 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystematic validation of time-resolved diffuse optical simulators via non-contact SPAD-based measurements
Nov 17, 2025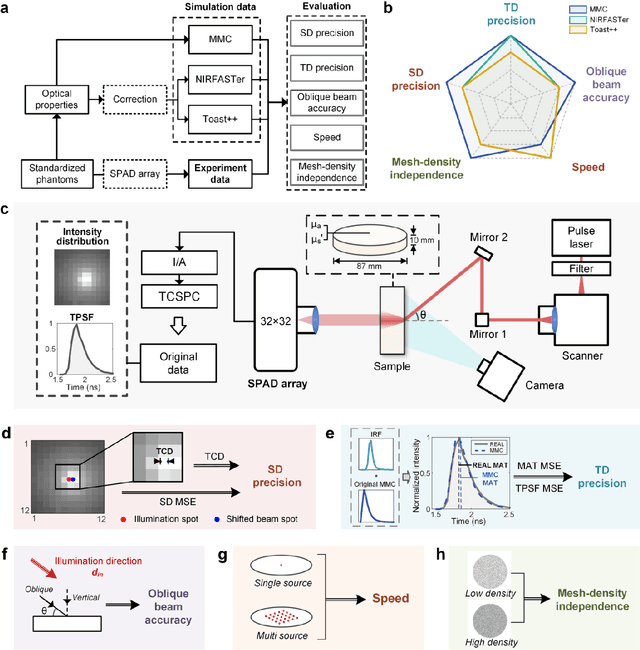
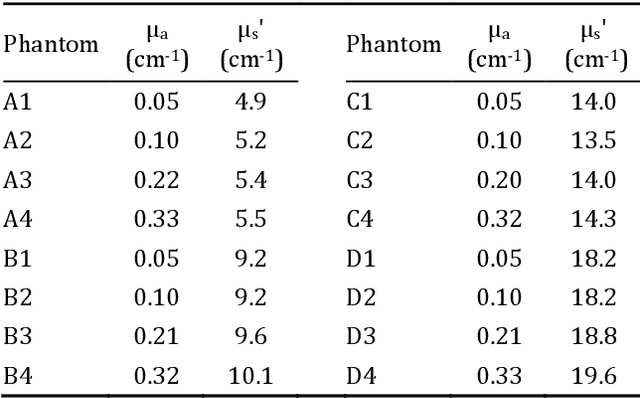
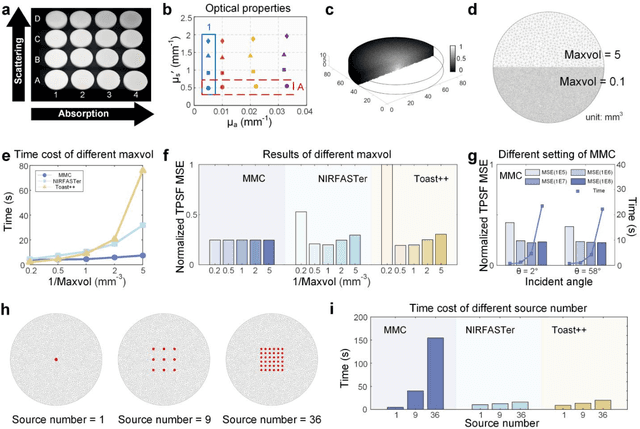
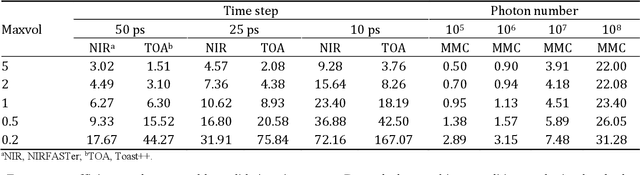
Objective: Time-domain diffuse optical imaging (DOI) requires accurate forward models for photon propagation in scattering media. However, existing simulators lack comprehensive experimental validation, especially for non-contact configurations with oblique illumination. This study rigorously evaluates three widely used open-source simulators, including MMC, NIRFASTer, and Toast++, using time-resolved experimental data. Approach: All simulations employed a unified mesh and point-source illumination. Virtual source correction was applied to FEM solvers for oblique incidence. A time-resolved DOI system with a 32 $\times$ 32 single-photon avalanche diode (SPAD) array acquired transmission-mode data from 16 standardized phantoms with varying absorption coefficient $μ_a$ and reduced scattering coefficient $μ_s'$. The simulation results were quantified across five metrics: spatial-domain (SD) precision, time-domain (TD) precision, oblique beam accuracy, computational speed, and mesh-density independence. Results: Among three simulators, MMC achieves superior accuracy in SD and TD metrics, and shows robustness across all optical properties. NIRFASTer and Toast++ demonstrate comparable overall performance. In general, MMC is optimal for accuracy-critical TD-DOI applications, while NIRFASTer and Toast++ suit scenarios prioritizing speed with sufficiently large $μ_s'$. Besides, virtual source correction is essential for non-contact FEM modeling, which reduced average errors by > 34% in large-angle scenarios. Significance: This work provides benchmarked guidelines for simulator selection during the development phase of next-generation TD-DOI systems. Our work represents the first study to systematically validate TD simulators against SPAD array-based data under clinically relevant non-contact conditions, bridging a critical gap in biomedical optical simulation standards.
