 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMousse: Rectifying the Geometry of Muon with Curvature-Aware Preconditioning
Mar 10, 2026Recent advances in spectral optimization, notably Muon, have demonstrated that constraining update steps to the Stiefel manifold can significantly accelerate training and improve generalization. However, Muon implicitly assumes an isotropic optimization landscape, enforcing a uniform spectral update norm across all eigen-directions. We argue that this "egalitarian" constraint is suboptimal for Deep Neural Networks, where the curvature spectrum is known to be highly heavy-tailed and ill-conditioned. In such landscapes, Muon risks amplifying instabilities in high-curvature directions while limiting necessary progress in flat directions. In this work, we propose \textbf{Mousse} (\textbf{M}uon \textbf{O}ptimization \textbf{U}tilizing \textbf{S}hampoo's \textbf{S}tructural \textbf{E}stimation), a novel optimizer that reconciles the structural stability of spectral methods with the geometric adaptivity of second-order preconditioning. Instead of applying Newton-Schulz orthogonalization directly to the momentum matrix, Mousse operates in a whitened coordinate system induced by Kronecker-factored statistics (derived from Shampoo). Mathematically, we formulate Mousse as the solution to a spectral steepest descent problem constrained by an anisotropic trust region, where the optimal update is derived via the polar decomposition of the whitened gradient. Empirical results across language models ranging from 160M to 800M parameters demonstrate that Mousse consistently outperforms Muon, achieving around $\sim$12\% reduction in training steps with negligible computational overhead.
DRFormer: A Dual-Regularized Bidirectional Transformer for Person Re-identification
Feb 01, 2026Both fine-grained discriminative details and global semantic features can contribute to solving person re-identification challenges, such as occlusion and pose variations. Vision foundation models (\textit{e.g.}, DINO) excel at mining local textures, and vision-language models (\textit{e.g.}, CLIP) capture strong global semantic difference. Existing methods predominantly rely on a single paradigm, neglecting the potential benefits of their integration. In this paper, we analyze the complementary roles of these two architectures and propose a framework to synergize their strengths by a \textbf{D}ual-\textbf{R}egularized Bidirectional \textbf{Transformer} (\textbf{DRFormer}). The dual-regularization mechanism ensures diverse feature extraction and achieves a better balance in the contributions of the two models. Extensive experiments on five benchmarks show that our method effectively harmonizes local and global representations, achieving competitive performance against state-of-the-art methods.
Explicit Multi-head Attention for Inter-head Interaction in Large Language Models
Jan 27, 2026In large language models built upon the Transformer architecture, recent studies have shown that inter-head interaction can enhance attention performance. Motivated by this, we propose Multi-head Explicit Attention (MEA), a simple yet effective attention variant that explicitly models cross-head interaction. MEA consists of two key components: a Head-level Linear Composition (HLC) module that separately applies learnable linear combinations to the key and value vectors across heads, thereby enabling rich inter-head communication; and a head-level Group Normalization layer that aligns the statistical properties of the recombined heads. MEA shows strong robustness in pretraining, which allows the use of larger learning rates that lead to faster convergence, ultimately resulting in lower validation loss and improved performance across a range of tasks. Furthermore, we explore the parameter efficiency of MEA by reducing the number of attention heads and leveraging HLC to reconstruct them using low-rank "virtual heads". This enables a practical key-value cache compression strategy that reduces KV-cache memory usage by 50% with negligible performance loss on knowledge-intensive and scientific reasoning tasks, and only a 3.59% accuracy drop for Olympiad-level mathematical benchmarks.
CritiQ: Mining Data Quality Criteria from Human Preferences
Feb 26, 2025Language model heavily depends on high-quality data for optimal performance. Existing approaches rely on manually designed heuristics, the perplexity of existing models, training classifiers, or careful prompt engineering, which require significant expert experience and human annotation effort while introduce biases. We introduce CritiQ, a novel data selection method that automatically mines criteria from human preferences for data quality with only $\sim$30 human-annotated pairs and performs efficient data selection. The main component, CritiQ Flow, employs a manager agent to evolve quality criteria and worker agents to make pairwise judgments. We build a knowledge base that extracts quality criteria from previous work to boost CritiQ Flow. Compared to perplexity- and classifier- based methods, verbal criteria are more interpretable and possess reusable value. After deriving the criteria, we train the CritiQ Scorer to give quality scores and perform efficient data selection. We demonstrate the effectiveness of our method in the code, math, and logic domains, achieving high accuracy on human-annotated test sets. To validate the quality of the selected data, we continually train Llama 3.1 models and observe improved performance on downstream tasks compared to uniform sampling. Ablation studies validate the benefits of the knowledge base and the reflection process. We analyze how criteria evolve and the effectiveness of majority voting.
FastMCTS: A Simple Sampling Strategy for Data Synthesis
Feb 17, 2025



