 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhich Reasoning Trajectories Teach Students to Reason Better? A Simple Metric of Informative Alignment
Jan 20, 2026Long chain-of-thought (CoT) trajectories provide rich supervision signals for distilling reasoning from teacher to student LLMs. However, both prior work and our experiments show that trajectories from stronger teachers do not necessarily yield better students, highlighting the importance of data-student suitability in distillation. Existing methods assess suitability primarily through student likelihood, favoring trajectories that closely align with the model's current behavior but overlooking more informative ones. Addressing this, we propose Rank-Surprisal Ratio (RSR), a simple metric that captures both alignment and informativeness to assess the suitability of a reasoning trajectory. RSR is motivated by the observation that effective trajectories typically combine low absolute probability with relatively high-ranked tokens under the student model, balancing learning signal strength and behavioral alignment. Concretely, RSR is defined as the ratio of a trajectory's average token-wise rank to its average negative log-likelihood, and is straightforward to compute and interpret. Across five student models and reasoning trajectories from 11 diverse teachers, RSR strongly correlates with post-training performance (average Spearman 0.86), outperforming existing metrics. We further demonstrate its practical utility in both trajectory selection and teacher selection.
What are the Essential Factors in Crafting Effective Long Context Multi-Hop Instruction Datasets? Insights and Best Practices
Sep 03, 2024



Recent advancements in large language models (LLMs) with extended context windows have significantly improved tasks such as information extraction, question answering, and complex planning scenarios. In order to achieve success in long context tasks, a large amount of work has been done to enhance the long context capabilities of the model through synthetic data. Existing methods typically utilize the Self-Instruct framework to generate instruction tuning data for better long context capability improvement. However, our preliminary experiments indicate that less than 35% of generated samples are multi-hop, and more than 40% exhibit poor quality, limiting comprehensive understanding and further research. To improve the quality of synthetic data, we propose the Multi-agent Interactive Multi-hop Generation (MIMG) framework, incorporating a Quality Verification Agent, a Single-hop Question Generation Agent, a Multiple Question Sampling Strategy, and a Multi-hop Question Merger Agent. This framework improves the data quality, with the proportion of high-quality, multi-hop, and diverse data exceeding 85%. Furthermore, we systematically investigate strategies for document selection, question merging, and validation techniques through extensive experiments across various models. Our findings show that our synthetic high-quality long-context instruction data significantly enhances model performance, even surpassing models trained on larger amounts of human-annotated data. Our code is available at: https://github.com/WowCZ/LongMIT.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
WanJuan-CC: A Safe and High-Quality Open-sourced English Webtext Dataset
Mar 12, 2024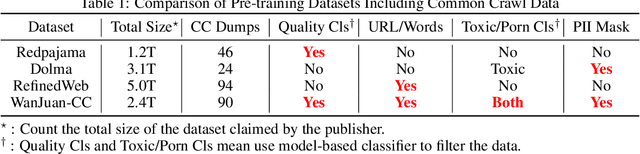
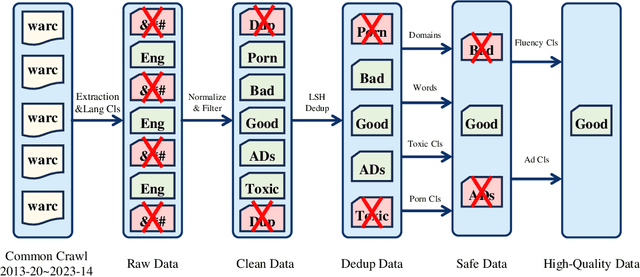
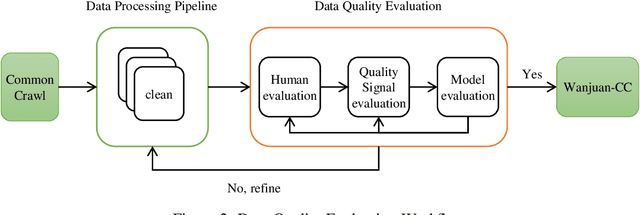

This paper presents WanJuan-CC, a safe and high-quality open-sourced English webtext dataset derived from Common Crawl data. The study addresses the challenges of constructing large-scale pre-training datasets for language models, which require vast amounts of high-quality data. A comprehensive process was designed to handle Common Crawl data, including extraction, heuristic rule filtering, fuzzy deduplication, content safety filtering, and data quality filtering. From approximately 68 billion original English documents, we obtained 2.22T Tokens of safe data and selected 1.0T Tokens of high-quality data as part of WanJuan-CC. We have open-sourced 100B Tokens from this dataset. The paper also provides statistical information related to data quality, enabling users to select appropriate data according to their needs. To evaluate the quality and utility of the dataset, we trained 1B-parameter and 3B-parameter models using WanJuan-CC and another dataset, RefinedWeb. Results show that WanJuan-CC performs better on validation datasets and downstream tasks.