$μ$NeuFMT: Optical-Property-Adaptive Fluorescence Molecular Tomography via Implicit Neural Representation
Nov 06, 2025Fluorescence Molecular Tomography (FMT) is a promising technique for non-invasive 3D visualization of fluorescent probes, but its reconstruction remains challenging due to the inherent ill-posedness and reliance on inaccurate or often-unknown tissue optical properties. While deep learning methods have shown promise, their supervised nature limits generalization beyond training data. To address these problems, we propose $\mu$NeuFMT, a self-supervised FMT reconstruction framework that integrates implicit neural-based scene representation with explicit physical modeling of photon propagation. Its key innovation lies in jointly optimize both the fluorescence distribution and the optical properties ($\mu$) during reconstruction, eliminating the need for precise prior knowledge of tissue optics or pre-conditioned training data. We demonstrate that $\mu$NeuFMT robustly recovers accurate fluorophore distributions and optical coefficients even with severely erroneous initial values (0.5$\times$ to 2$\times$ of ground truth). Extensive numerical, phantom, and in vivo validations show that $\mu$NeuFMT outperforms conventional and supervised deep learning approaches across diverse heterogeneous scenarios. Our work establishes a new paradigm for robust and accurate FMT reconstruction, paving the way for more reliable molecular imaging in complex clinically related scenarios, such as fluorescence guided surgery.
Beyond Homogeneous Attention: Memory-Efficient LLMs via Fourier-Approximated KV Cache
Jun 13, 2025Large Language Models struggle with memory demands from the growing Key-Value (KV) cache as context lengths increase. Existing compression methods homogenize head dimensions or rely on attention-guided token pruning, often sacrificing accuracy or introducing computational overhead. We propose FourierAttention, a training-free framework that exploits the heterogeneous roles of transformer head dimensions: lower dimensions prioritize local context, while upper ones capture long-range dependencies. By projecting the long-context-insensitive dimensions onto orthogonal Fourier bases, FourierAttention approximates their temporal evolution with fixed-length spectral coefficients. Evaluations on LLaMA models show that FourierAttention achieves the best long-context accuracy on LongBench and Needle-In-A-Haystack (NIAH). Besides, a custom Triton kernel, FlashFourierAttention, is designed to optimize memory via streamlined read-write operations, enabling efficient deployment without performance compromise.
Thus Spake Long-Context Large Language Model
Feb 24, 2025Long context is an important topic in Natural Language Processing (NLP), running through the development of NLP architectures, and offers immense opportunities for Large Language Models (LLMs) giving LLMs the lifelong learning potential akin to humans. Unfortunately, the pursuit of a long context is accompanied by numerous obstacles. Nevertheless, long context remains a core competitive advantage for LLMs. In the past two years, the context length of LLMs has achieved a breakthrough extension to millions of tokens. Moreover, the research on long-context LLMs has expanded from length extrapolation to a comprehensive focus on architecture, infrastructure, training, and evaluation technologies. Inspired by the symphonic poem, Thus Spake Zarathustra, we draw an analogy between the journey of extending the context of LLM and the attempts of humans to transcend its mortality. In this survey, We will illustrate how LLM struggles between the tremendous need for a longer context and its equal need to accept the fact that it is ultimately finite. To achieve this, we give a global picture of the lifecycle of long-context LLMs from four perspectives: architecture, infrastructure, training, and evaluation, showcasing the full spectrum of long-context technologies. At the end of this survey, we will present 10 unanswered questions currently faced by long-context LLMs. We hope this survey can serve as a systematic introduction to the research on long-context LLMs.