Synthetic high-quality multi-step reasoning data can significantly enhance the performance of large language models on various tasks. However, most existing methods rely on rejection sampling, which generates trajectories independently and suffers from inefficiency and imbalanced sampling across problems of varying difficulty. In this work, we introduce FastMCTS, an innovative data synthesis strategy inspired by Monte Carlo Tree Search. FastMCTS provides a more efficient sampling method for multi-step reasoning data, offering step-level evaluation signals and promoting balanced sampling across problems of different difficulty levels. Experiments on both English and Chinese reasoning datasets demonstrate that FastMCTS generates over 30\% more correct reasoning paths compared to rejection sampling as the number of generated tokens scales up. Furthermore, under comparable synthetic data budgets, models trained on FastMCTS-generated data outperform those trained on rejection sampling data by 3.9\% across multiple benchmarks. As a lightweight sampling strategy, FastMCTS offers a practical and efficient alternative for synthesizing high-quality reasoning data. Our code will be released soon.
CoDe: Communication Delay-Tolerant Multi-Agent Collaboration via Dual Alignment of Intent and Timeliness
Jan 09, 2025



Communication has been widely employed to enhance multi-agent collaboration. Previous research has typically assumed delay-free communication, a strong assumption that is challenging to meet in practice. However, real-world agents suffer from channel delays, receiving messages sent at different time points, termed {\it{Asynchronous Communication}}, leading to cognitive biases and breakdowns in collaboration. This paper first defines two communication delay settings in MARL and emphasizes their harm to collaboration. To handle the above delays, this paper proposes a novel framework, Communication Delay-tolerant Multi-Agent Collaboration (CoDe). At first, CoDe learns an intent representation as messages through future action inference, reflecting the stable future behavioral trends of the agents. Then, CoDe devises a dual alignment mechanism of intent and timeliness to strengthen the fusion process of asynchronous messages. In this way, agents can extract the long-term intent of others, even from delayed messages, and selectively utilize the most recent messages that are relevant to their intent. Experimental results demonstrate that CoDe outperforms baseline algorithms in three MARL benchmarks without delay and exhibits robustness under fixed and time-varying delays.
Improving Global Parameter-sharing in Physically Heterogeneous Multi-agent Reinforcement Learning with Unified Action Space
Aug 14, 2024



In a multi-agent system (MAS), action semantics indicates the different influences of agents' actions toward other entities, and can be used to divide agents into groups in a physically heterogeneous MAS. Previous multi-agent reinforcement learning (MARL) algorithms apply global parameter-sharing across different types of heterogeneous agents without careful discrimination of different action semantics. This common implementation decreases the cooperation and coordination between agents in complex situations. However, fully independent agent parameters dramatically increase the computational cost and training difficulty. In order to benefit from the usage of different action semantics while also maintaining a proper parameter-sharing structure, we introduce the Unified Action Space (UAS) to fulfill the requirement. The UAS is the union set of all agent actions with different semantics. All agents first calculate their unified representation in the UAS, and then generate their heterogeneous action policies using different available-action-masks. To further improve the training of extra UAS parameters, we introduce a Cross-Group Inverse (CGI) loss to predict other groups' agent policies with the trajectory information. As a universal method for solving the physically heterogeneous MARL problem, we implement the UAS adding to both value-based and policy-based MARL algorithms, and propose two practical algorithms: U-QMIX and U-MAPPO. Experimental results in the SMAC environment prove the effectiveness of both U-QMIX and U-MAPPO compared with several state-of-the-art MARL methods.
Farewell to Length Extrapolation, a Training-Free Infinite Context with Finite Attention Scope
Jul 21, 2024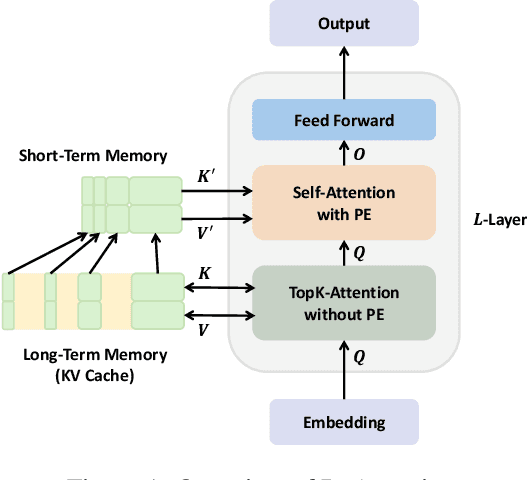

