 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFarewell to Length Extrapolation, a Training-Free Infinite Context with Finite Attention Scope
Paper and Code
Jul 21, 2024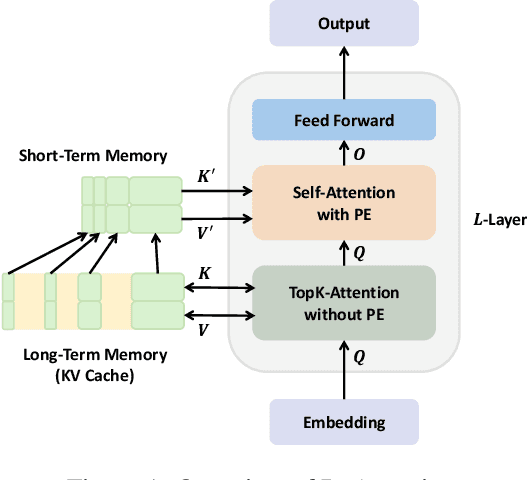

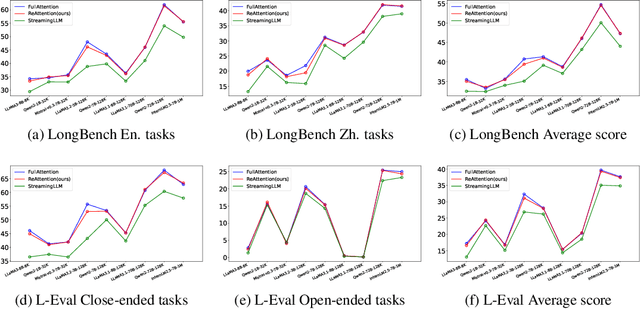
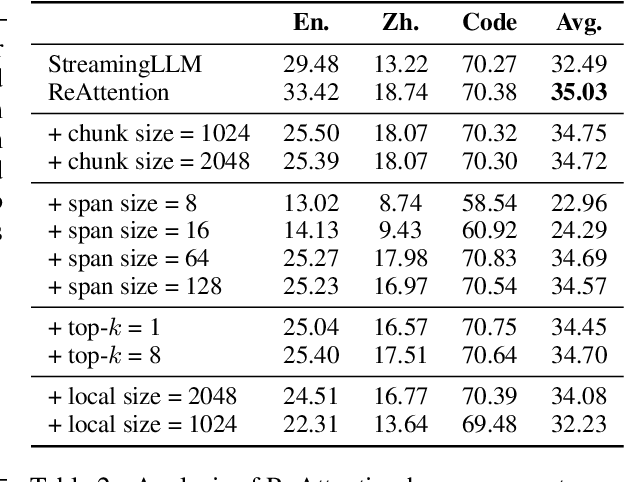
The maximum supported context length is a critical bottleneck limiting the practical application of the Large Language Model (LLM). Although existing length extrapolation methods can extend the context of LLMs to millions of tokens, these methods all have an explicit upper bound. In this work, we propose LongCache, a training-free approach that enables LLM to support an infinite context with finite context scope, through full-context cache selection and training-free integration. This effectively frees LLMs from the length extrapolation issue. We validate LongCache on the LongBench and L-Eval and demonstrate its performance is on par with traditional full-attention mechanisms. Furthermore, we have applied LongCache on mainstream LLMs, including LLaMA3 and Mistral-v0.3, enabling them to support context lengths of at least 400K in Needle-In-A-Haystack tests. We will improve the efficiency of LongCache by GPU-aware optimization soon.