LongSafetyBench: Long-Context LLMs Struggle with Safety Issues
Nov 11, 2024



With the development of large language models (LLMs), the sequence length of these models continues to increase, drawing significant attention to long-context language models. However, the evaluation of these models has been primarily limited to their capabilities, with a lack of research focusing on their safety. Existing work, such as ManyShotJailbreak, has to some extent demonstrated that long-context language models can exhibit safety concerns. However, the methods used are limited and lack comprehensiveness. In response, we introduce \textbf{LongSafetyBench}, the first benchmark designed to objectively and comprehensively evaluate the safety of long-context models. LongSafetyBench consists of 10 task categories, with an average length of 41,889 words. After testing eight long-context language models on LongSafetyBench, we found that existing models generally exhibit insufficient safety capabilities. The proportion of safe responses from most mainstream long-context LLMs is below 50\%. Moreover, models' safety performance in long-context scenarios does not always align with that in short-context scenarios. Further investigation revealed that long-context models tend to overlook harmful content within lengthy texts. We also proposed a simple yet effective solution, allowing open-source models to achieve performance comparable to that of top-tier closed-source models. We believe that LongSafetyBench can serve as a valuable benchmark for evaluating the safety capabilities of long-context language models. We hope that our work will encourage the broader community to pay attention to the safety of long-context models and contribute to the development of solutions to improve the safety of long-context LLMs.
DetectiveQA: Evaluating Long-Context Reasoning on Detective Novels
Sep 04, 2024



With the rapid advancement of Large Language Models (LLMs), long-context information understanding and processing have become a hot topic in academia and industry. However, benchmarks for evaluating the ability of LLMs to handle long-context information do not seem to have kept pace with the development of LLMs. Despite the emergence of various long-context evaluation benchmarks, the types of capability assessed are still limited, without new capability dimensions. In this paper, we introduce DetectiveQA, a narrative reasoning benchmark featured with an average context length of over 100K tokens. DetectiveQA focuses on evaluating the long-context reasoning ability of LLMs, which not only requires a full understanding of context but also requires extracting important evidences from the context and reasoning according to extracted evidences to answer the given questions. This is a new dimension of capability evaluation, which is more in line with the current intelligence level of LLMs. We use detective novels as data sources, which naturally have various reasoning elements. Finally, we manually annotated 600 questions in Chinese and then also provided an English edition of the context information and questions. We evaluate many long-context LLMs on DetectiveQA, including commercial and open-sourced models, and the results indicate that existing long-context LLMs still require significant advancements to effectively process true long-context dependency questions.
Farewell to Length Extrapolation, a Training-Free Infinite Context with Finite Attention Scope
Jul 21, 2024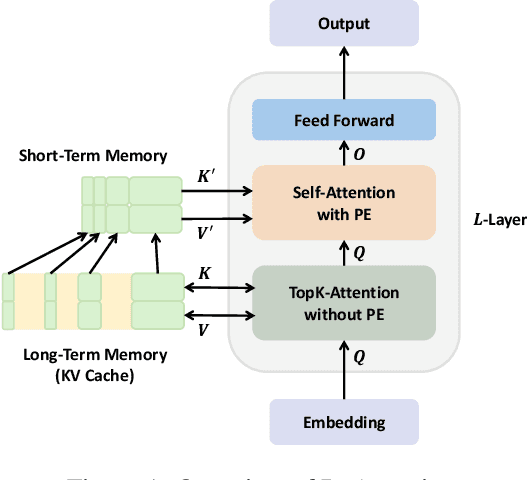

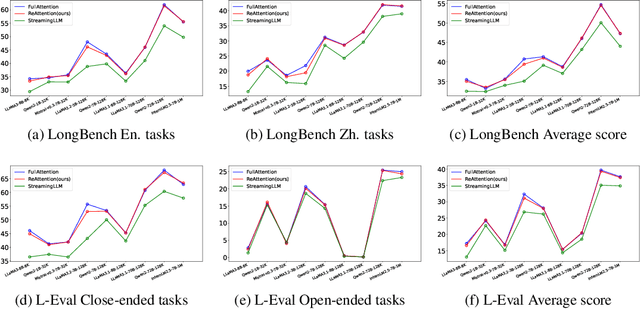
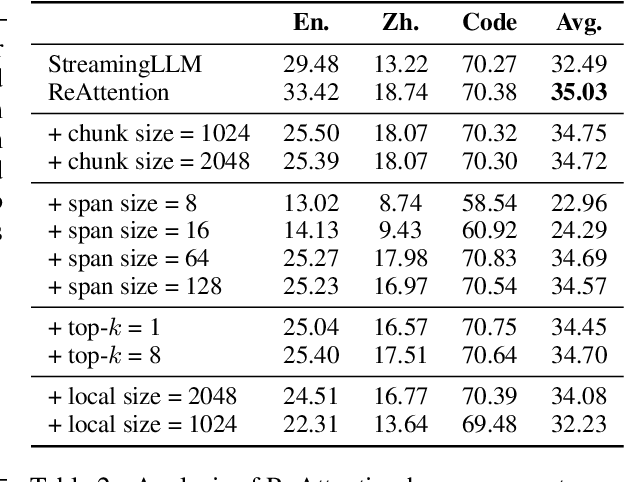
The maximum supported context length is a critical bottleneck limiting the practical application of the Large Language Model (LLM). Although existing length extrapolation methods can extend the context of LLMs to millions of tokens, these methods all have an explicit upper bound. In this work, we propose LongCache, a training-free approach that enables LLM to support an infinite context with finite context scope, through full-context cache selection and training-free integration. This effectively frees LLMs from the length extrapolation issue. We validate LongCache on the LongBench and L-Eval and demonstrate its performance is on par with traditional full-attention mechanisms. Furthermore, we have applied LongCache on mainstream LLMs, including LLaMA3 and Mistral-v0.3, enabling them to support context lengths of at least 400K in Needle-In-A-Haystack tests. We will improve the efficiency of LongCache by GPU-aware optimization soon.
