 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSDL: Data Set Description Language for Bridging Modalities and Tasks in AI Data
May 28, 2024In the era of artificial intelligence, the diversity of data modalities and annotation formats often renders data unusable directly, requiring understanding and format conversion before it can be used by researchers or developers with different needs. To tackle this problem, this article introduces a framework called Dataset Description Language (DSDL) that aims to simplify dataset processing by providing a unified standard for AI datasets. DSDL adheres to the three basic practical principles of generic, portable, and extensible, using a unified standard to express data of different modalities and structures, facilitating the dissemination of AI data, and easily extending to new modalities and tasks. The standardized specifications of DSDL reduce the workload for users in data dissemination, processing, and usage. To further improve user convenience, we provide predefined DSDL templates for various tasks, convert mainstream datasets to comply with DSDL specifications, and provide comprehensive documentation and DSDL tools. These efforts aim to simplify the use of AI data, thereby improving the efficiency of AI development.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
WanJuan-CC: A Safe and High-Quality Open-sourced English Webtext Dataset
Mar 12, 2024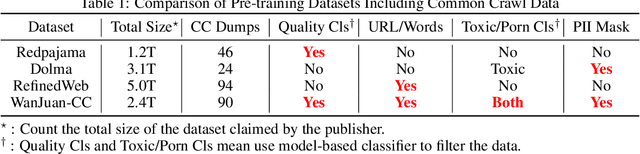
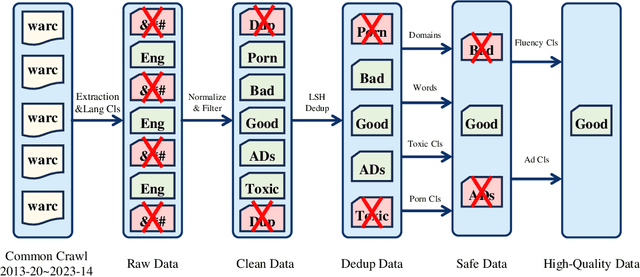
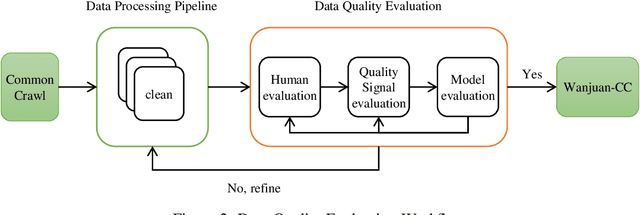

This paper presents WanJuan-CC, a safe and high-quality open-sourced English webtext dataset derived from Common Crawl data. The study addresses the challenges of constructing large-scale pre-training datasets for language models, which require vast amounts of high-quality data. A comprehensive process was designed to handle Common Crawl data, including extraction, heuristic rule filtering, fuzzy deduplication, content safety filtering, and data quality filtering. From approximately 68 billion original English documents, we obtained 2.22T Tokens of safe data and selected 1.0T Tokens of high-quality data as part of WanJuan-CC. We have open-sourced 100B Tokens from this dataset. The paper also provides statistical information related to data quality, enabling users to select appropriate data according to their needs. To evaluate the quality and utility of the dataset, we trained 1B-parameter and 3B-parameter models using WanJuan-CC and another dataset, RefinedWeb. Results show that WanJuan-CC performs better on validation datasets and downstream tasks.