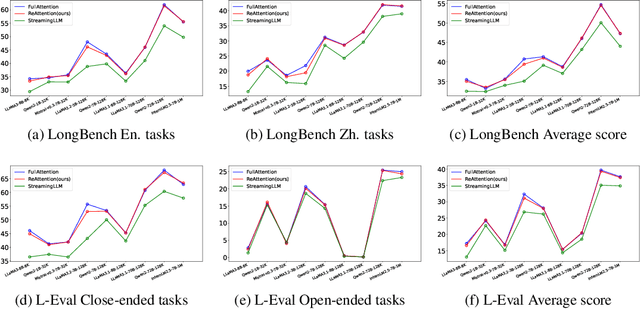
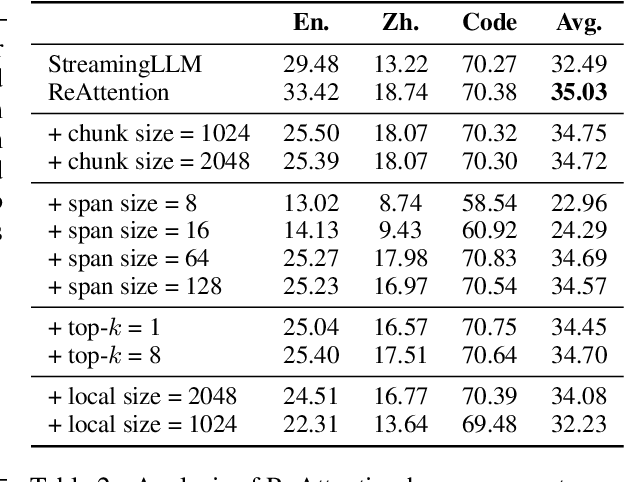
The maximum supported context length is a critical bottleneck limiting the practical application of the Large Language Model (LLM). Although existing length extrapolation methods can extend the context of LLMs to millions of tokens, these methods all have an explicit upper bound. In this work, we propose LongCache, a training-free approach that enables LLM to support an infinite context with finite context scope, through full-context cache selection and training-free integration. This effectively frees LLMs from the length extrapolation issue. We validate LongCache on the LongBench and L-Eval and demonstrate its performance is on par with traditional full-attention mechanisms. Furthermore, we have applied LongCache on mainstream LLMs, including LLaMA3 and Mistral-v0.3, enabling them to support context lengths of at least 400K in Needle-In-A-Haystack tests. We will improve the efficiency of LongCache by GPU-aware optimization soon.
InternLM2 Technical Report
Mar 26, 2024



The evolution of Large Language Models (LLMs) like ChatGPT and GPT-4 has sparked discussions on the advent of Artificial General Intelligence (AGI). However, replicating such advancements in open-source models has been challenging. This paper introduces InternLM2, an open-source LLM that outperforms its predecessors in comprehensive evaluations across 6 dimensions and 30 benchmarks, long-context modeling, and open-ended subjective evaluations through innovative pre-training and optimization techniques. The pre-training process of InternLM2 is meticulously detailed, highlighting the preparation of diverse data types including text, code, and long-context data. InternLM2 efficiently captures long-term dependencies, initially trained on 4k tokens before advancing to 32k tokens in pre-training and fine-tuning stages, exhibiting remarkable performance on the 200k ``Needle-in-a-Haystack" test. InternLM2 is further aligned using Supervised Fine-Tuning (SFT) and a novel Conditional Online Reinforcement Learning from Human Feedback (COOL RLHF) strategy that addresses conflicting human preferences and reward hacking. By releasing InternLM2 models in different training stages and model sizes, we provide the community with insights into the model's evolution.
LongWanjuan: Towards Systematic Measurement for Long Text Quality
Feb 22, 2024The quality of training data are crucial for enhancing the long-text capabilities of foundation models. Despite existing efforts to refine data quality through heuristic rules and evaluations based on data diversity and difficulty, there's a lack of systematic approaches specifically tailored for assessing long texts. Addressing this gap, our work systematically measures the quality of long texts by evaluating three fundamental linguistic dimensions: coherence, cohesion, and complexity. Drawing inspiration from the aforementioned three dimensions, we introduce a suite of metrics designed to evaluate the quality of long texts, encompassing both statistical and pre-trained language model-based ones. Leveraging these metrics, we present LongWanjuan, a bilingual dataset specifically tailored to enhance the training of language models for long-text tasks with over 160B tokens. In LongWanjuan, we categorize long texts into holistic, aggregated, and chaotic types, enabling a detailed analysis of long-text quality. Furthermore, we devise a data mixture recipe that strategically balances different types of long texts within LongWanjuan, leading to significant improvements in model performance on long-text tasks. The code and dataset are available at https://github.com/OpenLMLab/LongWanjuan.