High-resolution tomographic reconstruction of optical absorbance through scattering media using neural fields
Apr 04, 2023



Light scattering imposes a major obstacle for imaging objects seated deeply in turbid media, such as biological tissues and foggy air. Diffuse optical tomography (DOT) tackles scattering by volumetrically recovering the optical absorbance and has shown significance in medical imaging, remote sensing and autonomous driving. A conventional DOT reconstruction paradigm necessitates discretizing the object volume into voxels at a pre-determined resolution for modelling diffuse light propagation and the resulting spatial resolution of the reconstruction is generally limited. We propose NeuDOT, a novel DOT scheme based on neural fields (NF) to continuously encode the optical absorbance within the volume and subsequently bridge the gap between model accuracy and high resolution. Comprehensive experiments demonstrate that NeuDOT achieves submillimetre lateral resolution and resolves complex 3D objects at 14 mm-depth, outperforming the state-of-the-art methods. NeuDOT is a non-invasive, high-resolution and computationally efficient tomographic method, and unlocks further applications of NF involving light scattering.
Efficient Image Captioning for Edge Devices
Dec 18, 2022



Recent years have witnessed the rapid progress of image captioning. However, the demands for large memory storage and heavy computational burden prevent these captioning models from being deployed on mobile devices. The main obstacles lie in the heavyweight visual feature extractors (i.e., object detectors) and complicated cross-modal fusion networks. To this end, we propose LightCap, a lightweight image captioner for resource-limited devices. The core design is built on the recent CLIP model for efficient image captioning. To be specific, on the one hand, we leverage the CLIP model to extract the compact grid features without relying on the time-consuming object detectors. On the other hand, we transfer the image-text retrieval design of CLIP to image captioning scenarios by devising a novel visual concept extractor and a cross-modal modulator. We further optimize the cross-modal fusion model and parallel prediction heads via sequential and ensemble distillations. With the carefully designed architecture, our model merely contains 40M parameters, saving the model size by more than 75% and the FLOPs by more than 98% in comparison with the current state-of-the-art methods. In spite of the low capacity, our model still exhibits state-of-the-art performance on prevalent datasets, e.g., 136.6 CIDEr on COCO Karpathy test split. Testing on the smartphone with only a single CPU, the proposed LightCap exhibits a fast inference speed of 188ms per image, which is ready for practical applications.
Controllable Image Captioning via Prompting
Dec 04, 2022



Despite the remarkable progress of image captioning, existing captioners typically lack the controllable capability to generate desired image captions, e.g., describing the image in a rough or detailed manner, in a factual or emotional view, etc. In this paper, we show that a unified model is qualified to perform well in diverse domains and freely switch among multiple styles. Such a controllable capability is achieved by embedding the prompt learning into the image captioning framework. To be specific, we design a set of prompts to fine-tune the pre-trained image captioner. These prompts allow the model to absorb stylized data from different domains for joint training, without performance degradation in each domain. Furthermore, we optimize the prompts with learnable vectors in the continuous word embedding space, avoiding the heuristic prompt engineering and meanwhile exhibiting superior performance. In the inference stage, our model is able to generate desired stylized captions by choosing the corresponding prompts. Extensive experiments verify the controllable capability of the proposed method. Notably, we achieve outstanding performance on two diverse image captioning benchmarks including COCO Karpathy split and TextCaps using a unified model.