing whenever correctness probability exceeds zero. This paper presents an exhaustive investigation into behavioral calibration, which incentivizes models to stochastically admit uncertainty by abstaining when not confident, aligning model behavior with accuracy. Synthesizing recent advances, we propose and evaluate training interventions optimizing strictly proper scoring rules for models to output a calibrated probability of correctness. Our methods enable models to either abstain from producing a complete response or flag individual claims where uncertainty remains. Utilizing Qwen3-4B-Instruct, empirical analysis reveals behavior-calibrated reinforcement learning allows smaller models to surpass frontier models in uncertainty quantification--a transferable meta-skill decouplable from raw predictive accuracy. Trained on math reasoning tasks, our model's log-scale Accuracy-to-Hallucination Ratio gain (0.806) exceeds GPT-5's (0.207) in a challenging in-domain evaluation (BeyondAIME). Moreover, in cross-domain factual QA (SimpleQA), our 4B LLM achieves zero-shot calibration error on par with frontier models including Grok-4 and Gemini-2.5-Pro, even though its factual accuracy is much lower.
Olmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
From Scaling to Structured Expressivity: Rethinking Transformers for CTR Prediction
Nov 15, 2025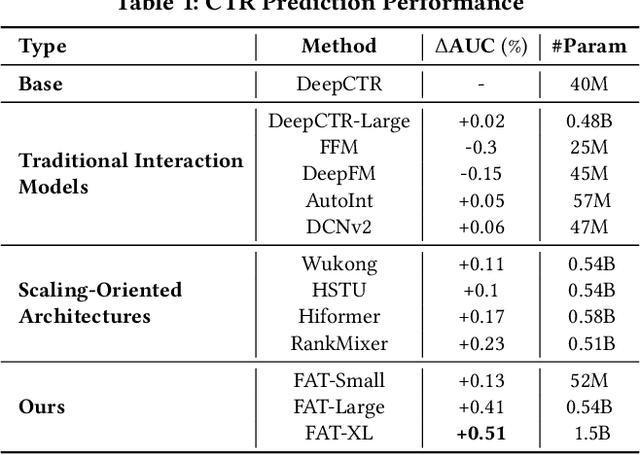


Despite massive investments in scale, deep models for click-through rate (CTR) prediction often exhibit rapidly diminishing returns - a stark contrast to the smooth, predictable gains seen in large language models. We identify the root cause as a structural misalignment: Transformers assume sequential compositionality, while CTR data demand combinatorial reasoning over high-cardinality semantic fields. Unstructured attention spreads capacity indiscriminately, amplifying noise under extreme sparsity and breaking scalable learning. To restore alignment, we introduce the Field-Aware Transformer (FAT), which embeds field-based interaction priors into attention through decomposed content alignment and cross-field modulation. This design ensures model complexity scales with the number of fields F, not the total vocabulary size n >> F, leading to tighter generalization and, critically, observed power-law scaling in AUC as model width increases. We present the first formal scaling law for CTR models, grounded in Rademacher complexity, that explains and predicts this behavior. On large-scale benchmarks, FAT improves AUC by up to +0.51% over state-of-the-art methods. Deployed online, it delivers +2.33% CTR and +0.66% RPM. Our work establishes that effective scaling in recommendation arises not from size, but from structured expressivity-architectural coherence with data semantics.
RLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments
Nov 10, 2025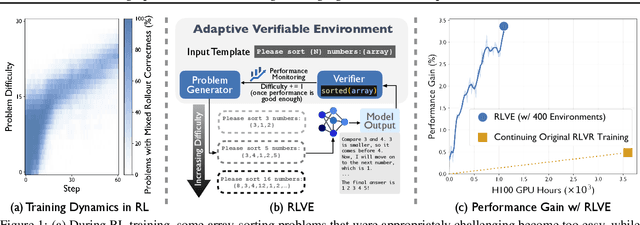

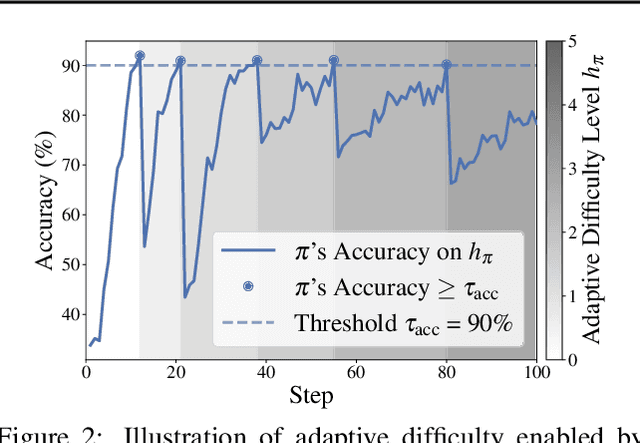
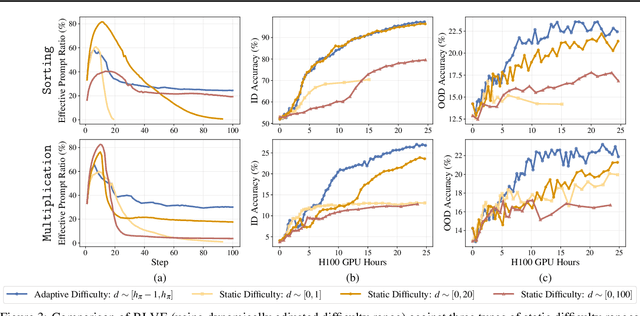
We introduce Reinforcement Learning (RL) with Adaptive Verifiable Environments (RLVE), an approach using verifiable environments that procedurally generate problems and provide algorithmically verifiable rewards, to scale up RL for language models (LMs). RLVE enables each verifiable environment to dynamically adapt its problem difficulty distribution to the policy model's capabilities as training progresses. In contrast, static data distributions often lead to vanishing learning signals when problems are either too easy or too hard for the policy. To implement RLVE, we create RLVE-Gym, a large-scale suite of 400 verifiable environments carefully developed through manual environment engineering. Using RLVE-Gym, we show that environment scaling, i.e., expanding the collection of training environments, consistently improves generalizable reasoning capabilities. RLVE with joint training across all 400 environments in RLVE-Gym yields a 3.37% absolute average improvement across six reasoning benchmarks, starting from one of the strongest 1.5B reasoning LMs. By comparison, continuing this LM's original RL training yields only a 0.49% average absolute gain despite using over 3x more compute. We release our code publicly.
FinSearchComp: Towards a Realistic, Expert-Level Evaluation of Financial Search and Reasoning
Sep 16, 2025