AdaLomo: Low-memory Optimization with Adaptive Learning Rate
Oct 22, 2023
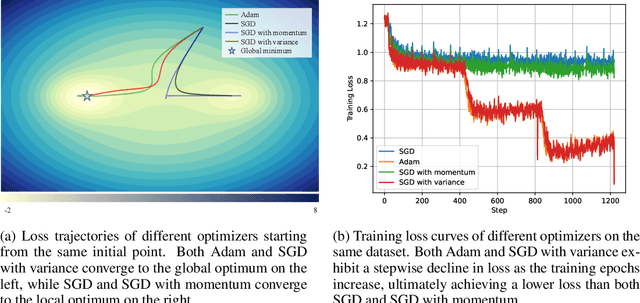


Large language models have achieved remarkable success, but their extensive parameter size necessitates substantial memory for training, thereby setting a high threshold. While the recently proposed low-memory optimization (LOMO) reduces memory footprint, its optimization technique, akin to stochastic gradient descent, is sensitive to hyper-parameters and exhibits suboptimal convergence, failing to match the performance of the prevailing optimizer for large language models, AdamW. Through empirical analysis of the Adam optimizer, we found that, compared to momentum, the adaptive learning rate is more critical for bridging the gap. Building on this insight, we introduce the low-memory optimization with adaptive learning rate (AdaLomo), which offers an adaptive learning rate for each parameter. To maintain memory efficiency, we employ non-negative matrix factorization for the second-order moment estimation in the optimizer state. Additionally, we suggest the use of a grouped update normalization to stabilize convergence. Our experiments with instruction-tuning and further pre-training demonstrate that AdaLomo achieves results on par with AdamW, while significantly reducing memory requirements, thereby lowering the hardware barrier to training large language models.
Discussion of Ensemble Learning under the Era of Deep Learning
Jan 21, 2021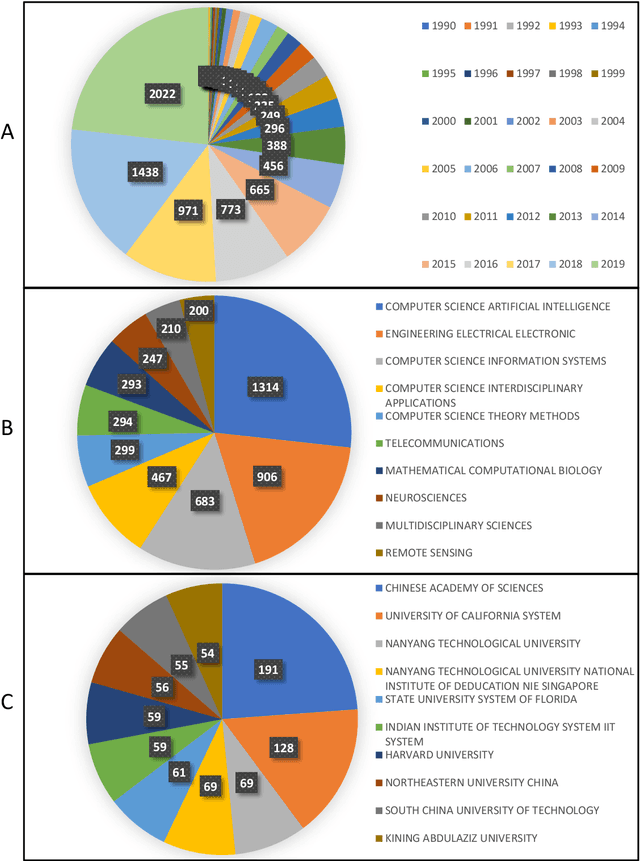
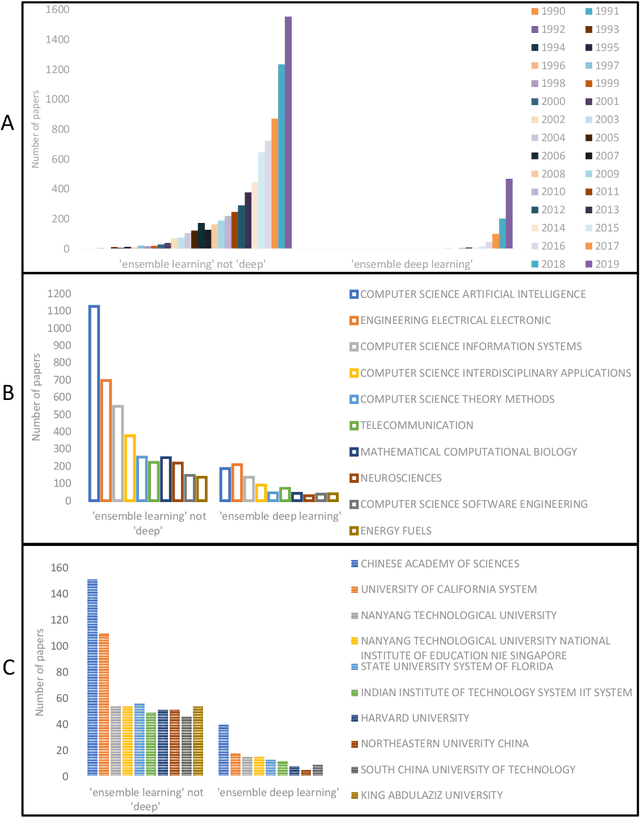
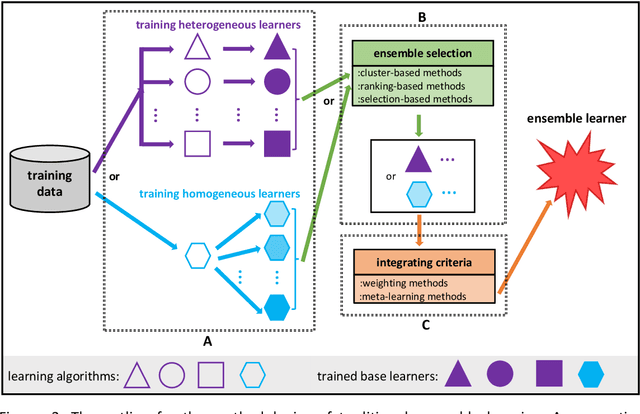
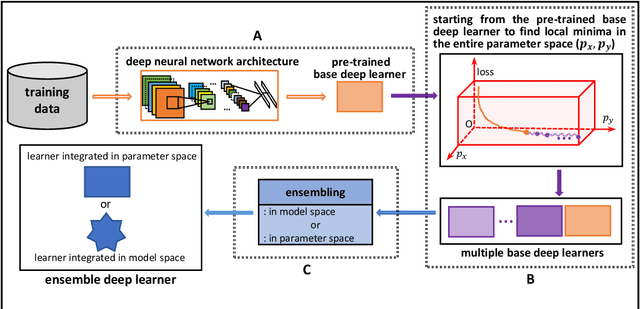
Due to the dominant position of deep learning (mostly deep neural networks) in various artificial intelligence applications, recently, ensemble learning based on deep neural networks (ensemble deep learning) has shown significant performances in improving the generalization of learning system. However, since modern deep neural networks usually have millions to billions of parameters, the time and space overheads for training multiple base deep learners and testing with the ensemble deep learner are far greater than that of traditional ensemble learning. Though several algorithms of fast ensemble deep learning have been proposed to promote the deployment of ensemble deep learning in some applications, further advances still need to be made for many applications in specific fields, where the developing time and computing resources are usually restricted or the data to be processed is of large dimensionality. An urgent problem needs to be solved is how to take the significant advantages of ensemble deep learning while reduce the required time and space overheads so that many more applications in specific fields can benefit from it. For the alleviation of this problem, it is necessary to know about how ensemble learning has developed under the era of deep learning. Thus, in this article, we present discussion focusing on data analyses of published works, the methodology and unattainability of traditional ensemble learning, and recent developments of ensemble deep learning. We hope this article will be helpful to realize the technical challenges faced by future developments of ensemble learning under the era of deep learning.