Search has emerged as core infrastructure for LLM-based agents and is widely viewed as critical on the path toward more general intelligence. Finance is a particularly demanding proving ground: analysts routinely conduct complex, multi-step searches over time-sensitive, domain-specific data, making it ideal for assessing both search proficiency and knowledge-grounded reasoning. Yet no existing open financial datasets evaluate data searching capability of end-to-end agents, largely because constructing realistic, complicated tasks requires deep financial expertise and time-sensitive data is hard to evaluate. We present FinSearchComp, the first fully open-source agent benchmark for realistic, open-domain financial search and reasoning. FinSearchComp comprises three tasks -- Time-Sensitive Data Fetching, Simple Historical Lookup, and Complex Historical Investigation -- closely reproduce real-world financial analyst workflows. To ensure difficulty and reliability, we engage 70 professional financial experts for annotation and implement a rigorous multi-stage quality-assurance pipeline. The benchmark includes 635 questions spanning global and Greater China markets, and we evaluate 21 models (products) on it. Grok 4 (web) tops the global subset, approaching expert-level accuracy. DouBao (web) leads on the Greater China subset. Experimental analyses show that equipping agents with web search and financial plugins substantially improves results on FinSearchComp, and the country origin of models and tools impact performance significantly.By aligning with realistic analyst tasks and providing end-to-end evaluation, FinSearchComp offers a professional, high-difficulty testbed for complex financial search and reasoning.
Dynamic and Generalizable Process Reward Modeling
Jul 23, 2025Process Reward Models (PRMs) are crucial for guiding Large Language Models (LLMs) in complex scenarios by providing dense reward signals. However, existing PRMs primarily rely on heuristic approaches, which struggle with cross-domain generalization. While LLM-as-judge has been proposed to provide generalized rewards, current research has focused mainly on feedback results, overlooking the meaningful guidance embedded within the text. Additionally, static and coarse-grained evaluation criteria struggle to adapt to complex process supervision. To tackle these challenges, we propose Dynamic and Generalizable Process Reward Modeling (DG-PRM), which features a reward tree to capture and store fine-grained, multi-dimensional reward criteria. DG-PRM dynamically selects reward signals for step-wise reward scoring. To handle multifaceted reward signals, we pioneeringly adopt Pareto dominance estimation to identify discriminative positive and negative pairs. Experimental results show that DG-PRM achieves stunning performance on prevailing benchmarks, significantly boosting model performance across tasks with dense rewards. Further analysis reveals that DG-PRM adapts well to out-of-distribution scenarios, demonstrating exceptional generalizability.
Precise Information Control in Long-Form Text Generation
Jun 06, 2025A central challenge in modern language models (LMs) is intrinsic hallucination: the generation of information that is plausible but unsubstantiated relative to input context. To study this problem, we propose Precise Information Control (PIC), a new task formulation that requires models to generate long-form outputs grounded in a provided set of short self-contained statements, known as verifiable claims, without adding any unsupported ones. For comprehensiveness, PIC includes a full setting that tests a model's ability to include exactly all input claims, and a partial setting that requires the model to selectively incorporate only relevant claims. We present PIC-Bench, a benchmark of eight long-form generation tasks (e.g., summarization, biography generation) adapted to the PIC setting, where LMs are supplied with well-formed, verifiable input claims. Our evaluation of a range of open and proprietary LMs on PIC-Bench reveals that, surprisingly, state-of-the-art LMs still intrinsically hallucinate in over 70% of outputs. To alleviate this lack of faithfulness, we introduce a post-training framework, using a weakly supervised preference data construction method, to train an 8B PIC-LM with stronger PIC ability--improving from 69.1% to 91.0% F1 in the full PIC setting. When integrated into end-to-end factual generation pipelines, PIC-LM improves exact match recall by 17.1% on ambiguous QA with retrieval, and factual precision by 30.5% on a birthplace verification task, underscoring the potential of precisely grounded generation.